Command Palette
Search for a command to run...
T2AV-Compass:面向文本到音频视频生成的统一评估
T2AV-Compass:面向文本到音频视频生成的统一评估
摘要
文本到音频视频(Text-to-Audio-Video, T2AV)生成旨在从自然语言中合成时序连贯的视频与语义对齐的音频,然而其评估体系仍显零散,普遍依赖单模态指标或范围有限的基准测试,难以全面反映跨模态对齐、指令遵循能力以及在复杂提示下的感知真实感。为解决这一局限,我们提出T2AV-Compass——一个面向T2AV系统全面评估的统一基准。该基准包含500个多样且复杂的提示,通过基于分类体系的构建流程生成,以确保语义丰富性与物理合理性。此外,T2AV-Compass引入了一套双层级评估框架:在客观层面,结合信号级指标,对视频质量、音频质量及跨模态对齐程度进行量化评估;在主观层面,采用多模态大语言模型(MLLM)作为评判者(MLLM-as-a-Judge)的协议,对指令遵循能力与感知真实感进行综合判断。对11个代表性T2AV系统的广泛评估表明,即便表现最优的模型在人类水平的真实感与跨模态一致性方面仍存在显著差距,尤其在音频真实感、细粒度时序同步、指令理解等方面存在持续性失败。这些结果揭示了未来模型仍有巨大提升空间,同时凸显了T2AV-Compass作为一项具有挑战性与诊断价值的测试平台,在推动文本到音频视频生成技术发展中的重要作用。
一句话总结
南京大学、快手科技与中国科学院的研究人员提出T2AV-Compass,这是一个统一的基准测试框架,采用500个复杂提示词和双层级评估体系——融合客观信号指标与大语言模型(MLLM)作为裁判的评估方法——严格评估文本到音视频生成中的跨模态对齐、指令遵循和感知真实感,揭示了11个最先进模型在真实感和同步性方面的关键缺陷。
核心贡献
- 现有的文本到音视频(T2AV)评估方法分散且碎片化,依赖单模态指标,无法在复杂提示词下评估跨模态对齐、指令遵循和感知真实感。T2AV-Compass通过基于分类法的生成流程构建500个语义丰富且物理合理的多样化复杂提示词,建立统一基准测试框架。
- 该基准测试引入双层级评估框架,结合用于视频/音频质量和跨模态对齐的客观信号级指标,以及采用细粒度问答检查清单和违规检测的MLLM裁判协议,以增强可解释性的方式评估高级语义逻辑、指令遵循和真实感。
- 对11个最先进T2AV系统的广泛测试(包括Veo-3.1和Kling-2.6等专有模型)揭示了音频真实感、细粒度同步性和指令遵循方面的关键缺陷。结果证实即使顶级模型也远未达到人类水平,凸显该领域存在显著改进空间。
引言
文本到音视频(T2AV)生成技术通过自然语言描述合成时序连贯的视频和语义同步的音频,对沉浸式媒体创作至关重要,但现有评估方法碎片化,无法在复杂提示词下评估跨模态对齐、指令遵循和感知真实感。先前基准测试依赖单模态指标或范围狭窄的测试,忽略了画外音、物理因果关系和多源音频混合等细粒度约束,导致无法全面评估模型性能。作者提出T2AV-Compass统一基准测试框架,包含500个基于分类法的复杂提示词和双层级评估体系:结合视频/音频质量的客观信号指标与用于主观真实感和指令遵循的MLLM裁判协议。对11个最先进系统的评估揭示了持续存在的音频真实感瓶颈,凸显该框架在暴露未来研究关键缺陷方面的诊断价值。
数据集
作者使用T2AV-Compass——一个专为文本到音视频(T2AV)评估设计的500提示词基准测试集,通过两条互补路径构建:
-
社区收集提示词(400条):
- 从VidProM、Kling AI社区、LMArena和Shot2Story聚合,以捕捉多样化用户意图。
- 通过语义去重(使用all-mpnet-base-v2嵌入的余弦相似度≥0.8)和平方根采样平衡高频/小众主题。
- 借助Gemini-2.5-Pro增强描述密度(添加电影摄影约束、运动动态和声学细节),经人工审核剔除静态/逻辑错误场景。
-
真实视频逆向生成(100条):
- 源自2024年10月后YouTube片段(4–10秒,720p分辨率),避免数据泄露。
- 筛选时空完整性(无水印/快速剪辑)、音视频复杂度(1–4声音层,30%语音)及主题多样性(现代生活、科幻等)。
- 通过Gemini-2.5-Pro密集描述转换为提示词,经人工验证确保与真实视频动态一致。
该数据集仅用于评估而非训练,采用双层级框架:
- 客观指标评估单模态质量(视频美学、音频真实感)和跨模态对齐(时序同步、语义一致性)。
- 主观MLLM裁判评估使用基于提示词构建的结构化检查清单,覆盖指令遵循(通过槽位提取)和感知真实感(如物理合理性)。
关键处理包括:
- 将YouTube片段裁剪为5–10秒有意义的语义单元。
- 使用JSON模式将提示词转换为分层元数据(如电影摄影、声音类型),实现系统化评分。
- 通过高token数(模拟真实查询)和细粒度挑战确保复杂性(如72.8%提示词含重叠音频事件)。
方法
作者为文本到音视频(T2AV)生成开发双层级评估框架,系统化评估客观保真度和主观语义对齐。该框架核心T2AV-Compass将评估分解为两个互补层级:客观指标和推理驱动的主观判断。
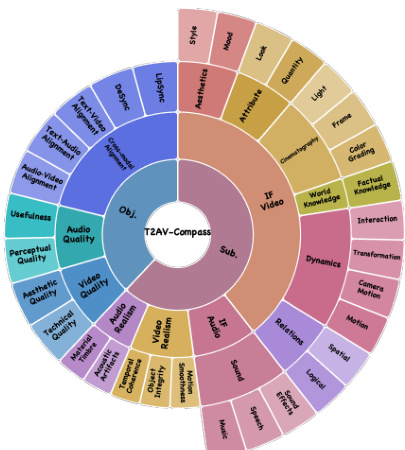
在客观层级,性能通过三大支柱衡量:视频质量、音频质量和跨模态对齐。这些进一步细分为颗粒化子维度:视频真实感的运动平滑度评分(MSS)、物体完整性评分(OIS)和时序连贯性评分(TCS);音频真实感的声学伪影评分(AAS)和材质-音色一致性(MTC);以及量化模态间同步的对齐指标。参考框架示意图(按层级关系和功能分组排列的同心环结构)可直观理解这些维度。
主观评估层采用MLLM裁判协议,强制要求评分前进行显式推理。该协议沿两条路径运行:指令遵循(IF),通过源自输入提示词的细粒度问答检查清单验证提示词遵循度;感知真实感(PR),独立于提示词诊断物理和感知违规。问答生成流程始于从VidProM或LMArena等模型获取提示词,经过滤、LLM重写和人工精炼生成最终提示词集。由此集为每个维度(如外观、数量、运动或音效)自动生成问答检查清单,通过槽位提取和维度映射实现,并经人工验证确保保真度。真实感路径进一步整合时序连贯性检查(TCS)和材质-音色一致性(MTC)以评估物理合理性。
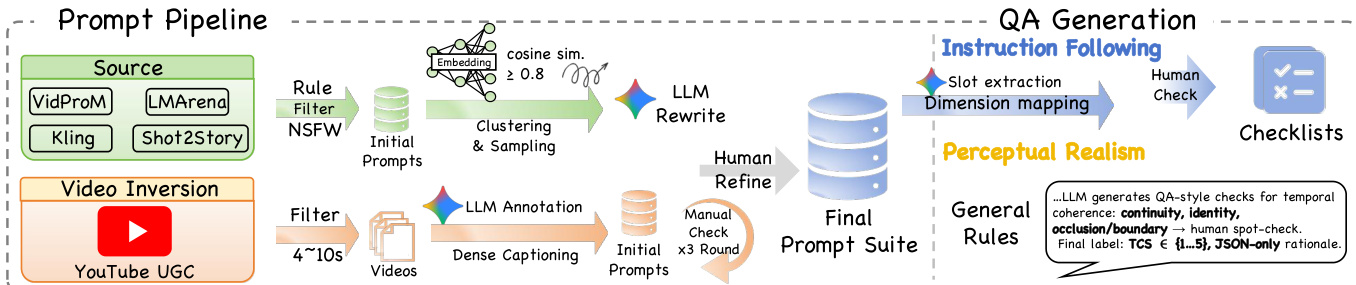
每个问答检查清单设计为针对特定子维度的二元(是/否)问题——例如验证"红色木桌"是否出现(外观),或"角色从左向右跑"是否发生(运动)。这些问题按维度(属性、动态、电影摄影等)生成,且可从生成视频客观验证。框架强制实施推理优先协议:裁判必须在分配5分制评分前阐明推理依据,提升可解释性并实现精准错误归因。这种双路径评估确保技术保真度和高级语义连贯性均得到严格检验。
实验
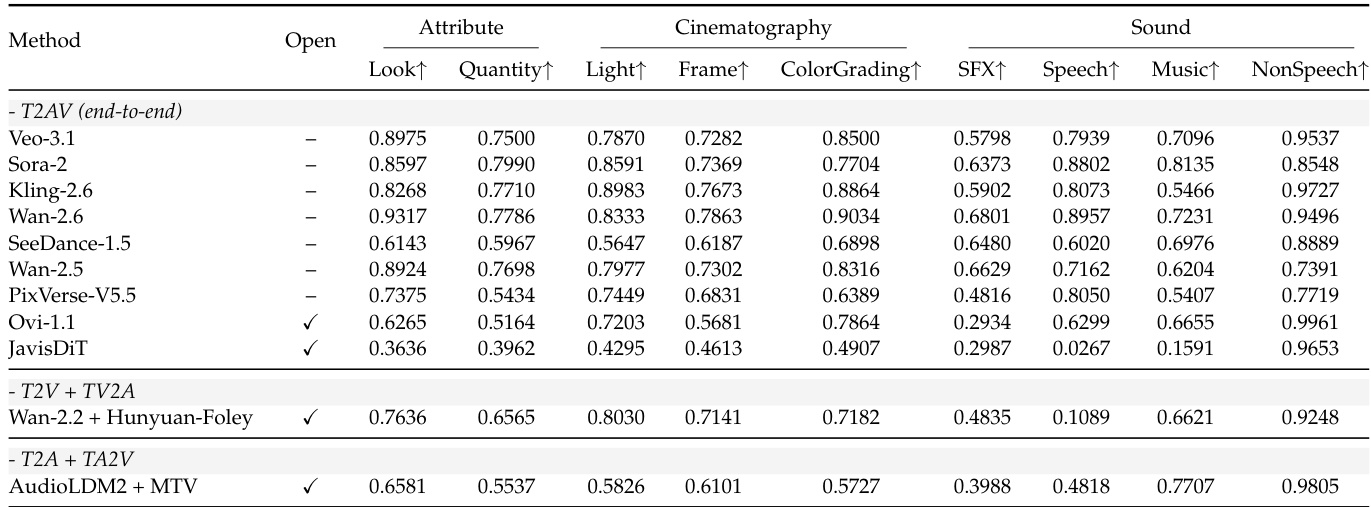
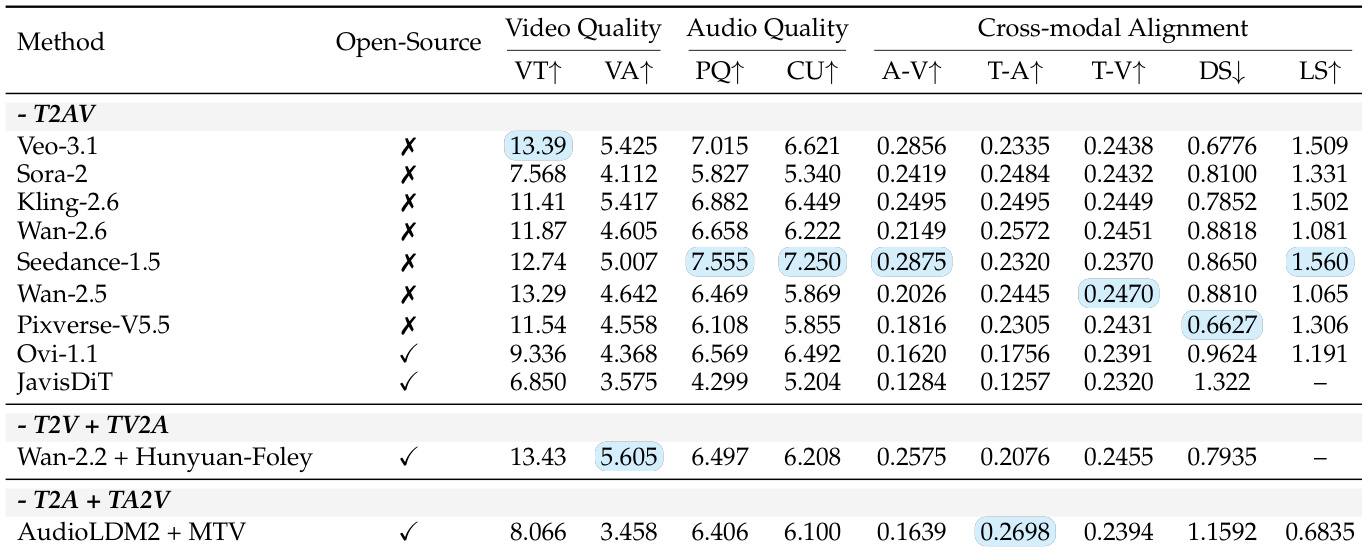
- 使用覆盖视频质量(VT, VA)、音频质量(PQ, CU)和跨模态对齐(T-A, T-V, A-V, 时序同步)的客观指标评估11个T2AV系统。
- 闭源模型(如Veo-3.1, Sora-2)在所有客观指标和语义评估中均超越开源模型。
- Veo-3.1综合平均分最高,但在音频真实感方面存在显著缺陷,凸显行业瓶颈:Seedance-1.5在此项仅得53.84分,多数模型停滞在30分区间。
- 组合管道(Wan-2.2 + HunyuanFoley)在视频真实感方面表现卓越,超越所有端到端模型,展现更优的单模态保真度。
- Veo-3.1和Wan-2.5在视觉指令遵循(尤其是动态维度)领先,而Sora-2在时序连贯性方面落后,尽管其在静态维度(如世界知识)表现强劲。
- MTC(材质-音色一致性)成为最具挑战的音频维度,Veo-3.1表现均衡且高位,Sora-2在OIS/TCS强劲但AAS薄弱。
作者在细粒度指令遵循维度评估多个文本到视听模型,发现Veo-3.1和Wan-2.5等端到端闭源模型在动态、关系和世界知识方面持续优于开源及组合系统。Wan-2.2 + HunyuanFoley等组合管道在美学和关系等特定领域表现具竞争力,但通常在时序和交互连贯性方面落后。Ovi-1.1和JavisDiT等开源模型在几乎所有维度得分显著偏低,尤其在运动和变换方面,表明处理复杂时序和结构指令仍存挑战。
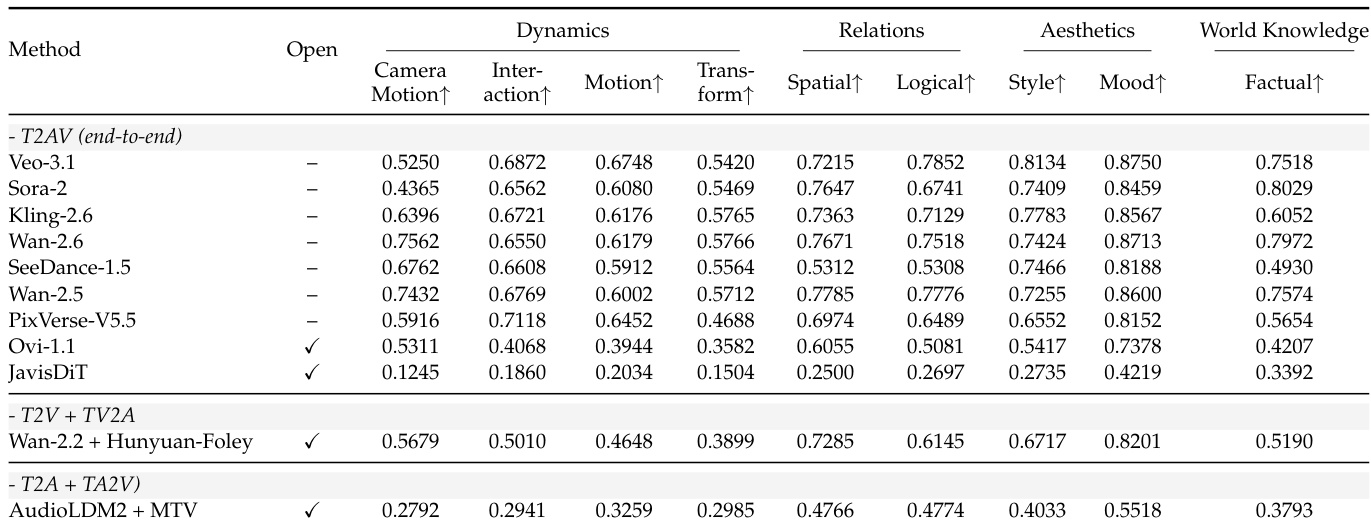
作者使用客观指标在视频质量、音频质量和跨模态对齐三方面评估11个T2AV系统,显示闭源模型普遍优于开源模型。结果表明Veo-3.1在视频技术质量(VT)和跨模态对齐(T-V)领先,而Wan-2.2 + Hunyuan-Foley等组合管道获得最高视频美学评分(VA)。音频质量仍是瓶颈,即使顶级模型在感知质量(PQ)和内容实用性(CU)上得分平平,同步指标(DS, LS)在各系统间波动显著。
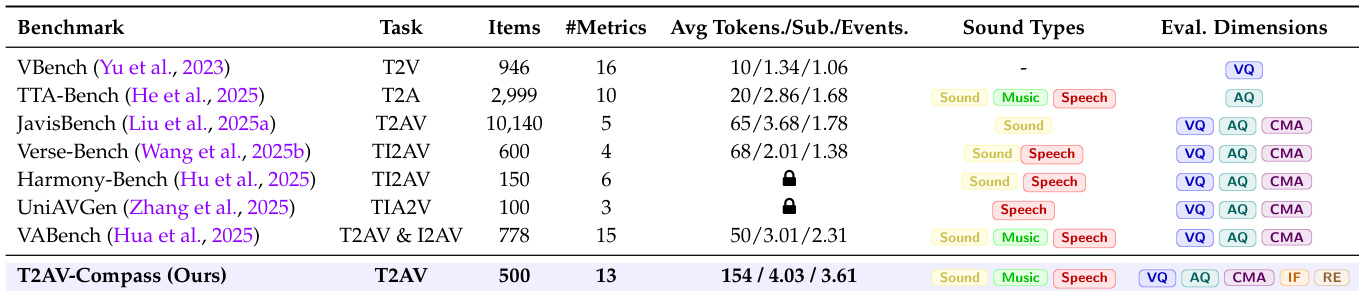
作者使用T2AV-Compass在13项指标上评估文本到视听生成系统,涵盖视频质量、音频质量、跨模态对齐、指令遵循和真实感,平均每样本154个token,支持声音、音乐和语音。结果显示T2AV-Compass比先前基准测试包含更多样化评估维度,同时保持500项的适中规模,可全面且可行地评估多模态连贯性和感知保真度。
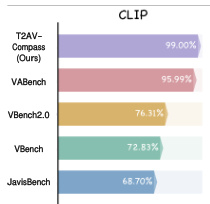
作者使用基于CLIP的对齐分数评估文本到视听生成中的跨模态一致性,T2AV-Compass以99.00%得分位居第一。结果表明T2AV-Compass显著优于VABench、VBench2.0和JavisBench等先前基准测试,说明生成内容与输入提示词间语义对齐更强。
作者使用客观指标在视觉和听觉维度评估多个T2AV系统,发现闭源模型在属性和电影摄影评分方面普遍优于开源模型,而Wan-2.2 + HunyuanFoley等组合管道在非语音音频保真度等特定领域表现具竞争力。结果表明所有模型在音频真实感方面均存在持续差距,语音和音乐评分明显低于视觉指标,凸显跨模态瓶颈。Veo-3.1在多数视觉类别领先,但在声音相关指标表现不佳,突显实现平衡多模态生成的挑战。