Command Palette
Search for a command to run...
HiStream:通过冗余消除流式传输实现高效高分辨率视频生成
HiStream:通过冗余消除流式传输实现高效高分辨率视频生成
摘要
高分辨率视频生成在数字媒体与影视制作中具有重要意义,但其实际应用受限于扩散模型固有的二次方复杂度,导致推理过程计算开销巨大,难以实用化。为解决这一问题,我们提出HiStream——一种高效的自回归生成框架,通过在三个维度上系统性地减少冗余:i)空间压缩:先在低分辨率下进行去噪,再利用缓存特征在高分辨率下进行精细化重构;ii)时间压缩:采用分块处理策略,结合固定大小的锚点缓存机制,确保推理速度稳定;iii)时间步压缩:对后续由缓存条件引导的分块仅施加较少的去噪步骤。在1080p基准测试中,我们的主模型(i+ii)在保持当前最优视觉质量的同时,相比Wan2.1基线实现了高达76.2倍的去噪加速,且质量损失可忽略不计。我们进一步推出的加速版本HiStream+综合应用了全部三项优化(i+ii+iii),相较基线实现107.5倍的加速,显著提升了生成效率,在速度与质量之间取得了极具吸引力的平衡,使高分辨率视频生成真正具备实用性与可扩展性。
一句话总结
Meta AI 与南洋理工大学研究人员提出 HiStream,一种高效的自回归框架,通过空间(双分辨率缓存)、时间(锚点引导滑动窗口)和时间步(非对称去噪)三个维度减少高分辨率视频生成中的计算冗余,在保持最先进的 1080p 视频合成视觉质量的同时,去噪速度比 Wan2.1 快 76.2-107.5×。
主要贡献
- 现有的基于 DiT 的视频生成模型因位置编码错位导致模糊问题,在高分辨率下存在计算瓶颈;而基于 UNet 的方法则面临感受野限制。
- HiStream 引入锚点引导滑动窗口进行时间处理,并结合双分辨率缓存与非对称去噪,实现固定大小的 KV 缓存使用和空间一致的分块生成,无需额外训练。
- 该框架通过流匹配在基于 DiT 的自回归基线(WAN-2.1)上实施一致性蒸馏,采用持久内容锚点等技术,在高分辨率视频合成中保持效率与质量。
引言
视频扩散模型已从基于 UNet 的架构转向可扩展的扩散 Transformer(DiT)以提升生成效果,但高分辨率合成仍受限于数据稀缺和计算成本。现有免调优方法主要针对 UNet 的感受野伪影等局限,却未能解决 DiT 特有的位置编码错位导致的高分辨率模糊问题;而两阶段超分辨率流程常牺牲细节保真度。尽管采用源自大语言模型的 KV 缓存技术优化时间注意力,推理速度依然缓慢。作者利用注意力沉降特性与因果重构,开发出免调优框架 HiStream,使 DiT 架构能直接高效生成高分辨率视频,且无需额外训练数据即可维持稳定的 KV 缓存。
方法
作者提出 HiStream——一种优化的自回归视频扩散框架,旨在解决高分辨率视频生成中的计算低效问题。其核心创新在于三种效率机制的协同组合:用于时间压缩的锚点引导滑动窗口、用于空间和时间步压缩的双分辨率缓存与非对称去噪,以及利用分辨率与时间冗余的渐进式去噪轨迹。
该框架基于一个将 N 帧视频联合分布分解为 p(x1:N)=∏i=1Np(xi∣x<i) 的自回归 diffusion 模型。生成以分块而非逐帧方式进行,每块均以先前上下文为条件。模型使用标准 diffusion 损失 LDM(θ)=Ex,t,ϵ[∥ϵ^θ(xt,t,c)−ϵ∥22] 进行训练,并通过流匹配进行一致性蒸馏优化:训练学生模型 fϕ 通过目标函数 LFM(ϕ)=Ep0(x0),pt(xt)[∥fϕ(xt,t,c)−(x0−xt)∥22] 直接将噪声输入映射至干净数据。
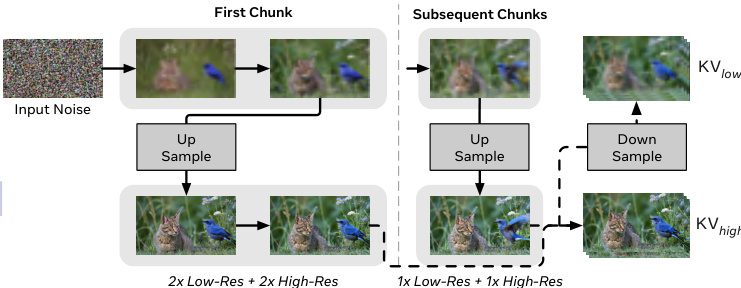
为管理空间复杂度,HiStream 引入双分辨率缓存(DRC)。去噪过程重构为两阶段轨迹:前两步在低分辨率下建立全局结构,随后上采样并执行两步高分辨率细化以恢复细节。该设计基于实证观察:当后续进行高分辨率细化时,早期去噪步骤对最终质量贡献甚微。为支持单网络内的分辨率切换,作者整合了 NTK 启发的缩放旋转位置嵌入,实现跨尺度的位置泛化。
参考框架图示的双分辨率去噪流程。首块经历完整的 2 次低分辨率 + 2 次高分辨率去噪路径,后续块则采用加速的 1 次低分辨率 + 1 次高分辨率路径。关键在于高分辨率细化后,输出被下采样并用于更新低分辨率 KV 缓存,确保下一块的空间一致性。这种双 KV 缓存机制避免了缓存特征与最终高分辨率输出的错位,维持时空连贯性。
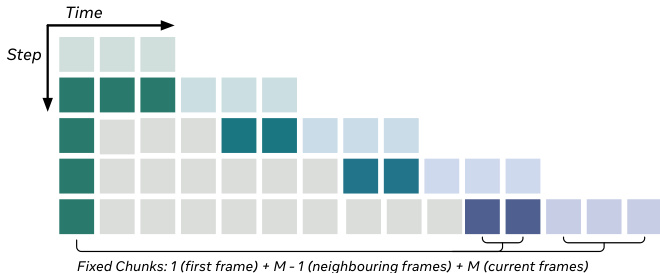
为提升时间效率,HiStream 采用锚点引导滑动窗口(AGSW)。每块生成仅依赖固定大小上下文:当前块(M 帧)、M-1 帧的局部历史及全局锚点(首帧),将最大注意力上下文限制在 2M 帧内,防止 KV 缓存无界增长。局部历史提供短程运动线索,首帧则作为"时间注意力沉降点",在无需全历史注意力的情况下维持长程场景一致性。
如下图所示,注意力窗口由固定锚点(首帧)、近期局部上下文和当前块组成,确保每步生成的计算成本恒定。
最后,作者提出非对称去噪以利用时间步冗余。首块经历完整的 4 步去噪以建立高质量锚点缓存;后续块受益于该缓存,仅需 2 步即可达到近最终质量。这种激进加速作为可选变体 HiStream+ 实现,其依据在于后续块继承了充分的结构信息,使完整去噪变得冗余。
实验
- 在 1080p 视频生成任务中评估 HiStream(空间与时间压缩),在保持视觉质量的同时,去噪速度比 Wan2.1 基线快 76.2×,并取得最先进的 VBench 分数。
- 测试 HiStream+ 变体(增加时间步压缩),速度比 Wan2.1 提升 107.5× 且质量损失极小,在 H100 GPU 上实现接近实时的 4.8 FPS 生成速度。
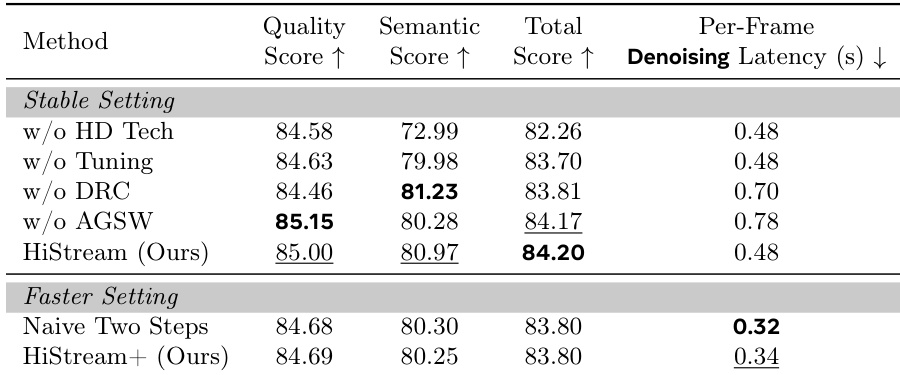
- 消融研究证实双分辨率缓存和锚点引导滑动窗口将延迟降至每帧 0.48 秒;用户研究显示 HiStream 在质量、对齐度和细节保真度上均优于基线。
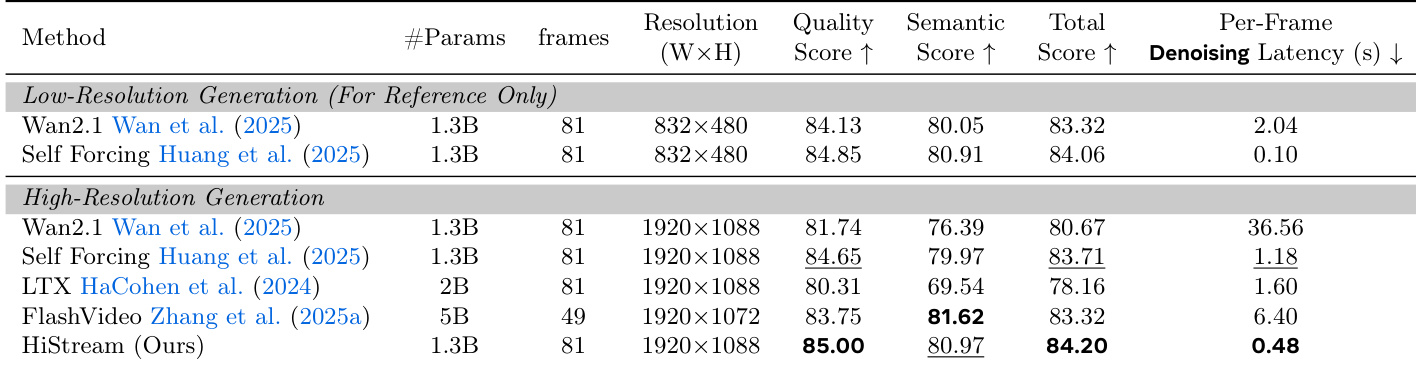
作者评估 HiStream 的消融变体发现:移除双分辨率缓存或锚点引导滑动窗口会使延迟分别升至 0.70 秒和 0.78 秒;而完整 HiStream 配置在每帧 0.48 秒下达到最高总分 84.20。在加速设置中,HiStream+ 将延迟降至 0.34 秒且质量损失极小,相比之下朴素两步法虽达 0.32 秒,却缺乏维持首块保真度的非对称去噪策略。
HiStream 相比 Self Forcing 与 FlashVSR 的两阶段超分辨率方法取得更高质量分数与总分,证明原生高分辨率生成具有更优的细节保真度。语义分数保持竞争力,表明尽管缺乏专用超分辨率后处理,生成内容仍与输入提示高度对齐。

作者使用 HiStream 生成 1920×1088 高分辨率视频,在各项对比方法中取得最高质量分数(85.00)和总分(84.20),同时保持最低的每帧去噪延迟(0.48 秒)。结果表明 HiStream 在视觉保真度与效率上均优于 Wan2.1、Self Forcing、LTX 和 FlashVideo 等基线,其延迟比 Wan2.1 快 76.2×。该模型还获得最佳语义分数(80.97),表明生成内容与输入提示高度一致。
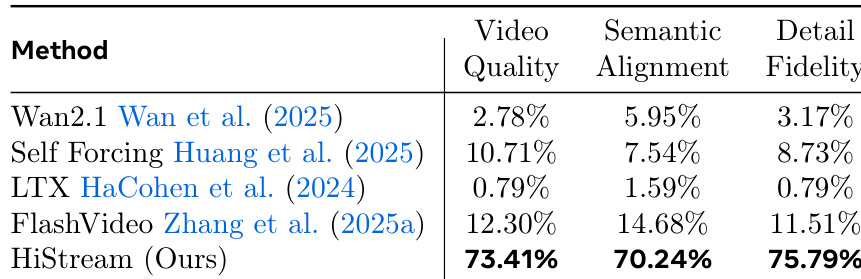
作者使用 HiStream 生成高分辨率视频,并通过用户偏好指标与多个基线对比。结果显示 HiStream 在视频质量(73.41%)、语义对齐(70.24%)和细节保真度(75.79%)上均显著胜出。这表明用户认为 HiStream 生成的视频质量更高、语义更准确、细节更丰富。