Command Palette
Search for a command to run...
超越记忆:一种多模态序数回归基准以揭示视觉-语言模型中的流行度偏差
超越记忆:一种多模态序数回归基准以揭示视觉-语言模型中的流行度偏差
Li-Zhong Szu-Tu Ting-Lin Wu Chia-Jui Chang He Syu Yu-Lun Liu
摘要
我们揭示了当前最先进的视觉-语言模型(VLMs)中存在显著的流行度偏差:在著名建筑上的准确率比普通建筑高出高达34%,表明这些模型更依赖记忆而非可泛化的理解能力。为系统性地研究这一现象,我们提出了该任务目前规模最大且开源的基准数据集——YearGuessr数据集。该数据集包含来自157个国家的55,546张建筑图像,每张图像均配有多种模态属性,包括连续的序数标注的建造年份(1001–2024年)、地理坐标(GPS数据)以及页面浏览量(作为流行度的代理指标)。基于该数据集,我们将建筑建造年份预测任务建模为序数回归,并引入考虑流行度感知的区间准确率度量方法,以量化这一偏差。我们构建的包含30余种模型(包括我们提出的YearCLIP模型)的基准测试结果表明,VLMs在流行且易被记忆的物体上表现优异,但在不为人知或未被识别的主体上则显著失准,暴露出其推理能力中的一个关键缺陷。项目主页:https://sytwu.github.io/BeyondMemo/
一句话总结
来自阳明交通大学的研究人员提出了包含55,000张建筑图像的YearGuessr数据集(含建造年份与流行度指标),以及通过序数回归和新型流行度感知准确率指标探究视觉-语言模型偏差的YearCLIP模型。其分析揭示VLMs在著名建筑上的准确率高出普通建筑34%,暴露出模型过度依赖记忆化而非可泛化的建筑理解推理能力。
主要贡献
- 本研究首次识别出视觉-语言模型中的关键流行度偏差:著名建筑的准确率比普通建筑高出34%,表明模型过度依赖记忆化而非可泛化的建筑主题推理能力。
- 为解决此问题,作者提出YearGuessr——目前规模最大的公开建筑年代预测基准数据集,包含来自157个国家的55,546张建筑图像,标注序数年份(1001–2024)、GPS数据及流行度指标,并引入新型流行度感知区间准确率指标用于序数回归评估。
- 其YearCLIP模型采用融合图像、GPS、建筑风格及推理提示的粗到精序数回归方法预测建造年份,跨30+模型的基准测试证实:尽管VLMs在记忆化样本上表现优异,但在冷门建筑上始终存在显著性能下降。
引言
提供的源文本为空。由于缺乏可分析的研究内容,无法总结技术背景、先前局限性或作者贡献。请提供相关研究段落以生成实质性摘要。
数据集
作者提出YearGuessr——一个完全源自维基百科和维基共享资源库(CC BY-SA 4.0或公共领域许可)的55,546张建筑图像年代估算基准数据集。关键子集细节:
- 构成:图像覆盖157个国家(美洲63.3%,欧洲22.5%),建造年份跨度1001–2024 CE,含GPS坐标、文本描述(中位数2,240字符)及年度页面浏览量(2023年7月–2024年)作为流行度代理指标。
- 清洗:原始9万张爬取数据经去重(−8,346)、CLIP建筑相关性过滤(−26,338)及轻量级测试集人工审核(−35),仅保留独特立面图像。
- 划分:按年代和大洲分层的60/20/20训练/验证/测试集(33,337/11,122/11,087),无跨集泄漏。
本文将建造年份预测定义为序数回归任务,利用页面浏览量揭示流行度偏差(例如VLMs在著名建筑上准确率高34%)。训练采用完整33k图像训练集(混合比例未说明),评估则在30+模型上使用流行度感知区间指标。
处理流程包括:GPS反向地理编码为国家标签、通过GPWv4.11推导城乡密度(<300, 300–1,500, >1,500人/km²)、基于描述文本的LLM分析标注翻新状态。未进行图像裁剪;元数据增强聚焦地理与时间背景以支持偏差分析。
方法
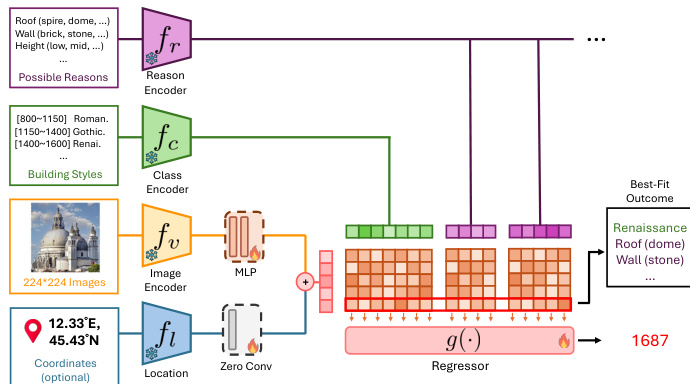
作者提出多分支粗到精架构YearCLIP,用于从建筑立面图像预测建造年份(可选融合GPS坐标)。该模型不仅能输出标量年份预测,还能生成基于建筑特征的人类可读推理依据。
处理流程始于输入阶段:224×224像素图像经冻结的CLIP图像编码器fv编码,生成原始视觉特征zvraw,再通过MLP优化为最终图像嵌入zv。若存在地理坐标,则经位置编码器fl(含MLP与可学习ZeroConv)生成位置嵌入zl。二者通过逐元素相加融合为联合输入嵌入zinput=zv+zl;若无坐标,则zv单独作为输入。
并行地,模型利用预定义建筑知识:类别编码器fc将七种粗粒度建筑风格(各关联历史时期,如罗马式:800–1150,巴洛克式:1600–1750)映射为固定嵌入zci;推理编码器fr将建筑属性库(如屋顶类型:尖顶、圆顶;墙体材料:砖石、石材)编码为嵌入zrik。
在粗粒度阶段,模型计算输入嵌入与各风格/推理嵌入的余弦相似度,得到相似度分数simci和simrik。这些分数拼接为单向量s,作为可训练回归器g(⋅)的输入。回归器输出七历史时期上的概率分布,最终年份预测y^通过时期中点的加权平均导出,并经可学习稳定性项δi调整:
y^=i=1∑kpi⋅1+δibi为生成推理依据,模型结合相似度分数与回归器对对应时期的注意力,评估各推理子类的重要性。选取前五推理依据(各以最显著子类表示),构成自然语言解释。
参考框架图,该图示展示了图像与位置编码器的集成、风格与推理的并行编码,以及最终融合多信号生成年份预测与推理依据的回归器。
实验
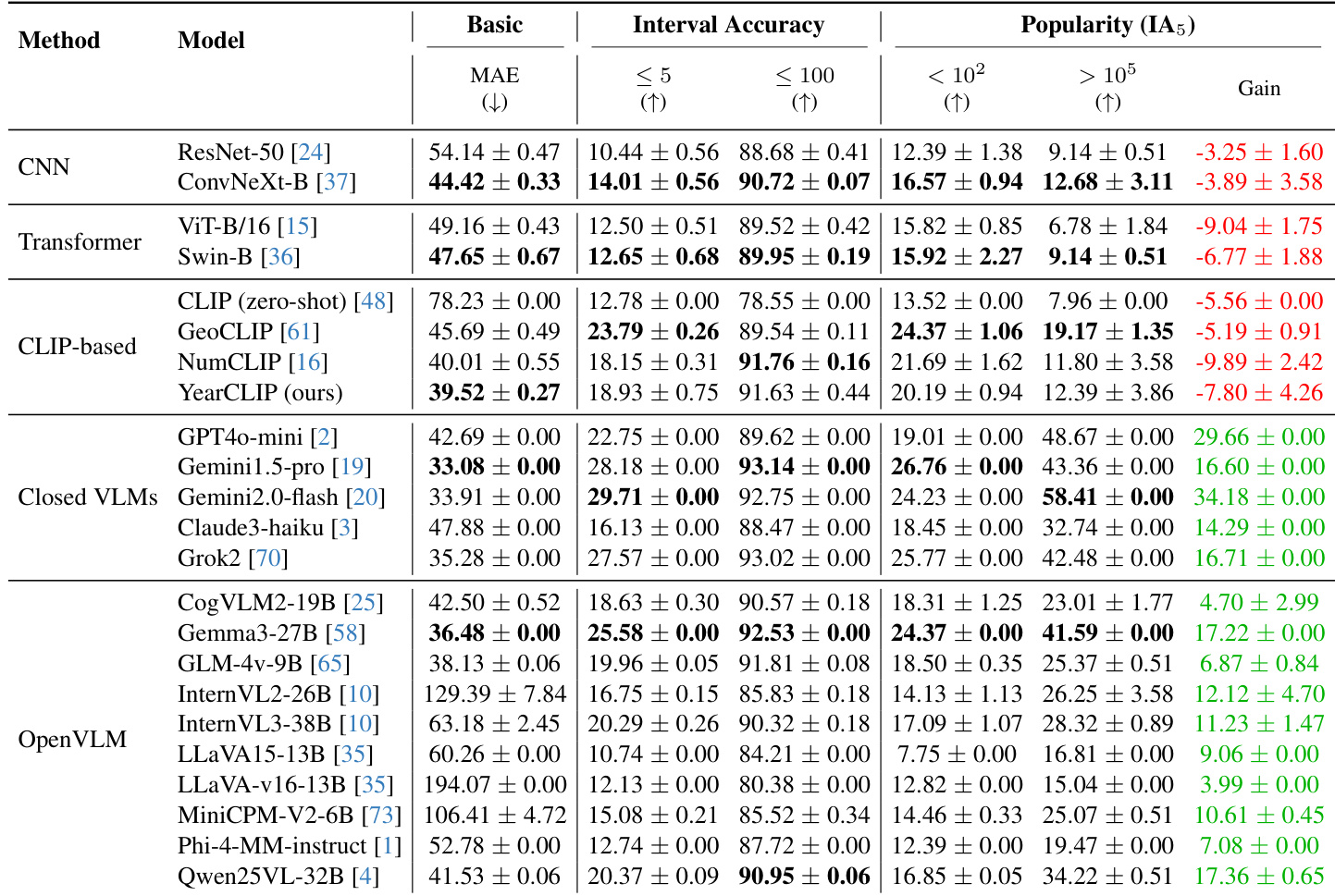
- YearCLIP在Year-Guessr测试集上实现39.52 MAE,较GeoCLIP(45.69 → 39.52)降低误差13.5%,且优于ConvNeXt-B(44.42 MAE)等CNN/Transformer基线模型,验证序数回归对细粒度预测的有效性。
- 闭源VLMs占据主导:Gemini1.5-Pro以33.08 MAE超越所有开源模型;Gemma3-27B为最佳开源模型(36.48 MAE)。
- 流行度分析显示:CNN/Transformer模型在标志性地标的性能下降(YearCLIP IA₅对高流行度建筑降低7.80%),而Gemini2.0-Flash在流行建筑上IA₅提升34.18%,表明记忆化偏差。
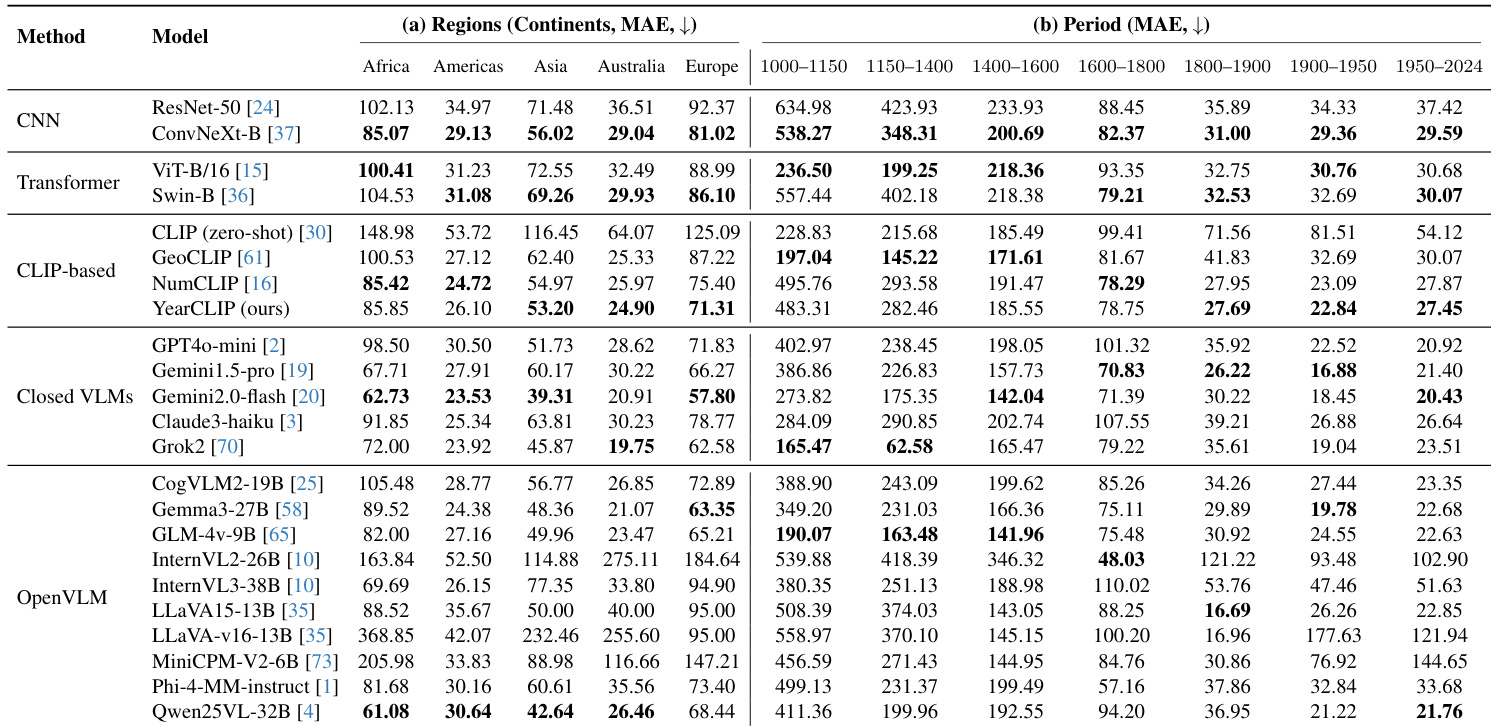
- 地理偏差普遍存在:Gemini2.0-Flash在美洲MAE为23.53,非洲达62.73;YearCLIP将此差距缩小至美洲MAE 26.10。时间偏差表现为古代时期性能骤降(如1000-1150年MAE 386.86 vs. 1900-1950年16.88)。
- 翻新状态影响准确率:未翻新建筑MAE最低(Gemini1.5-Pro: 20.66),重建结构升至57.36;半城市区域取得最佳密度结果(YearCLIP MAE 36.22)。
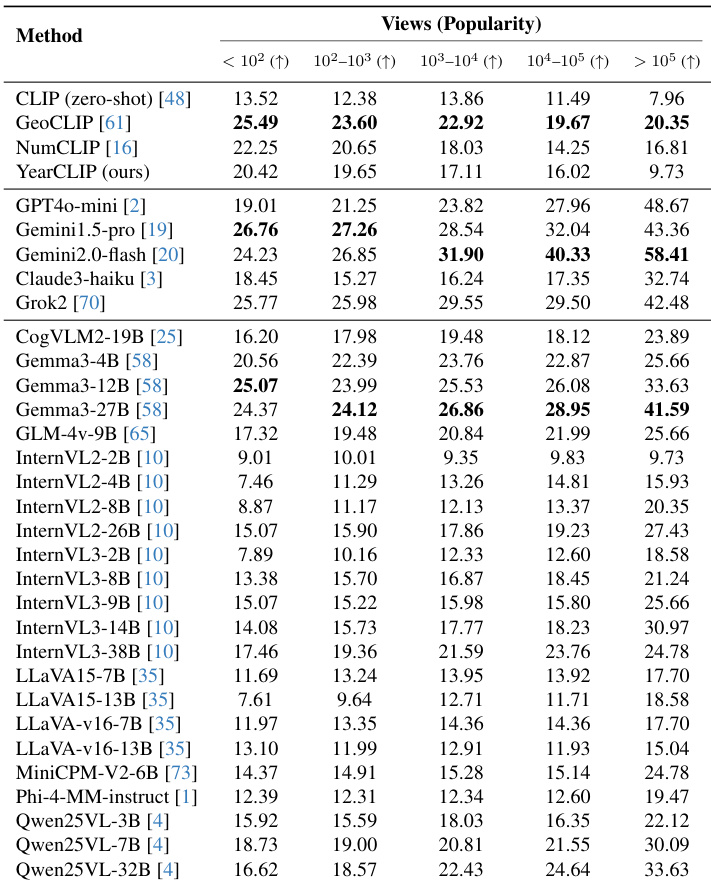
作者在五个流行度分组上评估多类视觉与视觉-语言模型,发现Gemini1.5-Pro等闭源VLMs在高流行度建筑上准确率急剧上升,表明显著流行度偏差。相比之下,CNN、Transformer及CLIP模型在流行地标上准确率下降,说明其因风格复杂性难以处理标志性建筑,而非依赖记忆化关联。所提YearCLIP在流行度各层级保持均衡性能,同时维持整体竞争力。
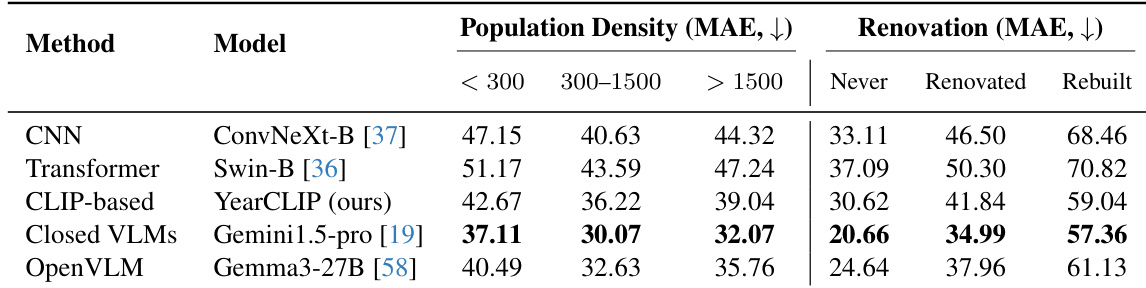
作者基于人口密度与翻新状态评估模型,发现半城市区域(300–1500人/km²)对多数模型产生最低MAE,而乡村与城市区域更具挑战性。翻新及重建建筑的MAE始终高于未翻新建筑,其中重建结构因原始建筑线索丢失最难判定年代。Gemini1.5-Pro在两类中均表现最佳,YearCLIP优于其他CLIP模型并在多数子组中匹配或超越开源VLMs。
作者跨五大洲评估模型性能,揭示持续地理偏差:模型在美洲与澳洲MAE最低,非洲与欧洲最高。YearCLIP等CLIP方法表现相对均衡,而Gemini等VLMs区域差异显著(非洲与亚洲误差明显更高),反映训练数据不平衡(数据集严重偏向美洲)。
作者评估模型在地理区域与历史时期的表现,发现持续性能差异:美洲与澳洲MAE最低,非洲与欧洲最高,反映数据集偏差。时间分析显示早期时期(如1000–1150年)MAE显著升高,所有模型均难以处理古代建筑;1900–2024年因数据丰富与风格清晰性能明显提升。YearCLIP与Gemini2.0-flash区域表现相对均衡,但所有模型对1600年前建筑均存在强烈时间退化。
作者评估23个模型的建筑年代估算能力,发现Gemini1.5-Pro(MAE 33.08)等闭源VLMs误差最低,而YearCLIP(MAE 39.52)优于CNN/Transformer基线并通过序数 regression 较GeoCLIP提升13.5%。结果表明VLMs存在强流行度偏差:高流行度建筑性能提升(如Gemini2.0-Flash增益+34.18%)可能源于记忆化关联而非建筑推理;CNN与CLIP模型在流行地标上准确率则呈下降趋势。