Command Palette
Search for a command to run...
使用评分标准奖励训练AI协作者科学家
使用评分标准奖励训练AI协作者科学家
摘要
人工智能协作科学家正逐渐成为辅助人类研究人员实现科研目标的重要工具。这类AI协作科学家的一个关键能力,是在给定研究目标与约束条件的情况下,生成可行的研究计划。这些计划可为研究人员提供头脑风暴的参考,甚至在进一步优化后直接付诸实施。然而,当前的语言模型在生成研究计划时,仍难以完全满足所有显性与隐性要求。在本研究中,我们探讨如何利用现有科研论文的庞大语料库,训练语言模型以生成更高质量的研究计划。为此,我们通过自动化方法从多个领域的论文中提取研究目标及与之对应的目标特定评分标准,构建了一个可扩展且多样化的训练语料库。随后,我们采用基于自评机制的强化学习方法训练研究计划生成模型:在训练过程中,初始策略的冻结副本充当评分器,而评分标准则创造了“生成器-验证器”之间的差距,从而在无需外部人工监督的情况下实现性能提升。为验证该方法的有效性,我们针对机器学习领域的研究目标开展了一项由专家参与的评估研究,累计耗时225小时。结果显示,在70%的研究目标中,专家更倾向于我们微调后的Qwen3-30B-A3B模型生成的计划,且对84%的自动生成的目标特定评分标准表示认可。为进一步评估方法的泛化能力,我们还将该方法扩展至医学论文及arXiv预印本中的研究目标,并由前沿模型组成的评审团进行评估。实验表明,我们的微调策略带来了12%至22%的相对性能提升,并展现出显著的跨领域泛化能力,即使在医疗研究等难以获取执行反馈的问题场景中也表现有效。综上,这些结果表明,一种可扩展、自动化的训练范式,正为提升通用型AI协作科学家的能力迈出关键一步。
一句话摘要
Meta Superintelligence Labs、ELLIS Institute Tübingen、马克斯·普朗克智能系统研究所、牛津大学和剑桥大学的研究人员提出了一种可扩展的框架,用于训练AI共同科学家生成高质量的研究计划。他们引入了一种带有自评机制的强化学习方法,其中冻结的初始模型作为评分者,利用从科学论文中提取的目标特定评分标准作为特权信息,从而创建生成器-验证器差距。该方法无需人工监督即可实现性能提升,经人类专家验证,在70%的机器学习研究目标中,专家更偏好其微调后的Qwen3-30B-A3B模型生成的计划;在医学和arXiv领域也表现出显著的性能提升,证明了强大的跨领域泛化能力。
主要贡献
- 我们提出了一种可扩展的方法,能够自动从跨领域的科学论文中提取研究目标和目标特定的评分标准,从而在无需依赖昂贵或不可行的真实世界执行反馈的情况下,训练AI共同科学家。
- 通过使用带有自评机制的强化学习——其中冻结的模型作为评分者,可访问特权评分标准——我们弥合了生成器-验证器差距,使计划生成器能够在无需人工标注的情况下学习到详细且约束感知的研究策略。
- 人类评估显示,70%的情况下,专家更偏好我们微调后的Qwen3-30B-A3B模型生成的计划,而在医学和arXiv论文上的跨领域测试表明相对性能提升了12–22%,证明了即使在无法获取执行反馈的场景下,该方法仍具有强大的泛化能力。
引言
作者解决了训练AI共同科学家生成高质量、约束感知研究计划的挑战,以应对开放性科学目标——这对加速发现至关重要,且无需依赖昂贵的领域特定执行环境。以往方法要么依赖端到端模拟(仅限于狭窄的编程任务),要么缺乏可扩展的反馈机制,尤其在医学等真实世界实验不可行的领域。为克服这一局限,作者提出了一种可扩展、自动化的训练流程,从多个领域的科学论文中提取研究目标和目标特定的评分标准。他们通过强化学习与自评机制训练语言模型,其中初始模型的冻结副本作为评分者,利用提取的评分标准作为特权信息,创建生成器-验证器差距,从而实现无需人工标注的持续改进。人类专家评估显示,70%的情况下,更偏好微调模型生成的计划;在医学和arXiv预印本上的跨领域测试也表现出12–22%的相对性能提升,凸显了强大的泛化能力,验证了训练通用型AI共同科学家的可行性。
数据集

- 该数据集名为ResearchPlanGen,包含从三个领域(机器学习、arXiv预印本、医学研究)的同行评审论文中提取的研究目标、领域特定评分标准和参考解决方案。
- ResearchPlanGen-ML 包含来自NeurIPS 2023–2024和ICLR 2025录用论文的6,872个训练样本(通过OpenReview获取),测试集包含685个样本,来自同级别会议的顶级口头报告和亮点论文。
- ResearchPlanGen-ArXiv 包含6,573个训练样本和1,496个测试样本,按八个定量学科(物理、数学、统计、计算机科学、经济学、电气工程、量化金融、量化生物学)分层,测试数据采集于2025年8月至9月,以防止模型污染。
- ResearchPlanGen-Medical 数据源自pmc/openaccess数据集,使用2023年3月后发表的同行评审论文;尽管可能存在与预训练数据的重叠,但目标微调仍证明了方法的有效性。
- 作者使用该数据集进行模型训练与评估,训练过程中将三个子集按领域特定混合比例结合,以确保代表性均衡。
- 数据处理包括按发表日期、领域相关性和质量(如排除低质量或污染样本)进行过滤,经过精心筛选以保持数据代表性并避免偏差。
- 针对医学研究,作者采用严格的标注协议并设置防LLM机制,包括脱敏提示注入和强制政策,防止标注过程中出现自动化生成。
- 元数据构建包含详细的实验设计要素,如样本量、处理时间线和质控步骤,并完整记录所有协议与控制措施。
- 在医学子集中采用裁剪策略,聚焦特定研究目标(如肺癌中sEV DNA分析),并定义精确的实验流程,包括核酸酶消化步骤、内标控制和正交验证方法。
方法
该方法的核心是训练一个策略模型 πθ,在给定开放性研究目标 g 的情况下生成研究计划 p。该方法解决了获取大规模、高专业度数据集的挑战,并在无需昂贵人工监督的情况下建立自动化反馈机制。该框架利用语言模型从现有科学论文中提取研究目标和目标特定评分标准,随后通过强化学习(RL)训练计划生成器。关键组件是使用初始模型的冻结副本作为评分者 θr(g,p,Rg),其基于生成计划输出一个奖励 r∈[0,1]。这使得无需专家监督即可进行迭代训练,而人类评估仅用于最终验证。
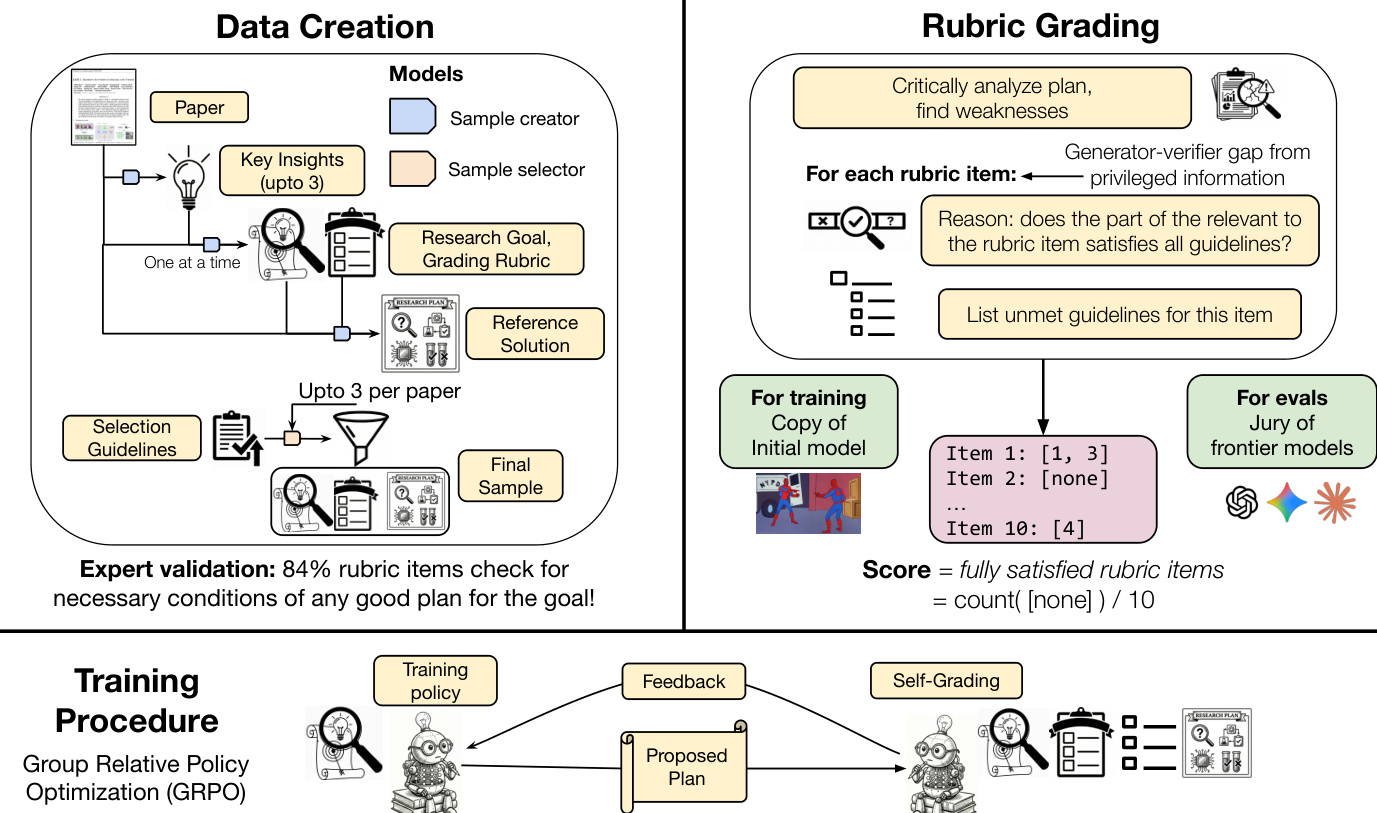
整体方法分为三个主要阶段:数据创建、评分标准评分和训练流程。数据创建过程始于一个样本生成模型,该模型从单篇科研论文中提取最多三个候选元组——每个元组包含一个研究目标、一组初步评分标准和一个参考解决方案。该过程受特定指令引导,聚焦于新颖性。随后,一个样本选择模型独立评估每个候选元组的各个组成部分。评分标准根据多样性与质量筛选至前10项,目标与评分标准需符合预设质量标准,参考解决方案则采用与最终计划评估相同的协议进行评分。综合所有组件得分最高的元组被选为最终训练样本。这一自动化、可扩展且领域无关的流程确保了高质量训练数据的收集。
评分标准评分过程旨在为训练提供可靠且方向正确的奖励信号。评分者将拟议计划与两个关键资源进行比对:目标特定评分标准和一组七条通用准则。对于每项评分标准,评分者必须明确指出计划相关部分是否违反了任何通用准则。只有当评分者返回空的违规列表时,该项评分标准才被视为满足。最终得分为满足的评分标准项所占比例。这种基于违规的评分方法旨在产生比直接二元或数值评分更扎实的评分结果,并支持细粒度错误分析。通用准则源自语言模型生成研究设想时的常见失败模式,旨在确保计划符合科学推理的基本原则,如避免模糊提案或忽略潜在缺陷。
训练流程采用组相对策略优化(GRPO)来优化策略 πθ。该方法通过在相同输入的输出组内归一化奖励,消除了对独立价值网络的需求。主要奖励信号由初始策略的冻结副本提供,该副本充当评分者。为防止模型通过增加计划长度来最大化奖励,引入结构约束。模型允许使用无限“思考”令牌进行推理,但最终计划必须严格限制在指定长度内。任何违反该约束的行为将受到惩罚。最终数值奖励计算为满足的评分标准项数与总评分标准项数之比,再减去格式违规的惩罚。
实验
- 在100个机器学习研究计划的人工评估中,微调模型在70.0% ± 5.3%的标注中优于初始Qwen-3-30B模型(p < 0.0001),平均得分分别为7.89 ± 0.2 vs. 7.31 ± 0.2,表明计划质量与对研究生的实用性均显著提升。
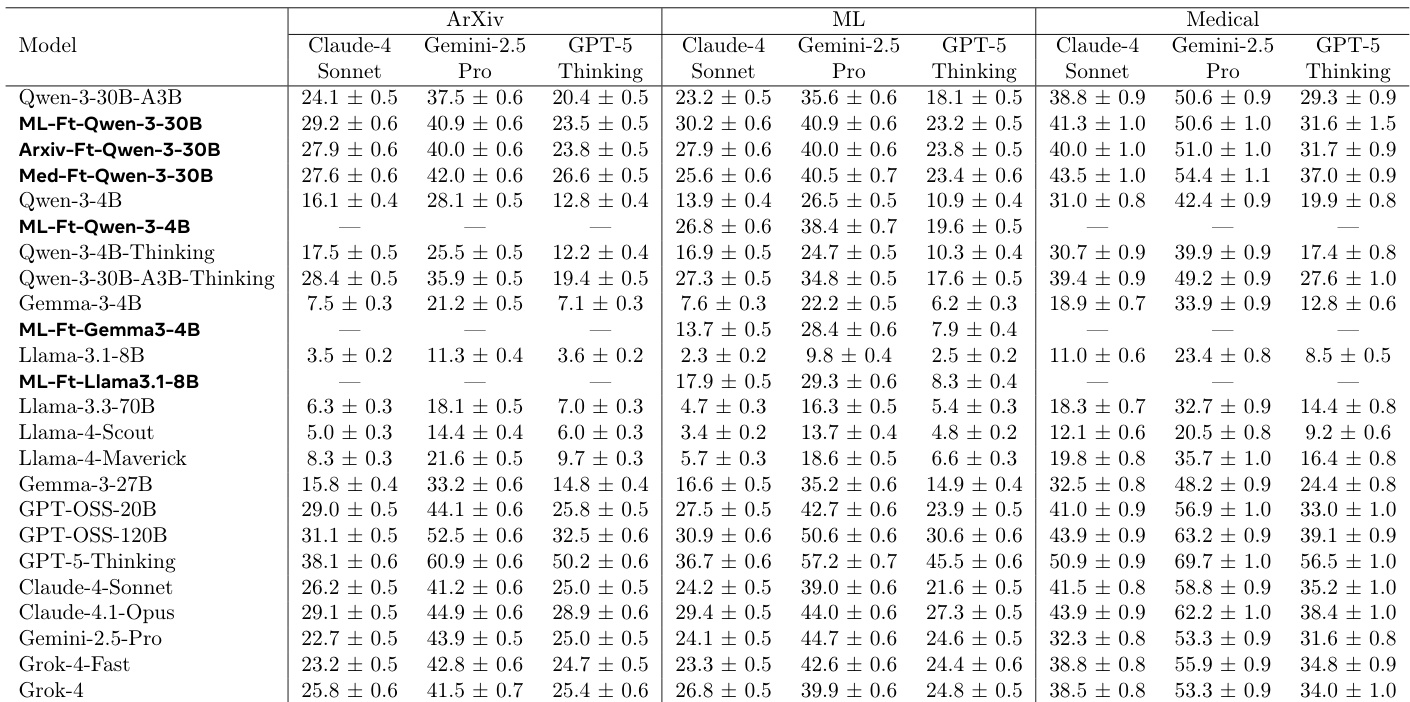
- 在机器学习、医学和arXiv领域使用前沿模型组成的评审团(GPT-5-Thinking、Gemini-2.5-Pro、Claude-4-Sonnet)进行自动化评估,结果一致显示性能提升:微调模型相比初始策略相对提升10–15%,其中医学微调在机器学习和arXiv任务上分别实现15%和17.5%的相对改进。
- 消融研究证实,使用评分标准进行奖励建模、禁用KL惩罚、采用更强的30B MoE奖励模型,以及同时提供具体与通用准则,均显著提升性能;而监督微调反而导致计划质量下降。
- 跨领域泛化能力得到验证:领域特定微调(如医学)可提升在无关领域(机器学习、arXiv)的性能,表明模型学习到了通用的研究规划原则。
- 人类评审员与前沿模型之间的一致性中等(如GPT-5-Thinking的κ = 0.44),尽管单样本评估存在主观性,但自动化评分在整体上表现出显著信号,验证了其在可扩展评估中的适用性。
作者使用前沿模型组成的评审团,评估微调模型与初始模型在多个领域中的表现。结果显示,微调模型在所有情况下均持续优于初始模型,胜率在51.8%至88.0%之间,具体取决于模型与领域,且微调模型的平均得分始终更高。

作者使用三个前沿大语言模型(LLM)作为评审员,比较训练后模型与参考模型输出的性能。结果显示,训练后模型在所有评审员中均表现出更高的一致率(Agr)和召回率(H=1),Gemini-2.5-Pro评审员在两组输出中均表现最佳。LLM共识得分略低于单个评审员得分,表明评审员之间存在中等程度的一致性。

作者使用人类专家标注评估微调模型生成的研究计划与初始模型相比的质量。结果显示,专家在70.0%的标注中更偏好微调模型的计划,整体得分显著提升(7.89 vs. 7.31,满分10分)。微调模型满足的评分标准项更多(79.8% vs. 73.8%),表明其在多个维度上均具备更高计划质量。

作者采用基于自生成奖励的强化学习框架,对语言模型进行微调,以生成研究计划,并在机器学习、arXiv和医学领域中将初始Qwen-3-30B模型与其微调变体进行比较。结果显示,微调模型在自动化评估中始终优于初始模型,领域特定微调带来显著性能提升,并展现出跨领域泛化能力,尤其在医学领域表现突出。
作者使用验证集和更强的语言模型Claude-4-Sonnet,确定训练的最佳停止步数,选择在验证集上表现最优的检查点。表格显示,停止步数因模型和微调领域而异:Qwen-3-30B模型在机器学习和arXiv任务上的微调于第100步停止,而PubMed微调则在第140步停止。对于Qwen-3-4B模型,机器学习微调的停止步数为200,而SFT和RL变体为100,表明最优训练时长取决于具体模型与任务。
