Command Palette
Search for a command to run...
SciEvalKit:面向科学通用智能的开源评估工具包
SciEvalKit:面向科学通用智能的开源评估工具包
摘要
我们提出 SciEvalKit,一个统一的基准评估工具包,旨在全面评估人工智能模型在多个科学领域及任务能力上的表现。与通用评估平台不同,SciEvalKit专注于科学智能的核心能力,包括:科学多模态感知、科学多模态推理、科学多模态理解、科学符号推理、科学代码生成、科学假设生成以及科学知识理解。该工具包覆盖六大主要科学领域,涵盖物理学、化学、天文学到材料科学等广泛学科。SciEvalKit 基于真实世界、领域特定的数据集,精心构建了专家级的科学基准,确保评估任务真实反映科学实践中的核心挑战。其评估流程具备高度灵活性与可扩展性,支持跨模型与跨数据集的批量评估,兼容自定义模型与数据集的集成,并提供透明、可复现且可比较的评估结果。通过融合能力导向的评估体系与学科多样性,SciEvalKit 为下一代科学基础模型与智能体的性能评估,提供了一个标准化但又可定制化的基础设施。该工具包已开源并持续维护,致力于推动社区驱动的协同开发,促进人工智能赋能科学(AI4Science)领域的持续进步。
一句话摘要
上海人工智能实验室的作者与社区贡献者推出了 SciEvalKit,这是一个统一的开源基准测试工具包,用于在六个领域评估人工智能模型在科学智能方面的表现,包含专家精心策划的真实世界任务,并提供灵活的流水线以实现可复现、可扩展的能力评估,涵盖多模态推理、符号推理和假设生成等能力——为下一代科学基础模型的标准化评估提供了支持。
主要贡献
-
SciEvalKit 通过引入统一的基准测试框架,解决了当前人工智能模型在科学智能方面缺乏全面评估的问题,系统性地评估了七项核心能力——从科学知识理解、符号推理到多模态感知和假设生成——全面反映了真实科学推理的全貌。
-
该工具包基于六个主要科学领域(如物理、化学、天文学、材料科学)的专家精心策划的领域特定基准,确保任务真实反映科学挑战,要求模型具备超越表面模式识别的深层概念、符号和多模态理解能力。
-
SciEvalKit 提供灵活、开源的评估流水线,支持批量测试、自定义模型与数据集集成,以及透明、可复现的结果输出。实证研究表明,尽管在通用基准上得分超过 90,但在科学任务上的表现普遍低于 60,凸显了对专用科学人工智能能力的迫切需求。
引言
作者利用 SciEvalKit——一个开源评估工具包——应对大型语言模型和多模态模型在科学智能方面日益增长的严格、领域特定评估需求。当前基准测试存在局限,主要聚焦于狭窄的表面任务,如事实回忆或通用图像描述,而未能捕捉真实科学工作流中所需的复杂、多表征推理,包括符号操作、代码生成、假设形成以及科学数据的多模态理解。这一差距在那些在通用任务上表现良好但在专家级科学挑战中表现不佳的模型中尤为明显,揭示了广泛能力与领域专业知识之间的关键脱节。主要贡献在于一个统一且可扩展的评估框架,整合了六个科学学科中的 15 个专家策划的基准,围绕基于认知理论的七维科学智能分类体系组织。通过支持执行感知评分、多模态输入以及透明、可复现的评估,SciEvalKit 实现了以能力为导向的评估,揭示了当前模型在符号推理和视觉定位方面的根本性缺陷,同时为推进科学领域的人工智能提供了一个标准化、社区驱动的平台。
数据集

-
该数据集 SciEvalKit 是一个精心策划的基准套件,旨在跨多种模态和学科评估大语言模型的科学智能。它包含纯文本和多模态基准,均通过专家咨询筛选,并与真实科学工作流程对齐。
-
主要子集包括:
- 纯文本基准:ChemBench(化学与材料科学)、MaScQA(材料科学)、ProteinLMBench(生物分子推理)、TRQA-lit(生物医学文献推理)、PHYSICS(本科物理)、CMPhysBench(凝聚态物理)、SciCode(科学代码生成)和 AstroVisBench(天文学可视化代码)。
- 多模态基准:MSEarth(地球科学,含视觉图表)、SLAKE(临床影像,含 CT/X 射线/MRI 及语义标注)和 SFE(多语言、多学科科学图表,含从感知到推理的任务)。
-
每个子集均基于真实科学内容,任务源自实际研究场景。数据规模各异:ChemBench 包含 100+ 个问题,ProteinLMBench 有 944 个六选一问题,SFE 包含 830 个经验证的视觉问答对,AstroVisBench 使用 110 个 Jupyter Notebook。所有基准均经过专家验证,确保科学有效性、正确解题逻辑和评分标准。
-
论文采用训练与评估分离的数据划分方式,仅将基准用作评估任务,不从中提取训练数据。模型评估采用跨学科与能力的混合基准组合,比例设计旨在平衡覆盖七项核心科学智能维度:科学多模态感知、理解、推理,以及纯文本能力(包括知识、代码生成、符号推理和假设生成)。
-
处理流程包括专家对任务表述的精心策划、答案的手动验证,以及与领域标准的对齐。对于多模态任务,图像与精确的文本上下文和元数据配对,如语义分割掩码(SLAKE)、地理空间坐标(MSEarth)和科学图表标题。SFE 采用分层认知层级(感知、理解、推理)来组织任务。基于代码的基准(SciCode、AstroVisBench)包含可执行的参考解决方案和单元测试以供验证。
-
图像未进行裁剪,而是使用完整的科学图表。元数据构建包括领域标签、任务类型(选择题、自由回答、代码生成)、模态标签和专家标注。该套件设计注重流程透明,详细描述见附录 B,未来版本将持续扩展。
方法
SciEvalKit 框架采用模块化、端到端的多模态科学基准测试流水线,分为四个独立层级:数据集、模型推理、评估与测试、报告与存储。这种分层架构确保了职责清晰,支持在多样科学任务中实现可扩展性和可复现性。框架核心设计强调统一的提示构建与模型预测接口,适用于纯文本、图像输入以及涉及图表、代码和符号表达的多模态科学输入。
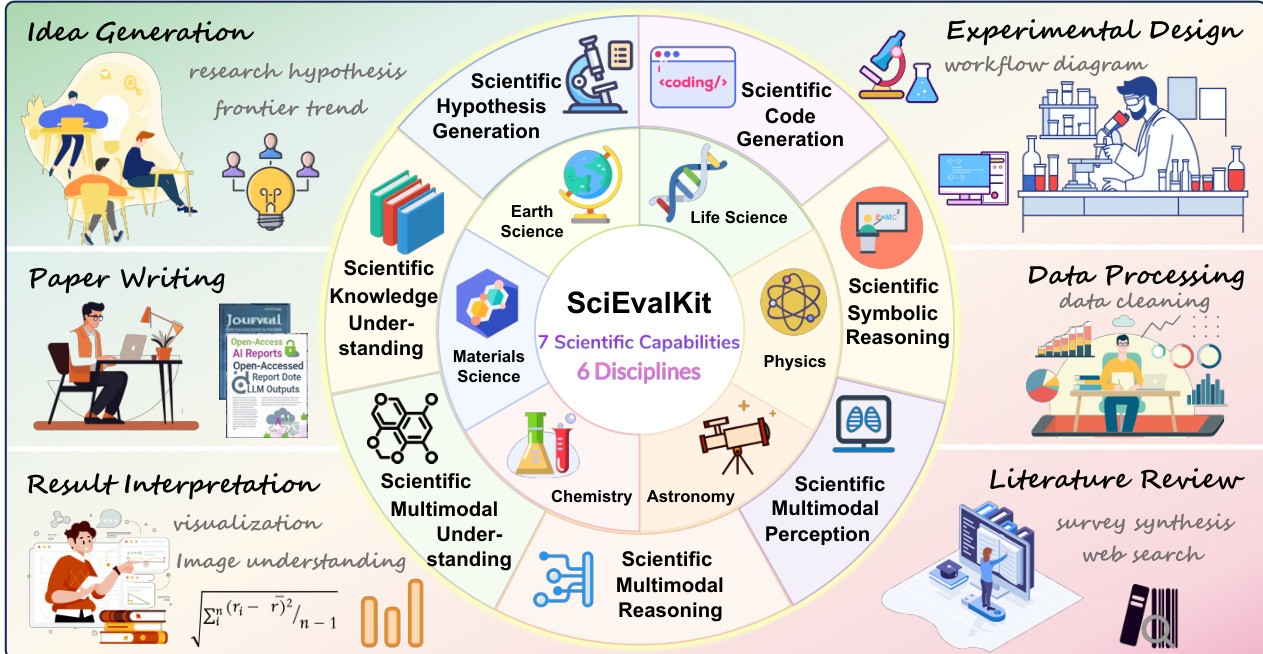
数据集层是数据摄入和任务定义的入口。其负责从 TSV 等来源加载结构化数据,并将原始任务数据——问题、图像、视频帧路径、代码片段和答案选项——转换为标准化的多模态消息表示。此转换由 build_prompt() 方法处理,该方法由继承自 TextBaseDataset、ImageBaseDataset 或 VideoBaseDataset 等基类的每个数据集类实现。这些基类提供统一的元数据加载、索引归一化和模态特定数据缓存接口。多模态消息以有序的类型化内容段列表表示,每个段明确声明其模态(如文本、图像、视频)和载荷。这种显式声明确保模型的一致解释。框架支持在需要时对视频或序列图像进行高级消息打包。此外,每个数据集类提供标准化的 .evaluate() 方法,接收模型预测并应用数据集特定的评分策略,可能包括精确匹配、选项提取、代码执行或基于大语言模型的判断。
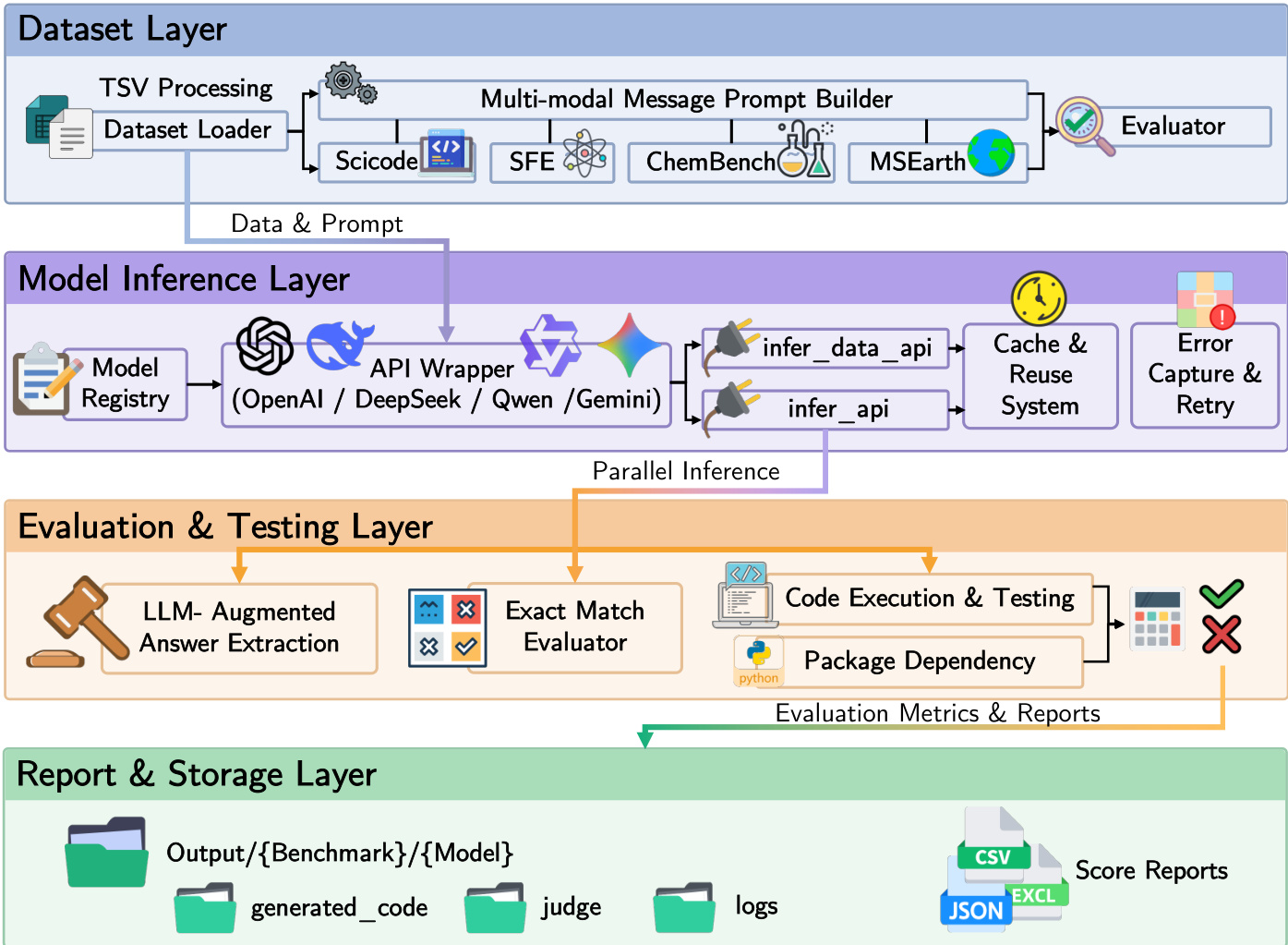
模型推理层在数据集层生成的结构化提示与模型输出之间进行协调。其负责模型实例化和推理执行。模型实例化由 build_model_from_config 函数管理,该函数从支持的视觉语言模型(VLM)注册表中解析模型元数据。每个模型对象暴露统一的 .generate(message, dataset) 接口,抽象底层执行方式——无论是通过 vLLM 或基于 PyTorch 的本地推理,还是 OpenAI、DeepSeek、Gemini、Anthropic 等基于 API 的云模型。推理工作流由 infer_data()、infer_data_api() 和 infer_data_job_video() 等函数协调,提供对批处理、并行词元生成、重试机制和容错的透明支持。这些函数从数据集提示构建消息,并以一致方式调用模型的 .generate() 方法,从而抽象后端执行、请求格式和批处理逻辑的差异。模型可选择性地通过检查 use_custom_prompt(dataset_name) 标志来覆盖提示格式,但仍遵循统一接口契约。
评估与测试层处理推理层生成的模型预测。它通过确定性路径与基于大语言模型增强的评估路径相结合,实现能力对齐的评分。框架提供多种评估工具,包括精确匹配、语义检索、数值评分和代码执行。对于代码执行任务(如科学编程),框架调用沙箱化的 Python 环境,以验证生成代码的计算正确性和视觉输出保真度。evaluate() 函数在所有数据集上标准化,根据任务类型应用适当的评分方法。该层还包含 build_judge() 函数,用于基于大语言模型的判断,为评估复杂或开放性回答提供灵活机制。评估流水线设计为模块化,允许研究人员在不修改核心推理或评分逻辑的前提下,集成新数据集或评估策略。
报告与存储层确保整个基准测试过程的可复现性和透明性。它管理所有输出的存储,包括预测结果、日志、推理轨迹、元数据和评估结果。框架遵循结构化文件命名规范,辅助函数如 get_pred_file_path()、prepare_reuse_files() 和 get_intermediate_file_path() 保证模型运行间的一致性。最终评估指标以 CSV、JSON 或 XLSX 等标准格式序列化,便于纵向比较和排行榜托管。该层提供从数据摄入到最终结果的完整审计追踪,使研究人员能够复现和验证实验。
实验
- 在五个科学推理维度上开展以能力为导向的评估:科学多模态感知、理解、推理、代码生成、符号推理和假设生成,得分通过各领域特定基准的平均值计算,以确保评估平衡。
- 采用混合评分范式,结合规则匹配、语义大语言模型判断和基于执行的验证,针对多种答案格式(选择题、代码、开放文本、填空)进行定制化处理。
- 在科学知识理解方面,顶级模型(Gemini-3-Pro、GPT-o3、GPT-5)得分较高(最高达 76.05),表明其具备强大的事实记忆和概念理解能力,但在代码生成和符号推理方面表现仍较低(如 Gemini-3-Pro:29.57,Qwen3-Max:43.97),揭示了在可执行和形式化推理方面的持续差距。
- Qwen3-Max 在代码生成和符号推理方面表现优于其他模型,展现出强大的形式化推理能力;而 Gemini-3-Pro 在整体科学文本和多模态性能上领先。
- 在多模态任务中,Gemini-3-Pro 在感知、理解与推理方面表现最为均衡,而 Qwen3-VL-235B-A22B 在感知方面突出,但在高层次理解与推理上落后,凸显跨模态整合能力的不足。
- 科学多模态推理在模型间表现出最高方差,成为最强的区分信号;而感知任务则更为饱和,对高级科学智能的指示性较弱。
- 基于执行的评估确认,即使顶级模型在生成正确、可执行的科学代码方面仍存在困难,凸显将科学意图转化为可靠计算流程的挑战。
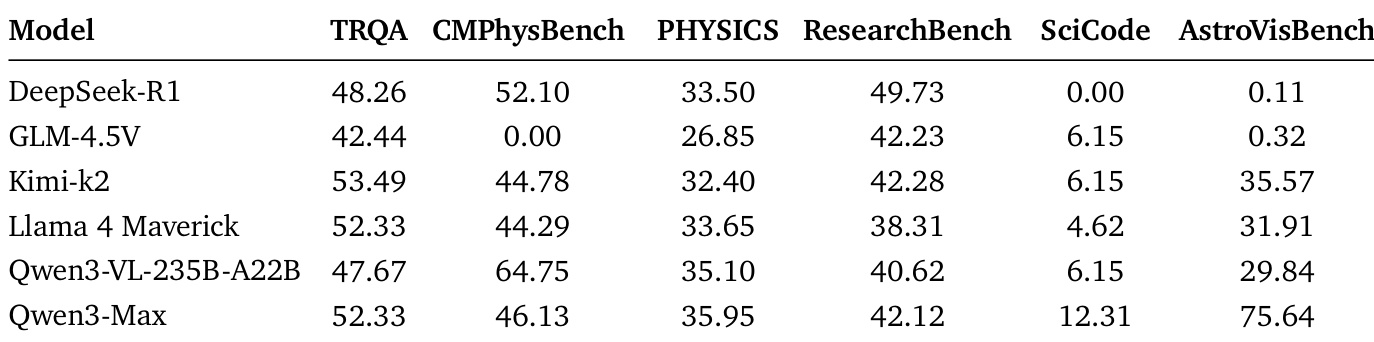
作者使用表格评估大语言模型在六个科学基准上的表现,包括 TRQA、CMPHysBench、PHYSICS、ResearchBench、SciCode 和 AstroVisBench。结果显示,Qwen3-Max 在 AstroVisBench 上得分最高,并在其他基准上表现具有竞争力,而 DeepSeek-R1 和 GLM-4.5V 表现较低,尤其在 SciCode 和 AstroVisBench 上。
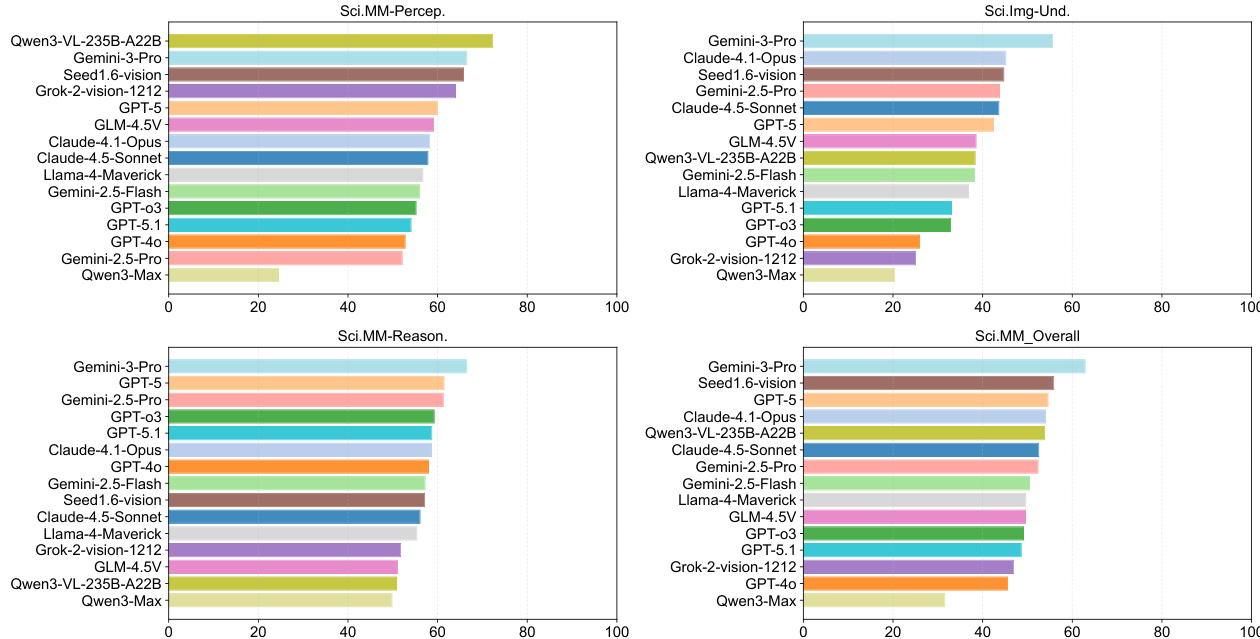
作者采用以能力为导向的评估框架,评估模型在科学多模态感知、理解与推理方面的表现。结果显示,Gemini-3-Pro 在所有三个维度上均取得最高分,尤其在多模态理解与推理方面表现突出;而 Qwen3-VL-235B-A22B 在感知方面领先,但在高层次推理任务中显著下降。
作者采用以能力为导向的评估框架,评估大语言模型在科学文本与多模态任务上的表现,结果显示模型在科学知识理解方面得分较高,但在科学代码生成与符号推理方面存在困难。表格显示,Gemini-3-Pro 和 GPT-5 在多数基准中领先,而开源权重模型如 Qwen3-Max 和 Qwen3-VL-235B-A22B 表现具有竞争力,尤其在代码生成与多模态感知方面,但在深层推理任务上仍显滞后。
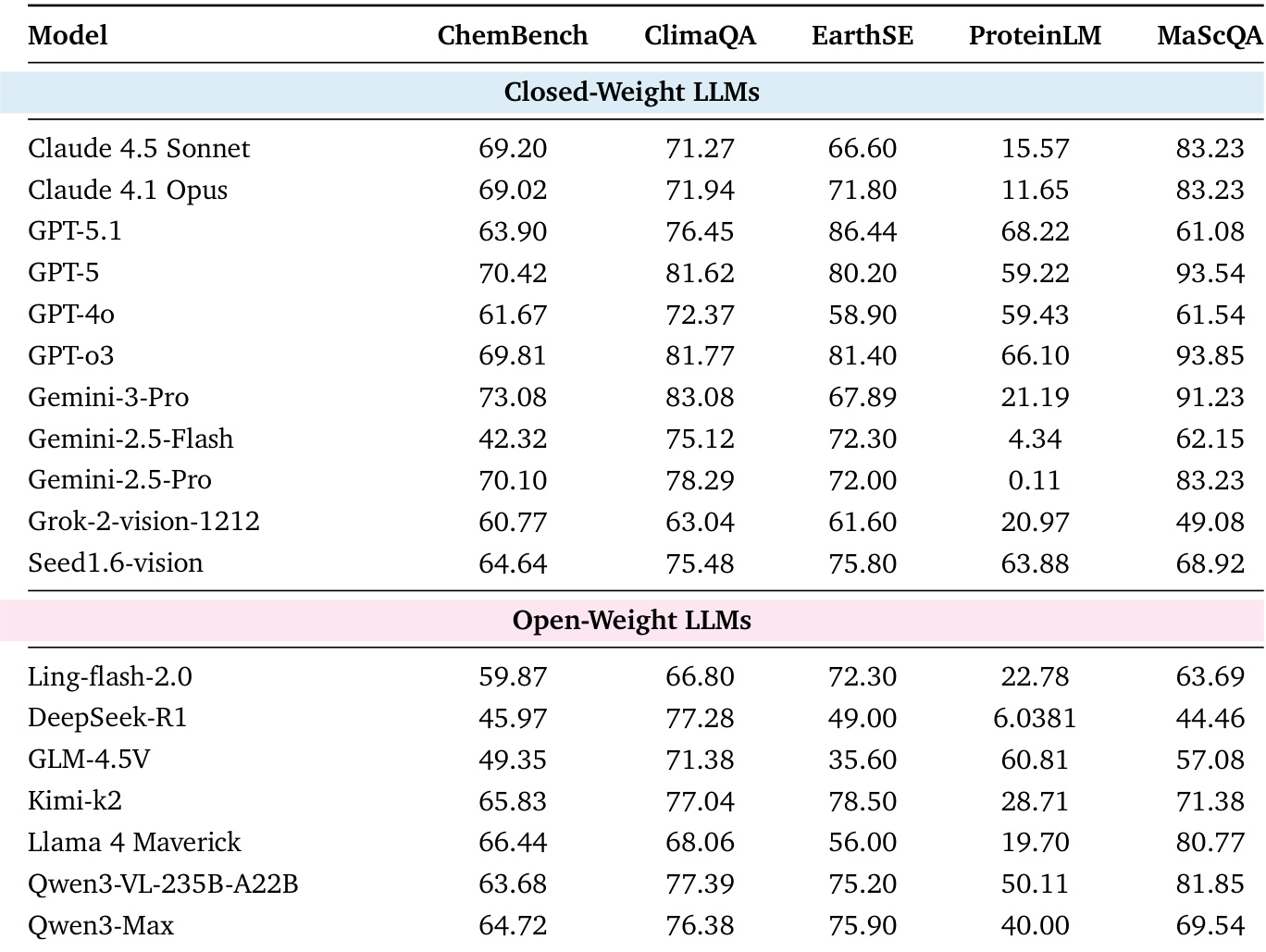
作者使用表格评估多模态语言模型在三个科学基准(SLAKE、SFE、MSearth)上的表现,重点关注视觉推理、基于代码的可视化和实体定位。结果显示,Qwen3-VL-235B-A22B 在 SLAKE 上得分最高,而 Gemini-3-Pro 在 SFE 和 MSearth 上领先,表明其在不同多模态任务中均表现优异。在开源权重模型中,Qwen3-VL-235B-A22B 在 SLAKE 上优于其他模型,但 Qwen3-Max 在所有基准上得分显著较低,凸显了专注于视觉感知的模型与侧重文本推理的模型之间的性能差距。
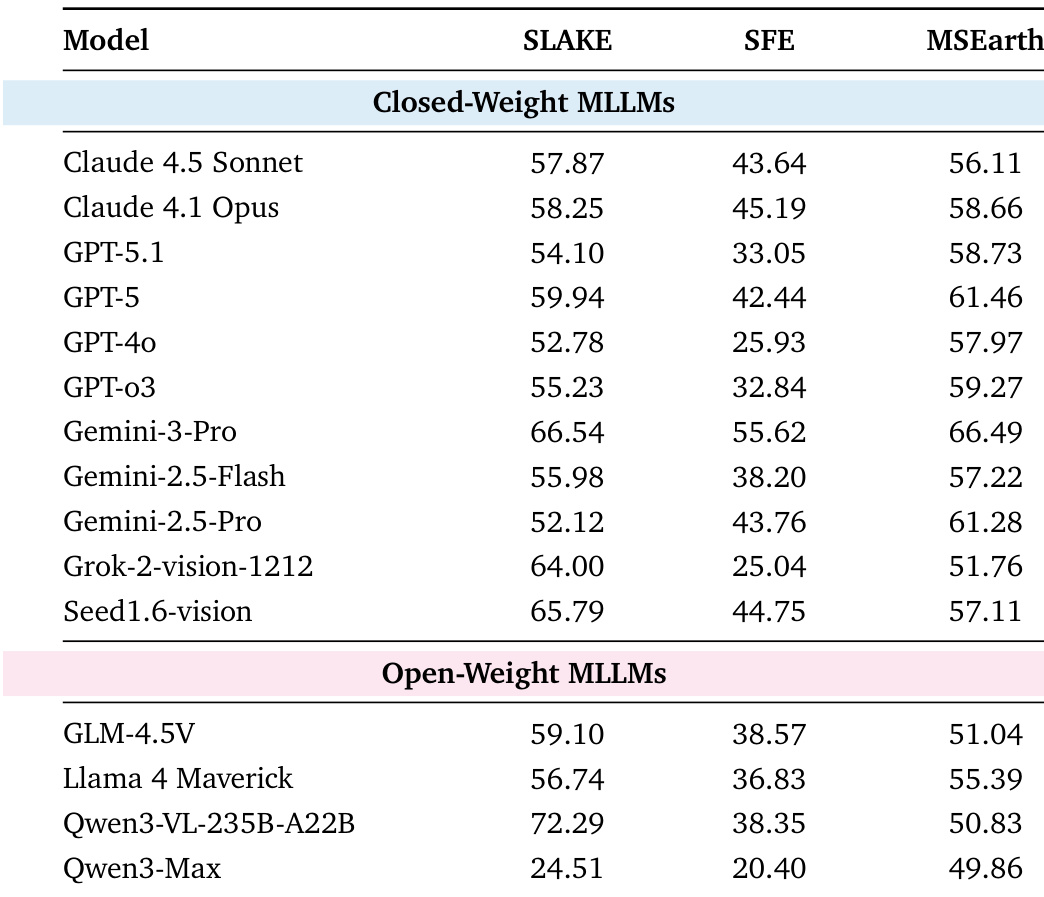
作者采用以能力为导向的评估框架,评估大语言模型在五项科学能力上的表现,表 2 展示了科学文本能力的评估结果。结果显示,Gemini-3-Pro 在大多数维度上得分最高,尤其在科学知识理解与假设生成方面表现突出,而代码生成仍是整体最弱的能力。在开源权重模型中,Qwen3-Max 表现具有竞争力,尤其在代码生成方面领先,并在其他文本类能力上取得优异成绩。