Command Palette
Search for a command to run...
MindWatcher:迈向更智能的多模态工具融合推理
MindWatcher:迈向更智能的多模态工具融合推理
摘要
传统基于工作流的智能体在处理需要调用工具的现实世界问题时,表现出智力能力有限的局限性。能够实现自主推理与工具调用的工具融合推理(Tool-integrated Reasoning, TIR)智能体,正迅速成为应对涉及与外部环境多步交互的复杂决策任务的强大方法。在本研究中,我们提出 MindWatcher,一种融合交错式思维(interleaved thinking)与多模态思维链(multimodal chain-of-thought, CoT)推理的 TIR 智能体。MindWatcher 能够自主判断是否以及如何调用多种工具,并协调其使用,完全无需依赖人工提示或预设工作流。其交错式思维范式使模型可在任意中间阶段自由切换思维与工具调用,而其多模态 CoT 能力则支持在推理过程中对图像进行操作,从而获得更精准的搜索结果。我们构建了自动化的数据审计与评估流水线,并结合人工精心构建的高质量数据集进行训练,同时设计了一个名为 MindWatcher-Evaluate Bench(MWE-Bench)的基准测试集,用于系统评估其性能。MindWatcher 配备了一套全面的辅助推理工具,具备解决跨领域多模态问题的能力。一个涵盖汽车、动物、植物等八类对象的大规模、高质量本地图像检索数据库,使其在模型规模较小的情况下仍具备强大的物体识别能力。最后,我们设计了一种更高效的训练基础设施,显著提升了训练速度与硬件资源利用率。实验结果不仅表明,MindWatcher 通过卓越的工具调用能力,达到甚至超越了更大规模或更先进模型的性能,还揭示了智能体训练中的若干关键洞见,例如在智能体强化学习(agentic RL)中发现的“遗传继承”现象。
一句话总结
来自理想汽车的作者介绍了 MindWatcher,这是一种多模态工具集成推理代理,通过交错式思维与多模态思维链推理,能够自主协调多种工具(包括图像区域操作、本地视觉搜索和代码执行),而无需依赖人工工作流。通过采用一种新颖的分步归一化策略的持续强化学习,以及大规模、专家标注的本地图像检索数据库,MindWatcher 在 MWE-Bench 上实现了最先进性能,在复杂真实任务中超越更大模型的同时,还能高效地蒸馏为更小的变体。
主要贡献
- MindWatcher 引入了一种交错式思维与多模态思维链框架,实现了推理与工具调用之间的自主、动态决策,支持细粒度视觉操作和跨模态推理,适用于超越纯文本能力的真实世界多模态任务。
- 该代理通过持续强化学习进行训练,采用自动化数据流水线生成图文对,避免了监督微调带来的僵化模仿和过度工具调用等问题,同时在复杂多步任务中表现出卓越性能。
- MindWatcher 在新构建的 MWE-Bench 基准上进行了评估,其在 2B、3B 和 4B 蒸馏模型上均达到最先进水平,通过高效的工具协调和覆盖八个领域的本地图像检索数据库,超越了更大或更新的模型。
引言
作者针对智能代理在真实环境中实现自主、多步推理日益增长的需求展开研究,传统基于工作流的系统乃至现代多代理架构在适应性、延迟和跨模态整合方面仍面临挑战。先前的 TIR 代理大多局限于文本任务,对细粒度视觉推理支持有限,且存在训练不稳定、工具冗余使用以及依赖昂贵外部 API 的问题。为克服这些挑战,作者提出 MindWatcher,一种结合交错式思维与多模态思维链推理的多模态 TIR 代理,支持动态、上下文感知的工具调用和直接图像操作。系统采用持续强化学习而非监督微调,避免僵化模仿;引入一种新颖的强化学习算法,结合分步归一化实现稳定训练;并集成低成本本地视觉语料库与自动化数据流水线。MindWatcher 在新构建的多模态基准 MWE-Bench 上达到最先进性能,超越更大模型,同时表明基础模型的局限性对代理推理构成根本性的“遗传约束”,即使经过大量强化学习优化也难以突破。
数据集

-
数据集由多个来源构成,包括私有的高质量多模态数据库、权威体育门户以及精心筛选的开源基准。数据集核心为 MindWatcher 多模态检索数据库(MWRD),涵盖八个类别:人物、汽车、植物、动物、标志、地标、水果与蔬菜、菜肴。该数据库包含 50,000 个检索实体,每个实体配有 3–10 张高质量图像,总计超过 30 万张图像。图像来源于互联网和专业博物馆数据库,并经过专家级筛选与整理,确保精度超过 99%。
-
MWRD 用于支持训练中的多模态推理与工具使用。训练数据通过三阶段流水线构建跨模态问答数据集:源知识锚定与生成、问答质量验证、难度分级。该流程包括基于目标定位与检索标注的细粒度视觉-知识映射,随后利用网络搜索增强知识图谱以丰富事实背景。初始问答对基于视觉与外部知识共同生成。
-
针对特定领域(尤其是体育数据)设有专用数据摄入流水线。聚焦爬虫从权威体育门户收集文章,仅保留包含非空文本且至少包含一张相关图像的内容。由此构建事件为中心的多媒体文档库,后续用于生成问答对。
-
MWE-Bench 基准严格与训练数据分离,防止数据泄露。包含 373 个汽车、351 个动物、397 个植物、63 个人物、90 个地标和 142 个体育相关实例。非体育类别的知识条目在训练中被排除。构建过程包括扩展知识库至网络数据、应用类别特定约束,并使用闭源模型进行“唯一性解构”以提取核心识别事实。这些事实构成单轮问答对的基础,再合成多步推理任务。所有样本均经过自动化与人工验证,确保质量和时间准确性。
-
对于体育数据,来自非重叠时间点的文本与图像语料库被合并,使用强大大语言模型提取原子事实。基于这些事实构建复杂查询,随后进行类似非体育流水线的数据清洗与过滤。
-
训练数据分布在在线与离线环境中。在线训练包含来自私有图像的 1,639 个 VQA 样本和来自公开新闻源的 2,949 个样本。开源数据来自 WebSailor、ToolStar 和 SimpleDeepSearcher,经严格过滤后共 5,000 个样本,剔除过时或泄露内容。离线强化学习训练使用约 20,000 个样本。课程学习策略指导在 Qwen2.5-VL-32B 模型上进行一 epoch 训练,支持异步工具调用与奖励计算。
-
完全训练后的 MindWatcher-32B 模型用于将多模态推理与工具使用能力蒸馏至更小模型。该过程从 18.1 万样本的基础数据集(VLAA SFT、WebWalker silver 与自建 RAG QA 数据集)中为每个样本生成 1–3 条 TIR 轨迹。过滤后,最终蒸馏数据集包含 12.4 万样本——10 万个多模态样本与 2.4 万个纯文本样本,用于训练 MindWatcher-2B、-3B 与 -4B 模型。
-
MWE-Bench 与过滤后的开源基准(MMSearch 子集:221 个样本;SimpleVQA 子集:823 个样本)用于在 ReAct/Agent 范式下的评估。所有测试使用温度 0.7 与 top-p 0.95,正确性由 LLM 作为裁判评估,主要指标为 pass@1。
方法
作者采用强化学习框架训练 MindWatcher,一种专为多模态推理与自主工具使用设计的代理。系统核心是一个自回归生成循环,将任务建模为马尔可夫决策过程(MDP),代理迭代生成动作并处理环境观测。每一步中,由大型语言模型(LLM)参数化的策略模型基于完整交互历史生成统一动作,该动作可为推理步骤(思考)或工具调用。这些动作通过专用标签序列化,支持在单一解码序列中实现交错式思维与动作生成。该方法支持多模态思维链机制,使代理能够通过将图像相关操作嵌入推理过程来实现图像推理。

如图所示,代理从初始用户提示和图像开始,进入迭代规划与工具调用过程。每次工具调用后,结果观测被追加至上下文,指导下一步动作。代理持续此循环,直至生成包含最终响应的终结动作。该框架整合大规模本地检索语料库与全面的多模态工具集,包括区域裁剪、视觉搜索、外部文本检索、网页内容提取及本地代码执行工具。这使代理能够通过动态与环境交互并利用外部知识源,完成复杂多模态问答。

训练过程采用增强版分组相对策略优化(GRPO)作为核心学习算法。为应对交错式思维带来的挑战——轨迹由多个“思考-工具调用”循环组成且长度各异——作者提出一种分步归一化机制。该方法在单个动作片段上优化目标函数,而非全局 token 流,确保每个推理步骤获得均衡监督。优化目标包含两个归一化因子:动作步归一化,对每条轨迹同等加权,与循环次数无关;token 长度归一化,对每个回合内的损失取平均。该双重归一化机制防止长回合主导优化过程。
奖励函数通过混合奖励系统引导模型实现语法正确性与事实准确性。包含三个组成部分:结果准确率奖励、格式奖励与幻觉工具调用惩罚。结果准确率奖励为稀疏奖励,在任务终止时计算,由基于模型的裁判评估事实一致性。格式奖励使用基于正则表达式的解析器强制执行严格模式,惩罚格式错误及有效标签外的非空白残留。幻觉工具调用惩罚鼓励模型在未获得环境反馈前避免连续工具调用,惩罚模型调用次数与实际响应之间的差异。最终奖励为各组件的加权和,特定系数用于平衡其影响。
实验
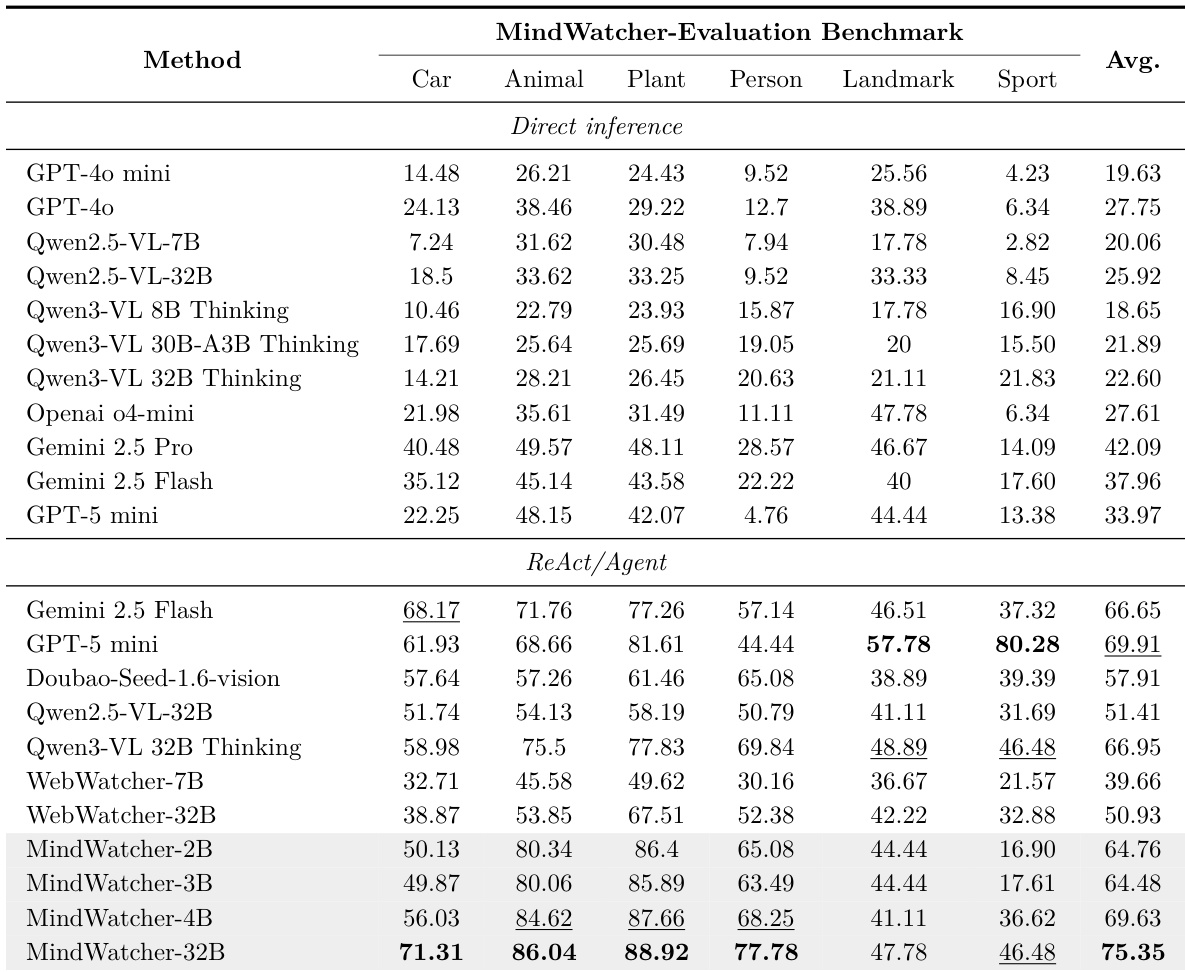
- 主实验验证了工具增强推理在多模态代理中的有效性,特别是 MindWatcher 系列在 MWE-Bench 上实现 SOTA 性能,全局得分为 75.35,超越 Gemini 2.5 Flash 和 GPT-5 mini 等模型。
- 在 MWE-Bench 上,MindWatcher-32B 超越 Qwen3-VL 32B,并在四个领域(车辆、动物、植物、人物)表现强劲;而蒸馏变体(MindWatcher-2B、3B、4B)达到或超过基线模型性能,证明代理能力可弥补参数规模的限制。
- 工具集成显著提升性能:Qwen3-VL 32B 在获得工具访问后得分几乎翻三倍,GPT-5 mini 在体育任务中的得分从 13.38 提升至 80.28,凸显外部工具在克服内部知识局限中的关键作用。
- 在过滤后的基准(MMSearch、SimpleVQA、WebWalkerQA)上,MindWatcher-32B 在所有任务中均达 SOTA,包括在 SimpleVQA 上超越 Qwen3-VL 32B,并在纯文本 WebWalkerQA 上保持竞争力,表明多模态代理推理能力成功增强,同时未牺牲文本处理能力。
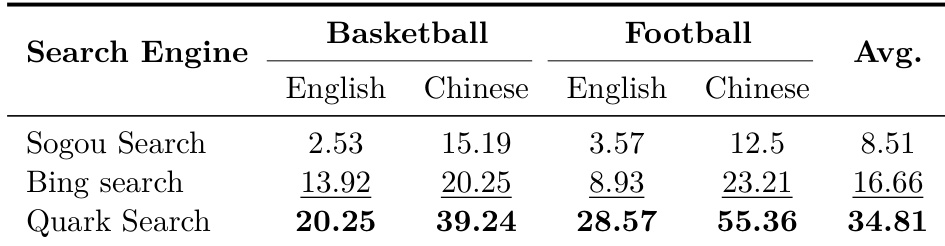
- 搜索引擎选择显著影响性能,Quark 在中文足球查询中比 Sogou 高出 42.86%,表明代理性能高度依赖工具环境,而非仅由模型架构决定。
- 案例研究揭示内部世界知识对工具使用成功至关重要:Qwen3-VL 32B 利用先验知识生成有效查询,而基于 Qwen2.5-VL 的 MindWatcher 因缺乏此类知识而失败,说明基准结果可能受长尾知识差异干扰。
- 遗传继承分析表明,代理强化学习(RL)与监督微调(SFT)均保留了基模型的认知上限:尽管 RL 实现了稳定、结构化的工具使用行为并呈现同步性能衰减,SFT 则导致工具调用模式波动大、优化不一致,表明 RL 在复杂推理中具有更优对齐性。
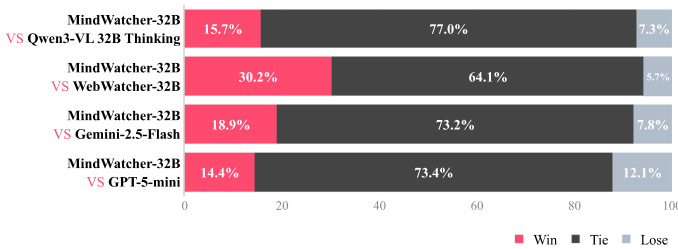
作者采用胜-平-负分析,将 MindWatcher-32B 与四个模型在公开基准与 MWE-Bench 上进行对比,结果显示 MindWatcher-32B 持续优于其 32B 对应模型,并在与 Gemini 2.5 Flash 和 GPT-5 mini 等 SOTA 闭源模型的对比中表现更优。结果表明,MindWatcher-32B 在与 Qwen3-VL 32B Thinking 的对比中胜出 15.7%,与 WebWatcher-32B 对比胜出 30.2%,与 Gemini 2.5-Flash 对比胜出 18.9%,与 GPT-5 mini 对比胜出 14.4%,多数结果为平局。
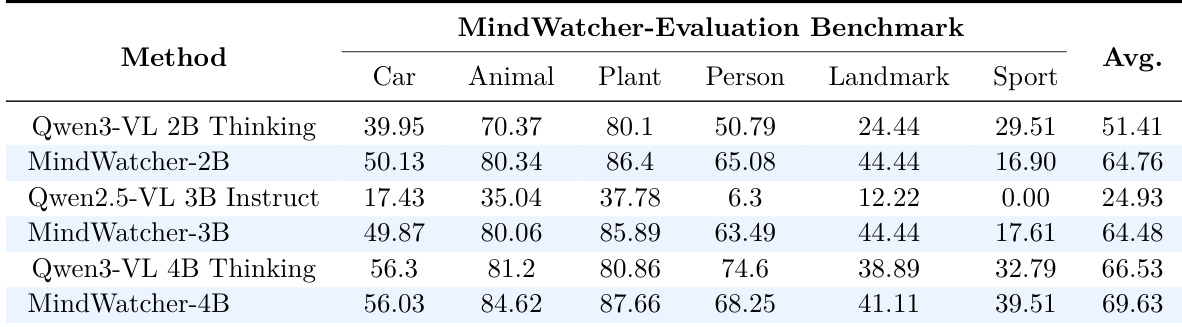
作者使用 MWE-Bench 评估 MindWatcher 蒸馏模型与基础模型在多个领域上的表现。结果显示,MindWatcher-2B、-3B 与 -4B 的平均得分显著高于各自基模型,其中 MindWatcher-4B 达到最高总分 69.63,表明蒸馏模型在多数类别中优于其更大版本。
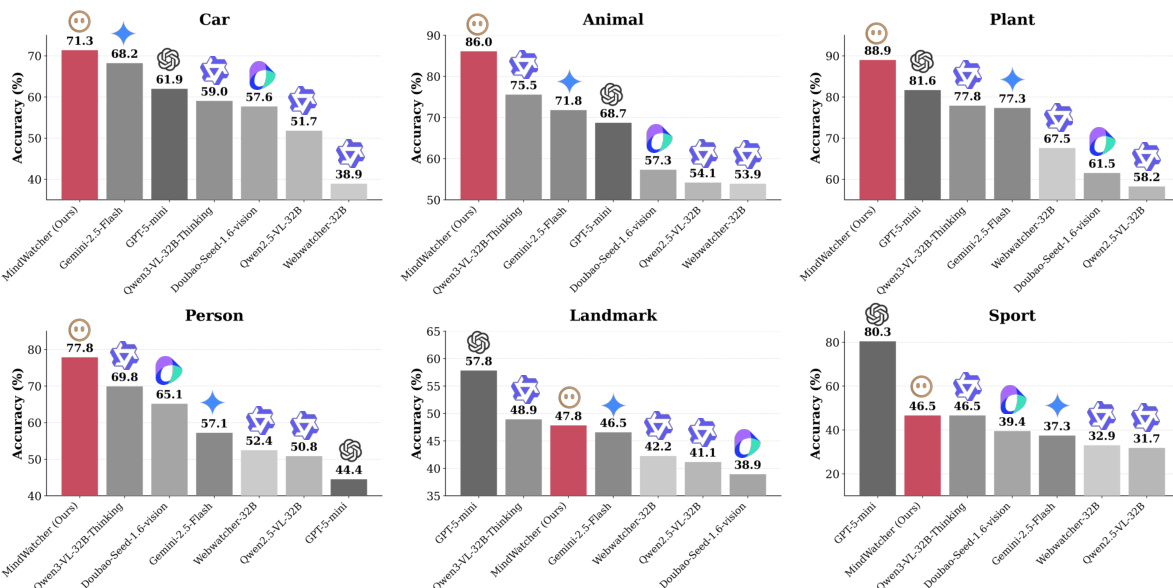
作者使用提供的柱状图比较各模型在 MWE-Bench 六个领域上的表现,MindWatcher-32B 在其中四个领域(汽车、动物、植物、人物)取得最高准确率。结果显示,MindWatcher-32B 在所有领域均超越 Gemini 2.5 Flash 和 GPT-5 mini 等知名闭源模型,展现出卓越的代理能力。
作者使用 MWE-Bench 评估模型在直接推理与 ReAct/Agent 模式下的性能,结果显示内部知识截止时间无法一致预测性能,例如 Gemini 2.5 Pro 在直接推理中表现优于更近期模型。结果表明,工具增强推理显著提升性能,MindWatcher-32B 达到 75.35 的最高总分,在多个领域超越开源与闭源模型。
结果显示,搜索引擎选择对体育相关查询的代理性能影响显著,Quark Search 在所有领域与语言上平均得分最高,达 34.81。性能随查询领域与语言变化显著,表明工具能力高度依赖具体上下文,而非普遍优越。