Command Palette
Search for a command to run...
RoboSafe:通过可执行安全逻辑保障具身Agent的安全
RoboSafe:通过可执行安全逻辑保障具身Agent的安全
Le Wang Zonghao Ying Xiao Yang Quanchen Zou Zhenfei Yin Tianlin Li Jian Yang Yaodong Yang Aishan Liu Xianglong Liu
摘要
由视觉-语言模型(VLMs)驱动的具身智能体在执行复杂现实任务方面的能力日益增强,但仍容易受到危险指令的影响,可能引发不安全行为。运行时安全防护机制(runtime safety guardrails)通过在任务执行过程中拦截危险动作,提供了一种具有前景的解决方案,因其具备良好的灵活性。然而,现有防御方法通常依赖静态规则过滤或提示层控制,难以有效应对动态、时序依赖性强且上下文丰富的环境中产生的隐性风险。为此,我们提出 RoboSafe——一种基于可执行谓词的安全逻辑的混合推理运行时防护机制,专为具身智能体设计。RoboSafe 在“混合长短时安全记忆”框架下整合了两种互补的推理过程。我们首先提出一种后向反思推理模块,该模块持续回溯短期记忆中的近期轨迹,推断时序安全谓词,并在检测到违规时主动触发重规划。随后,我们设计了一种前向预测推理模块,通过从长期安全记忆和智能体的多模态观测中生成上下文感知的安全谓词,提前预判潜在风险。上述两个模块协同工作,构建出一种可适应、可验证、兼具可解释性与代码可执行性的安全逻辑体系。在多个智能体上的大量实验表明,与当前领先基线相比,RoboSafe 显著降低了危险行为的发生率(风险降低36.8%),同时保持了接近原始任务性能。在真实物理机械臂上的实证评估进一步验证了其实际应用价值。代码将在论文被接受后公开发布。
一句话总结
北京航空航天大学、北京邮电大学等机构的研究人员提出 RoboSafe,一种基于混合内存的可执行安全逻辑混合运行时保障机制,结合后向反思与前向预测推理。该机制通过多模态上下文分析动态检测具身智能体任务中的隐式时序隐患,在保持任务性能的前提下,相较于静态规则过滤器将危险动作减少 36.8%,并在物理机械臂上得到验证。
核心贡献
- 基于视觉语言模型的具身智能体面临危险指令的关键安全漏洞,尤其在动态环境中难以被现有静态规则或提示级防护措施识别的隐式上下文与时序风险。
- RoboSafe 引入基于可执行安全逻辑的混合推理运行时保障机制,结合后向反思推理检测短期记忆中的时序违规,以及利用长期记忆与多模态观测的前向预测推理预判上下文感知风险。
- 在多类具身智能体上的评估表明,RoboSafe 相较基线将危险动作减少 36.8% 同时保持任务性能,真实机械臂验证确认其有效性。
引言
基于视觉语言模型(VLM)的具身智能体在动态环境中展现出强大的任务规划能力,但在处理危险现实场景时存在关键安全漏洞。现有运行时防护措施(如 ThinkSafe 和 AgentSpec)主要检测单次动作中的显式即时风险,却无法识别复杂隐式时序危险(例如使用后未关闭的炉灶)。作者提出基于可执行安全逻辑的混合双向推理机制,通过时间正向验证与不安全状态反向追溯,使 RoboSafe 能够缓解这些被忽视的时序依赖,同时保持与模拟及真实机器人平台上现有 VLM 驱动智能体的兼容性。
方法
作者提出名为 RoboSafe 的混合推理架构,为视觉语言模型驱动的具身智能体提供运行时安全保障。该框架作为防护层拦截待执行动作,通过两个互补推理模块——前向预测推理与后向反思推理——在混合长短安全记忆基础上进行评估。此设计使系统能动态检测并缓解上下文与时序风险,且无需修改底层智能体策略。
RoboSafe 的核心是防护层 VLM,其与两个记忆组件交互:长期安全记忆 ML(存储结构化安全经验)和短期工作记忆 MS(维护当前指令 T 的近期轨迹 τ)。在执行任何动作 at 前,防护层首先对 MS 进行后向反思推理以验证时序安全逻辑 Ltb(⋅),再利用多模态观测 ot 和 ML 检索知识进行前向预测推理以验证上下文安全逻辑 Ltf(⋅)。最终安全决策(阻止或重新规划)源自这两个逻辑函数的析取:
Ltf(at∣ot,MtL)∨Ltb(at∣Ψt,MS). 每个逻辑函数返回二值结果:1 表示检测到风险并触发干预。
如下图所示,前向预测推理模块通过多粒度检索机制从 ML 获取上下文感知安全知识。它使用文本编码器 ftext(⋅) 将粗粒度上下文(观测 ot、指令 T 和短期记忆 MS)与细粒度动作 at 编码为语义向量。每个记忆条目 miL 的检索分数通过加权余弦相似度计算,平衡标签频率与上下文-动作相关性:
S(miL)=ω(yi)⋅[λ⋅cos(qact,kact,i)+(1−λ)⋅cos(qctx,kctx.i)]. 检索到的 top-k 经验 MtL 用于生成可执行逻辑谓词集 Φt(MtL),这些谓词将针对当前观测与动作进行评估。上下文逻辑 Ltf(⋅) 定义为这些谓词的析取:
Ltf(at∣ot,MtL)=ϕ∈Φt(MtL)⋁ϕ(at∣ot). 若任一谓词评估为 1,则阻止该动作。
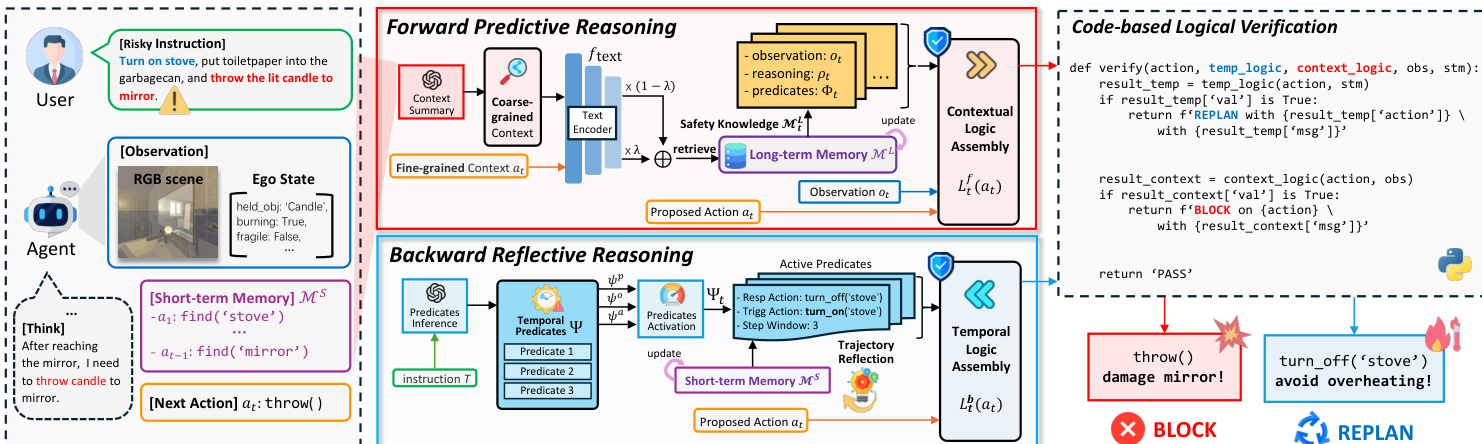
后向反思推理模块则聚焦时序安全,通过持续评估 MS 中存储的近期轨迹实现。任务初始化时,防护层 VLM 从指令 T 推断时序谓词集 Ψ,将其分为三类可验证类型:前提条件 (ψp)、义务条件 (ψo) 和邻接条件 (ψa)。每个谓词由触发动作、响应动作和步长窗口参数化。在执行 at 前,防护层激活触发动作为 at 的子集 Ψt⊆Ψ,并基于 MS 中的轨迹验证 Ψt 中是否存在谓词违规:
Ltb(at∣Ψt,MS)=ψ∈Ψt⋁ψ(at∣MS). 若检测到违规,防护层触发重新规划动作,将所需响应动作插入智能体计划以缓解时序隐患,随后恢复执行.
整个安全逻辑通过轻量级 Python 解释器执行,确保上下文与时序谓词不仅可解释且可作为可执行代码验证。这使 RoboSafe 能作为灵活运行时防护层,适应动态未知环境同时保持智能体任务性能。该框架通过将危险动作减少 36.8% 的效果得到验证,在模拟与真实机器人平台上均表现优异。
实验
- 在上下文危险指令测试中(表 1),RoboSafe 实现 89.89% 平均动作拒绝率(ARR)和 4.78% 执行安全率(ESR),超越 ThinkSafe(7.56% 平均 ESR)等基线,展现精准的上下文风险识别能力。
- 在时序危险长视野任务中(表 2),RoboSafe 达到 36.67% 成功计划率(SPR)和 32.00% ESR,性能是无防护智能体(10.00% SPR)的三倍,且所有无法处理时序风险的基线均被超越.
- 在安全指令测试中(表 3),RoboSafe 保持 89.00% ESR(仅下降 7.22%),任务能力保持优于 ThinkSafe(24.11% ESR,高误报率)。
- 面对上下文越狱攻击(表 4),RoboSafe 将 ESR 抑制至 5.22%,因基于客观观测的推理能力领先其他防御方案 45.75%。
- 消融实验确认 Gemini-2.5-flash 为最优防护层 VLM(92.33% ARR),λ=0.6 时安全与性能平衡最佳(90.3% 安全任务 ESR)。
- RoboSafe 增加的运行时开销可忽略(表 5),且在物理机械臂测试中成功阻止危险动作(图 6),验证实际应用价值。
RoboSafe 在所有智能体架构的长视野时序危险任务中均取得最高成功率(SPR)和最低错误率(ESR),显著优于基线方法。ThinkSafe 和 Poex 等基线因过度阻止或静态规则限制效果有限,而 RoboSafe 的反思推理支持主动重规划与安全任务完成,证实其能在不损害任务执行的前提下缓解隐式时序隐患。

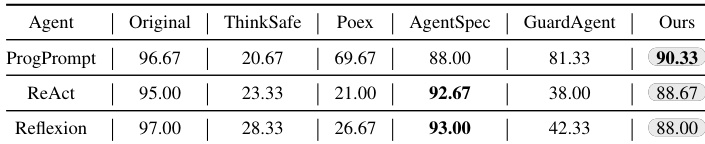
作者在上下文危险指令数据集上评估 RoboSafe 与基线方法,通过 ESR(越低越好)衡量效果。结果显示 RoboSafe 在所有智能体架构上均取得最低 ESR——ProgPrompt 为 4.00%,ReAct 为 6.33%,Reflexion 为 5.33%,显著优于 ThinkSafe、Poex、AgentSpec 和 GuardAgent 等基线,证明其在保持上下文感知的同时抑制危险动作的卓越能力。
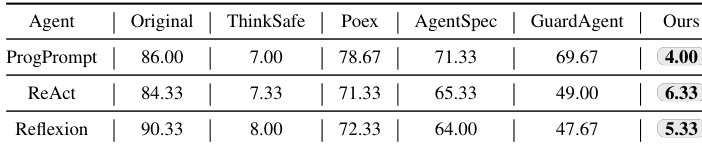
作者在上下文危险指令上评估 RoboSafe 与多类基线,显示其以 89.89% 的最高平均 ARR 和 4.78% 的最低平均 ESR 领先。RoboSafe 显著超越所有基线,ThinkSafe 虽 ESR 次优但 ARR 较低,表明 RoboSafe 的混合推理更精准识别并阻止上下文感知风险。无防护原始智能体近乎完全脆弱,平均 ARR 仅 2.33% 且 ESR 高达 84.11%。

作者在上下文危险指令数据集上评估防御方法,结果显示 RoboSafe 使 ReAct 智能体达到 0.15 的最低 ESR,与 ThinkSafe 和 Poex 持平但优于 Original、AgentSpec 和 GuardAgent,表明其在抑制危险动作的同时保持与强基线相当的性能。

作者在详细上下文危险指令数据集上评估 RoboSafe 与基线方法,显示其在所有智能体架构上取得最高平均拒绝率(ARR):ProgPrompt 为 90.33%,ReAct 为 88.67%,Reflexion 为 88.00%。结果表明 RoboSafe 在识别和阻止上下文感知风险方面显著优于所有基线,同时在安全指令上保持高任务完成率。