Command Palette
Search for a command to run...
多样性还是精确性?深入探究下一个token预测
多样性还是精确性?深入探究下一个token预测
Haoyuan Wu Hai Wang Jiajia Wu Jinxiang Ou Keyao Wang Weile Chen Zihao Zheng Bei Yu
摘要
最近的研究表明,强化学习(Reinforcement Learning, RL)能够显著提升大语言模型(Large Language Models, LLMs)的推理能力。然而,此类RL训练的有效性在很大程度上取决于预训练模型所定义的词元输出分布所构成的探索空间。本文重新审视了标准的交叉熵损失,将其解释为在单步任务中应用策略梯度优化的一个特例。为了系统地研究预训练分布如何影响后续强化学习的探索潜力,我们提出了一种广义的预训练目标,该目标将基于策略的强化学习原则引入监督学习框架。通过将下一个词元预测建模为一个随机决策过程,我们引入了一种奖励塑形策略,显式地平衡了输出的多样性与精确性。我们的方法采用一个正向奖励缩放因子,用于控制模型对真实词元的概率集中程度,并设计了一种基于排名的机制,对高排名与低排名的负样本词元进行不对称处理。这一机制使我们能够重构预训练模型的词元输出分布,并探究如何为强化学习构建更具优势的探索空间,从而最终提升端到端的推理性能。与“更高分布熵有助于有效探索”的直觉相反,我们发现,引入以精确性为导向的先验分布,反而能为强化学习提供更优越的探索空间。
一句话总结
腾讯与香港中文大学的研究者提出了一种广义的预训练目标,将基于策略的强化学习(RL)原则应用于监督学习,通过正向缩放和排名感知机制进行奖励塑造,以平衡标记分布中的多样性与精确性,从而为强化学习创造更有利的探索空间,提升了端到端推理性能,这与传统认为高熵有助于探索的观点相反。
主要贡献
-
我们将标准交叉熵损失重新解释为单步策略梯度优化,从而系统性地研究预训练模型的标记输出分布如何塑造下游强化学习的探索空间。
-
我们提出了一种广义的预训练目标,将基于策略的强化学习原则融入监督学习,通过奖励缩放因子控制对真实标记的概率集中,并引入排名感知机制,对高排名和低排名的负标记进行不对称抑制。
-
实验表明,以精确性为导向的先验——与普遍认为高熵有助于探索的观点相反——能带来更有效的探索空间,在后续强化学习阶段显著提升端到端推理性能。
引言
研究者探讨了下一个标记预测在强化学习(RL)过程中对大型语言模型行为的影响,特别是在推理任务中。尽管以往工作将预训练视为与强化学习分离的监督过程,但研究者指出,常用于预训练的交叉熵损失可被解释为一种基于策略的策略梯度优化形式,建立了预训练与强化学习之间的理论联系。这一洞见揭示了预训练输出分布——由损失的奖励结构塑造——隐式定义了后续强化学习中的探索空间,影响了模型所选择的推理路径。然而,传统预训练方法将奖励结构固定为偏向精确性,将概率质量集中于真实标记,可能限制多样性并约束探索。研究者的主要贡献是一种广义的预训练目标,通过奖励塑造显式控制多样性与精确性之间的权衡:他们引入正向缩放因子以调节对正确标记的概率集中,并基于排名对负标记实施非对称抑制。该方法允许对预训练策略进行系统性调优,且出人意料地发现,以精确性为导向的先验——而非高熵——能带来更优的强化学习探索效果和更强的端到端推理性能。
方法
研究者利用策略梯度框架,将标准的下一个标记预测交叉熵损失重新解释为单步回合强化学习(RL)优化的一个特例。这一视角使得能够系统性地探究预训练模型的标记输出分布如何塑造后续强化学习训练的探索空间。核心思想是将每个标记的生成视为独立的决策过程,语言模型作为随机策略 πθ,根据当前上下文 st=X<t 从词汇表 V 中选择下一个标记。训练目标被表述为最大化期望即时奖励,简化为单步回报 Jt(θ∣st)=Eat∼πθ(⋅∣st)[r(st,at)]。该公式确保奖励仅依赖于当前状态-动作对,与回合制任务的策略梯度推导一致。
在此框架下,标准交叉熵目标被表示为具有内在奖励函数 rCE(st,at)=sg(πθ(at∣st)1(at=xt)) 的策略梯度,其中停止梯度操作符 sg(⋅) 确保奖励仅依赖于当前步骤。该奖励结构隐式平衡了多样性与精确性:高概率的真实标记会获得与自身概率成反比的大奖励,而所有负标记均被赋予零奖励。研究者通过引入一种奖励塑造策略,对多样性与精确性之间的权衡进行显式控制,提出了两个机制。
首先,引入一个正向奖励缩放因子,以调节真实标记的影响。修改后的正向奖励定义为 rˉpos(st,at)=sg((πθ(at∣st)1)(1−πθ(at∣st))β),其中 β 控制分布的全局熵。当 β<0 时,奖励被放大,导致概率质量强烈集中于真实值,熵降低;反之,β>0 会削弱奖励,使模型保持更平坦的分布,熵更高。该机制实现了对预训练期间全局探索潜力的精细控制。
其次,研究者提出一种排名感知的负奖励机制,以调节局部熵。设 Kt 表示前 k 个预测标记的集合。负奖励被不对称分配:高排名负标记(属于 Kt 但非真实标记)获得奖励 λ~,而低排名负标记(不属于 Kt)获得奖励 λ^。该设计通过保留对合理替代项的概率质量,防止对真实值的过度自信,同时抑制分布尾部,以鼓励集中在最可能的候选项上。广义奖励函数将这些组件组合为 rˉ(st,at)=rˉpos(st,at)⋅1(at=xt)+rˉneg(st,at)⋅1(at=xt),其中 rˉneg(st,at)=λ~⋅1(at∈Kt∧at=xt)+λ^⋅1(at∈/Kt∧at=xt)。
该奖励塑造策略被嵌入监督学习目标中,有效将基于策略的强化学习原则应用于预训练。由此产生的广义损失函数允许系统性探索在预训练阶段重塑标记输出分布如何影响后续强化学习阶段。研究者证明,以精确性为导向的先验——表现为降低全局熵并抑制低概率标记——能为强化学习创造更有利的探索空间,最终提升端到端推理性能。该框架兼容在标记输出前执行迭代内部计算的架构,如潜在推理模型和循环变压器,并可作为不确定性感知的学习信号,指导自适应计算策略。
实验
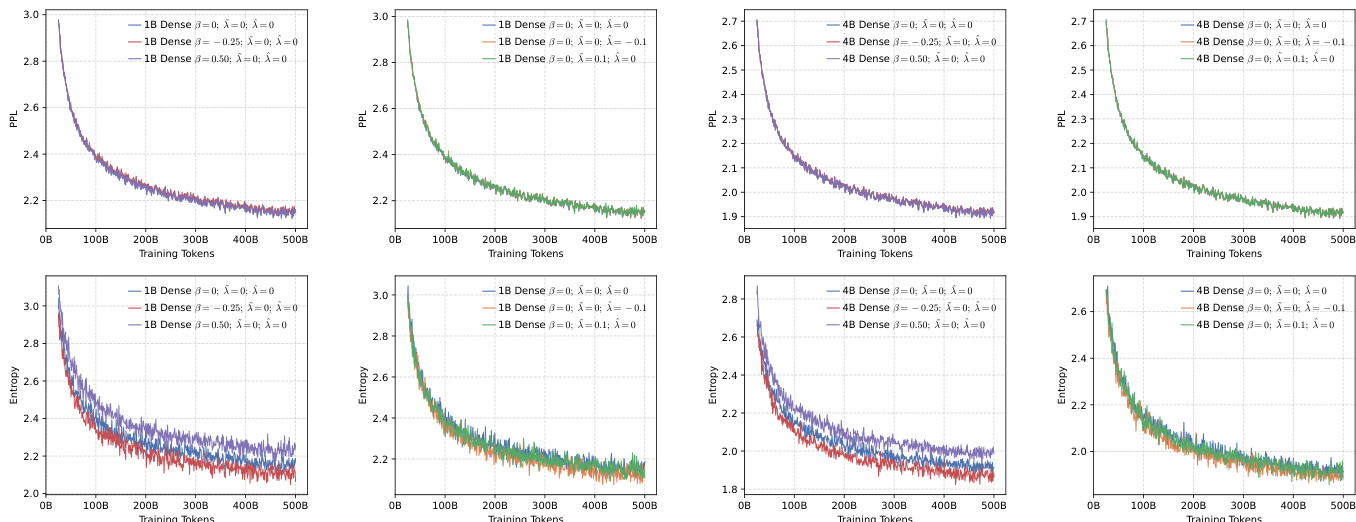
- 预训练评估验证了广义训练目标在密集模型和MoE架构中平衡多样性与精确性的有效性,各模型均表现出更低的困惑度和稳定的收敛性。
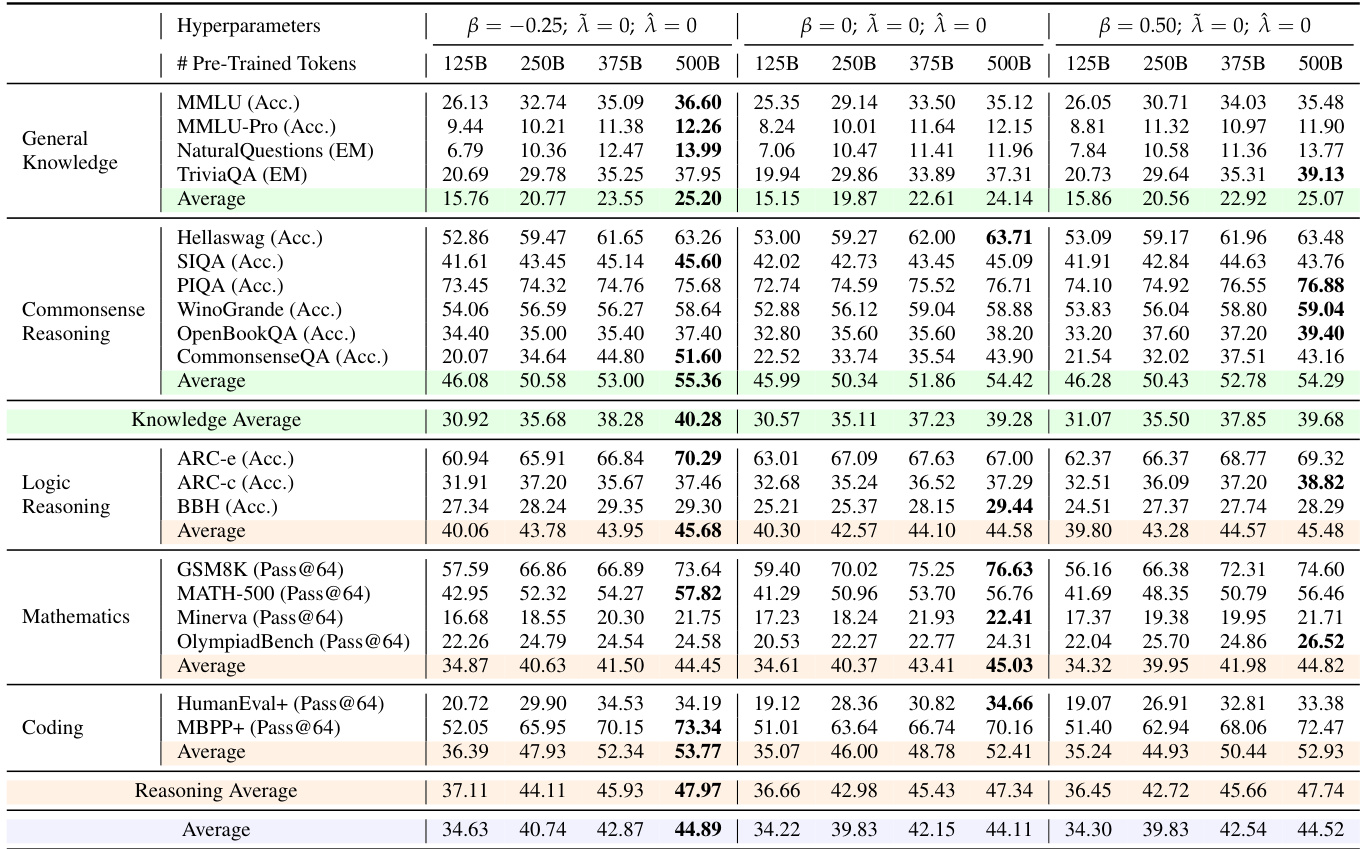
- 中期训练实验表明,设置 β = -0.25 在知识和推理任务上持续优于基线,而通过 λ^=−0.1,λ~=0 实现的局部熵控制则提升了模型的可扩展性。
- 强化学习结果表明,全局低熵设置(β = -0.25)和局部高熵配置(λ^=−0.1,λ~=0)在数学和编码基准测试中表现更优,平均@128、一致性@128和通过率@64得分更高。
- Pass@k分析确认,优先考虑精确性而非全局多样性,能带来数学和代码生成任务中更高的上限性能,同时保持输出多样性的稳定。
- 在 MATH-500 和 OlympiadBench 上,10B-A0.5B MoE 模型在 β = -0.25 时分别达到 Pass@64 68.4 和 52.1,较基线分别提升 12.3 和 9.7 分。
- 在 HumanEval+ 上,10B-A0.5B MoE 模型在 λ^=−0.1,λ~=0 时达到 Pass@64 74.2,较基线提升 8.5 分。
研究者使用多种模型架构(包括密集模型和MoE模型)评估不同奖励配置对训练动态和性能的影响。结果表明,促进精确性的配置(如设置 β = -0.25 或使用 λ̂ = -0.1 的局部熵控制)在预训练、中期训练和强化学习阶段均持续表现出更优性能。

研究者使用多种基准测试评估模型在通用知识、常识推理、逻辑推理、数学和编码任务上的表现。结果表明,β = -0.25 的配置在大多数评估指标上持续取得最高得分,尤其在数学和编码任务中表现突出,表明通过降低全局熵促进精确性可带来更优性能。
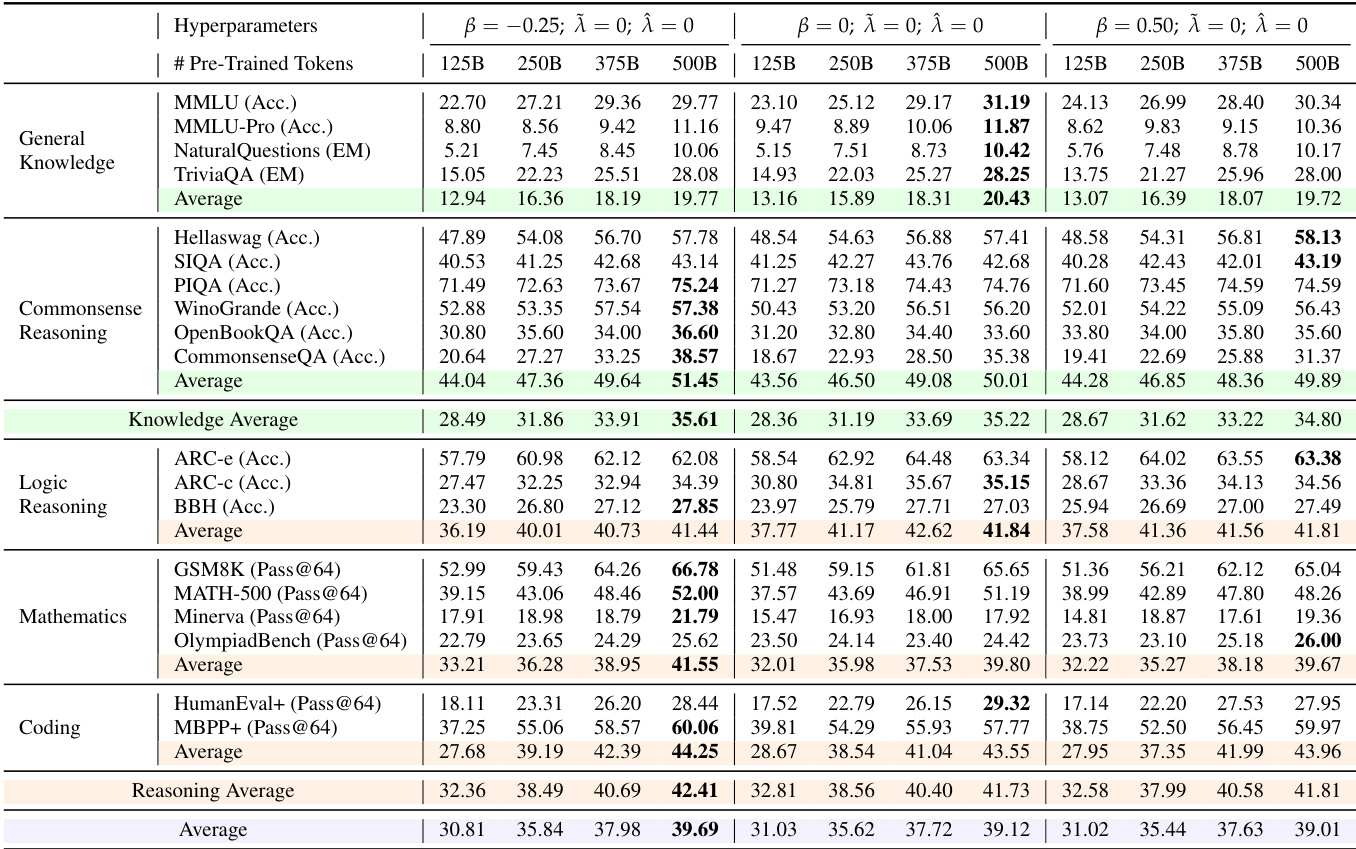
研究者使用多种基准测试评估基础模型在通用知识、常识推理、逻辑推理、数学和编码任务上的表现。结果表明,β = 0, λ̃ = 0, λ̂ = 0 的配置在大多数任务上持续取得最高性能,尤其在数学和编码任务中达到最佳 Pass@64 得分。
研究者使用 Pass@64 指标评估 4B 密集模型在数学推理任务强化学习训练过程中的表现。结果显示,模型的 Pass@64 分数从 100 步时的 18.31 稳步提升至 1000 步时的 16.58,表明其生成正确解的能力随时间持续增强。所有基准测试的平均 Pass@64 在最终步骤达到 49.59,显示出推理性能的显著进步。
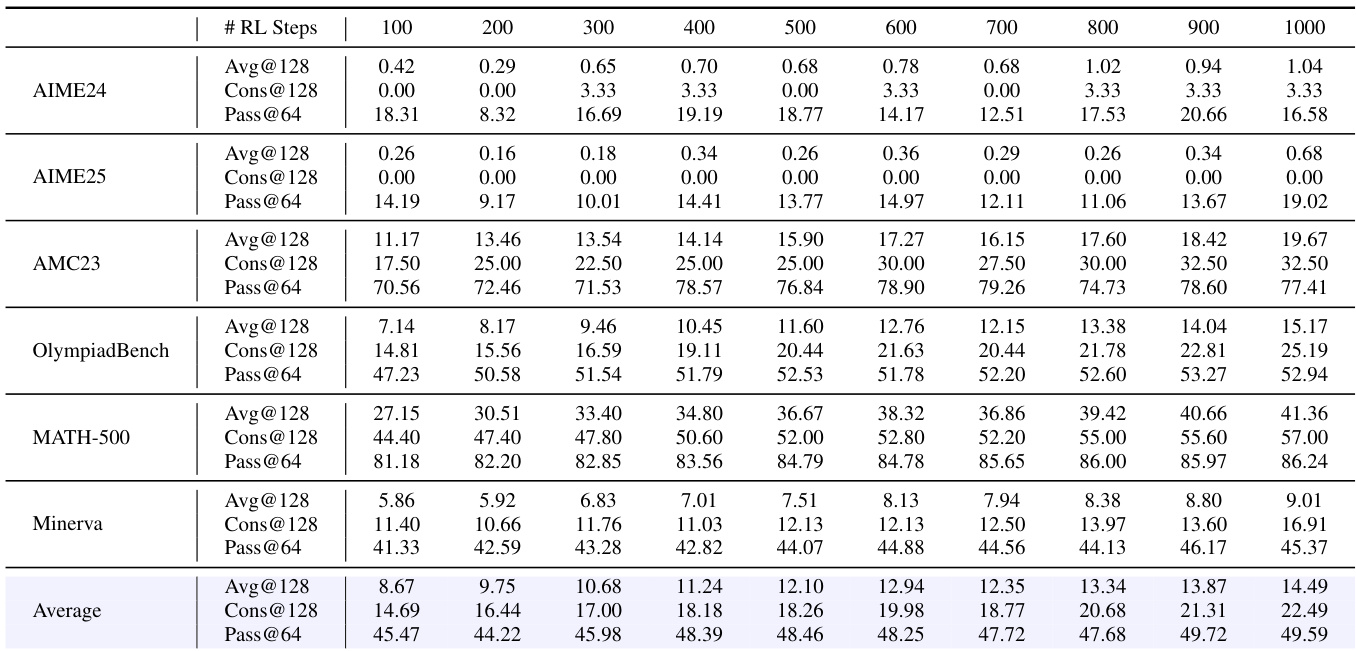
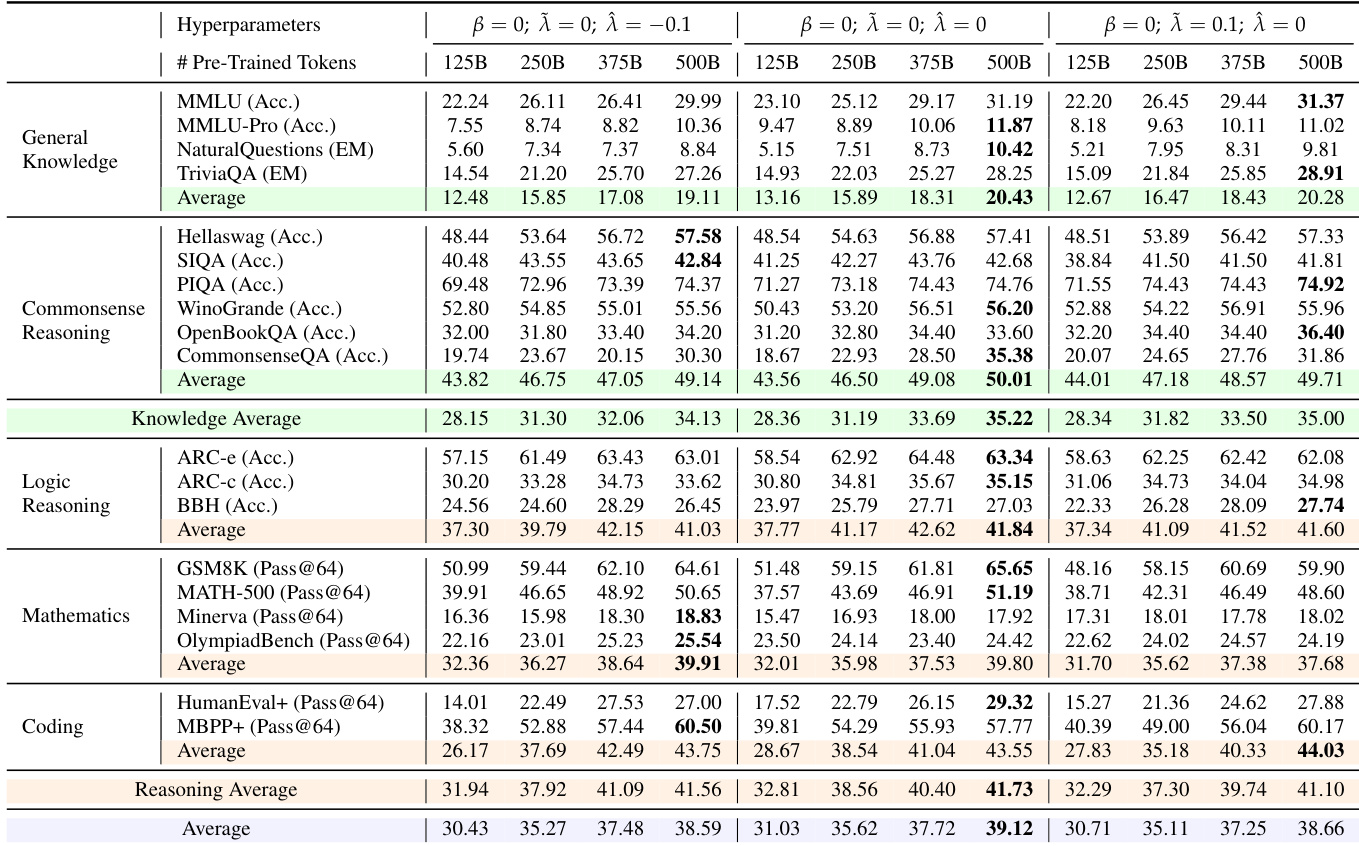
研究者使用多种基准测试评估模型在通用知识、常识推理、逻辑推理、数学和编码任务上的表现。结果表明,全局熵较低的配置(β = -0.25)在大多数任务上持续取得更高性能,尤其在数学和编码任务中表现突出,同时保持足够的输出多样性。数据进一步表明,无论全局还是局部地促进精确性,均能带来更好的性能和可扩展性,尤其在大模型中表现更明显。