Command Palette
Search for a command to run...
Nemotron 3 Nano:面向智能体推理的开源、高效混合专家Mamba-Transformer模型
Nemotron 3 Nano:面向智能体推理的开源、高效混合专家Mamba-Transformer模型
摘要
我们提出Nemotron 3 Nano 30B-A3B,这是一种混合专家(Mixture-of-Experts)架构的Mamba-Transformer语言模型。Nemotron 3 Nano在25万亿个文本标记(tokens)上进行预训练,其中包含超过3万亿个相较于Nemotron 2新增的唯一标记,随后在多样化的环境中进行了监督微调与大规模强化学习(RL)训练。相较于前代Nemotron 2 Nano,Nemotron 3 Nano在保持每前向传播仅激活少于一半参数的前提下,实现了更高的准确率。该模型在推理吞吐量方面表现卓越,相比同类规模的开源模型(如GPT-OSS-20B和Qwen3-30B-A3B-Thinking-2507),最高可提升达3.3倍,同时在多个主流基准测试中展现出更高的准确性。Nemotron 3 Nano在智能体行为、推理能力及对话交互方面均有显著增强,并支持长达100万标记(1M tokens)的上下文长度。我们已在Hugging Face平台公开发布Nemotron 3 Nano 30B-A3B的预训练基础模型(Base)以及后续训练后的检查点(checkpoint)。
一句话摘要
NVIDIA推出Nemotron 3 Nano,一款31.6B参数的混合专家(Mixture-of-Experts)混合Mamba-Transformer模型,每次前向传播仅激活3.2B参数,在保持更高精度的同时实现比前代模型高达3.3倍的推理吞吐量;该高效架构展现出增强的智能体推理能力,支持长达100万token的上下文,并已在Hugging Face公开发布供研发使用。
核心贡献
- Nemotron 3 Nano引入开源高效的混合专家(MoE)混合Mamba-Transformer架构用于智能体推理,用稀疏MoE层替代标准FFN层,在31.6B总参数中每次前向传播仅激活3.2B参数,从而实现更高精度。该设计专门针对推理阶段计算资源受限时对高性能推理的需求。
- 模型采用特殊训练方法:在25万亿token上使用预热-稳定-衰减(Warmup-Stable-Decay)学习率调度进行预训练,并通过1210亿token的专用长上下文阶段(LC-Phase)支持长达100万token的上下文。该方法实现显著效率提升,在保持精度的同时推理吞吐量比竞品模型高出3.3倍。
- Nemotron 3 Nano通过开源的Nemo-Gym框架在后训练阶段扩展强化学习,实现多环境RL同步训练,支持推理控制功能如开关切换和token预算管理。该模型在推理和智能体任务中达到业界领先性能,并在HuggingFace完全开源模型权重、训练方案及代码。
引言
智能体推理应用需要平衡精度、速度与极端上下文处理能力的模型,但现有方法常为长上下文能力牺牲推理吞吐量,或缺乏实际部署所需的开放性。先前的MoE和Transformer系统在标准上下文长度外扩展效率低下,限制了其在复杂高token任务中的实用性。作者提出Nemotron 3 Nano——一款开源混合专家混合Mamba-Transformer模型,在实现竞争性精度的同时提供高达3.3倍的推理吞吐量,并支持100万token上下文。作者进一步通过在HuggingFace公开模型权重、训练方案、数据和代码实现完全透明化。
数据集
作者为Nemotron 3 Nano使用多源预训练语料库及专用后训练数据集,关键组件包括:
-
数据集构成与来源
- 网络爬取:英语/Common Crawl快照(CC-MAIN-2013-20至2025-26)
- 代码:GitHub、Common Crawl代码页面、合成代码
- 专业领域:STEM/数学教科书、科学编码、多语言内容(19种语言)
- SFT/RL:竞赛数学/代码、工具使用轨迹、安全数据、终端任务
-
关键子集详情
- Nemotron-CC-v2.1:3个Common Crawl快照生成的2.5T新英语token;包含合成改写(中高质量数据)及9种语言到英语的翻译(经LLM质量过滤)。
- Nemotron-CC-Code-v1:428B高质量代码token;通过Lynx渲染+Phi-4 LLM清洗保留代码/数学结构并去除噪声。
- Nemotron-Pretraining-Code-v2:更新GitHub代码(2025年4月后)+合成数据;包含Qwen3-32B生成的代码对话、LLM重写的Python(语法验证)及Python→C++转译。
- Nemotron-Pretraining-Specialized-v1:合成STEM数据(430万RQA示例,317亿token);通过NeMo Data Designer生成,采用跨领域"InfiniByte"问题培育和分层采样。
- SFT/RL数据集:总计1800万样本;包含128k-token合成长上下文数据、形式化Lean证明(30万示例)及多语言翻译(5种语言)。
-
数据使用与处理
- 预训练采用两阶段课程:初始注重多样性的混合(占训练94%),逐步转向高质量数据(Wikipedia等);15类别混合平衡质量层级(如crawl-medium至syn-crawl-high)。
- SFT将聊天模板应用于智能体任务;动态采样使小型数据集经历多轮训练。
- RL在数学、编码、工具使用和指令遵循环境中使用12K+任务,采用基于模式的奖励机制。
- 所有合成数据经LLM裁判过滤质量、重复内容及政治/民族主义偏见。
-
附加处理
- 代码/数学标准化:方程转换为LaTeX;Python重写后经Pylint检查。
- 多语言过滤:langdetect工具确保目标语言主导;不可翻译内容跳过。
- 安全性:不安全提示用拒绝模板封装;内容安全分类器过滤响应。
- 未提及裁剪策略;长上下文数据验证至256k token。
方法
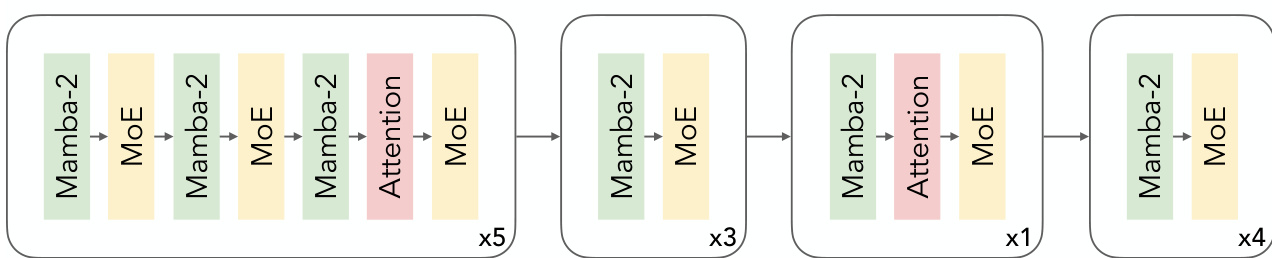
作者采用混合Mamba-Transformer架构,结合稀疏混合专家(MoE)层构建Nemotron 3 Nano 30B-A3B Base模型。该设计用MoE层替代标准前馈网络,在每次前向传播保持低激活参数量(31.6B总参数中仅3.2B激活,不含嵌入层)的同时提升精度。MoE层采用平方ReLU激活和带sigmoid门控的学习型MLP路由器,模型使用RMSNorm归一化且无位置嵌入丢弃或线性层偏置。解耦嵌入和投影权重以进一步优化性能。
参考框架图示,该模型块结构交替使用Mamba-2块与MoE层,注意力层策略性地置于特定间隔。序列起始为五组包含Mamba-2、MoE、Mamba-2、MoE、Mamba-2、Attention、MoE的块,随后三组Mamba-2、MoE、Attention、MoE块,接着单组Mamba-2、Attention、MoE,最后四组Mamba-2、MoE。该分层结构平衡状态空间建模与基于注意力的上下文捕获,MoE实现动态专家选择以提升计算效率。
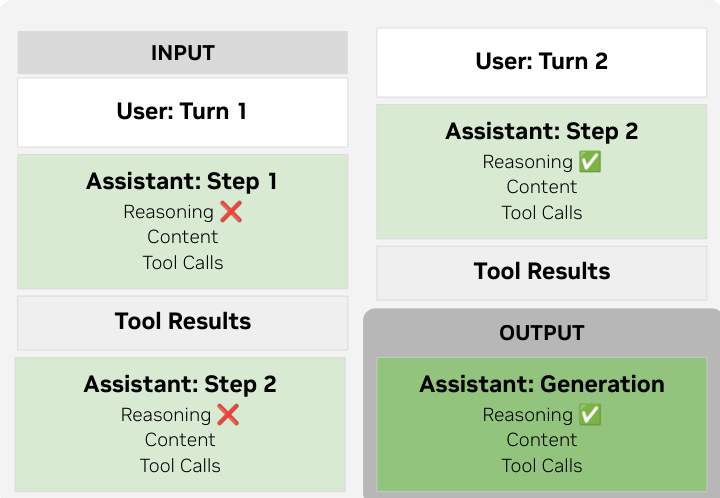
后训练阶段,模型通过结构化聊天模板支持推理控制,实现多步和多轮推理流程。多步场景中保留先前步骤的推理token以维持连贯性,多轮交互中遇新用户输入则丢弃先前推理。工具调用采用XML风格标签以最小化转义开销,遵循GLM-4.5和Qwen3-Coder规范。如下图所示,生成时仅将当前轮次推理实例化至提示中,确保上下文相关性同时保留步骤状态。
训练过程始于25万亿token的预训练,采用预热-稳定-衰减学习率调度:84亿token内预热至10−3,20万亿token保持峰值,最后5万亿token衰减至10−5。使用AdamW优化器(β1=0.9,β2=0.95,权重衰减0.1)。MoE层通过DeepSeek的无辅助损失负载均衡稳定(更新率10−3,负载均衡损失系数10−4)。后续长上下文扩展阶段在1210亿token上持续预训练(256k-token序列长度),采用8路上下文、张量、专家及4路流水线并行(H100 GPU)。数据混合包含79%降尺度第二阶段数据、20%文档问答和1%合成检索数据,混合512k与4k序列以保持短上下文性能。
后训练通过NeMo Gym和NeMo RL协调的多环境强化学习(RLVR)显著扩展。RLVR阶段同步训练所有环境,采用带掩码重要性采样的GRPO,每步128个提示,每提示16次生成。冻结MoE路由器权重以稳定训练,专家偏置通过无辅助损失负载均衡更新。课程策略通过高斯分布建模通过率,随时间从易到难动态调整任务难度,防止过拟合并确保领域覆盖均衡。
对于RLHF,使用GRPO算法在HelpSteer3和合成安全混合数据上训练生成式奖励模型(GenRM)。GenRM生成个体有用性评分及配对响应的排序评分,奖励定义为:
R=−C1Iformat−∣Ph1−Gh1∣−∣Ph2−Gh2∣−C2∣Pr−Gr∣,其中C1=10且C2=1。RLHF期间,循环比较策略将成对比较从O(N2)降至O(N),仅将每个响应与其后续者比较。组相对长度控制机制根据提示组内归一化的推理和答案长度调整奖励,应用零和惩罚及优质短响应的简洁性奖励(可选)。这使冗长度降低30%而不牺牲精度。
最后,模型通过Post-Training Quantization (PTQ)使用ModelOpt和Megatron-LM量化至FP8。选择性量化策略因高敏感性将自注意力层及其输入Mamba层保留为BF16,同时将权重、激活和KV缓存量化至FP8。Mamba块内的Conv1D层保持BF16以维持精度-效率平衡。
实验
- Nemotron 3 Nano 30B-A3B(31.6B总参数,每次前向传播激活3.2B)验证了比先前模型更优的效率与精度,在8K输入/16K输出场景下推理吞吐量比Qwen3-30B-A3B-Thinking-2507高3.3倍,比GPT-OSS-20B高2.2倍,同时匹配或超越其基准精度。
- 基础模型评估显示其在MMLU和GPQA等代码、数学及通用知识基准上超越Qwen3-30B-A3B-Base,在MMLU-redux CoT上取得显著提升(平均精度+5.27)。
- 可验证奖励强化学习(RLVR)在数学推理和智能体任务等所有领域均优于重度微调的监督学习(SFT)。
- FP8量化在多基准测试中实现99%中值精度恢复(对比BF16),同时支持更大批大小和更高吞吐量。
- 最小DPO训练将AIME25和GPQA的工具幻觉率降至0%和0.7%,同时提升精度3.7–4.04个百分点。
- 在数据集上展示低于1的提示敏感度得分,支持100万token上下文长度,在RULER上超越竞品。
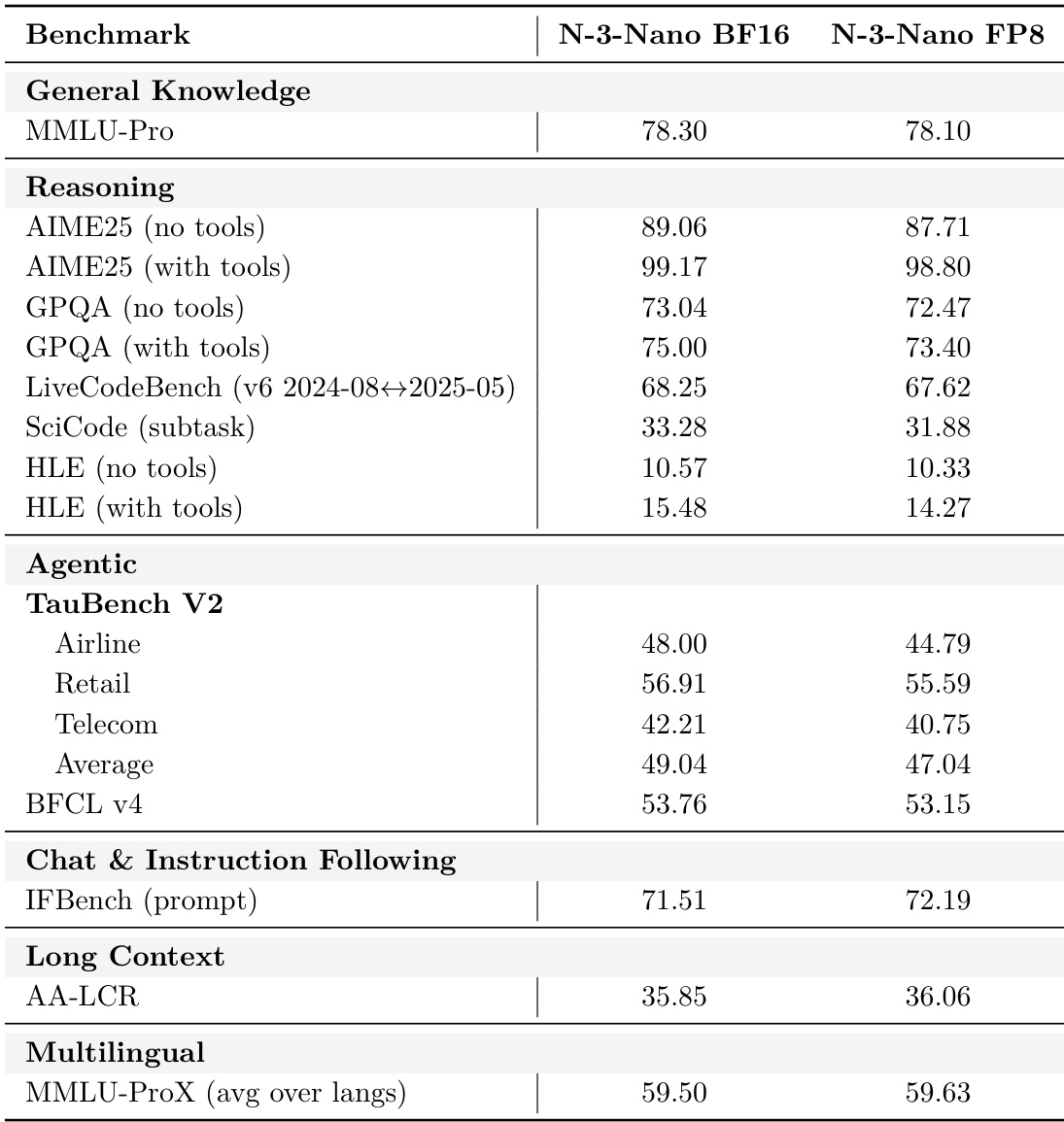
作者使用后训练量化将Nemotron 3 Nano从BF16转换为FP8,并在多基准测试中报告精度对比。结果显示FP8模型保留BF16版本约99%中值精度,在特定推理和智能体任务中仅有轻微性能折衷。量化模型在聊天、长上下文和多语言基准中保持强劲性能,同时实现更高推理吞吐量。
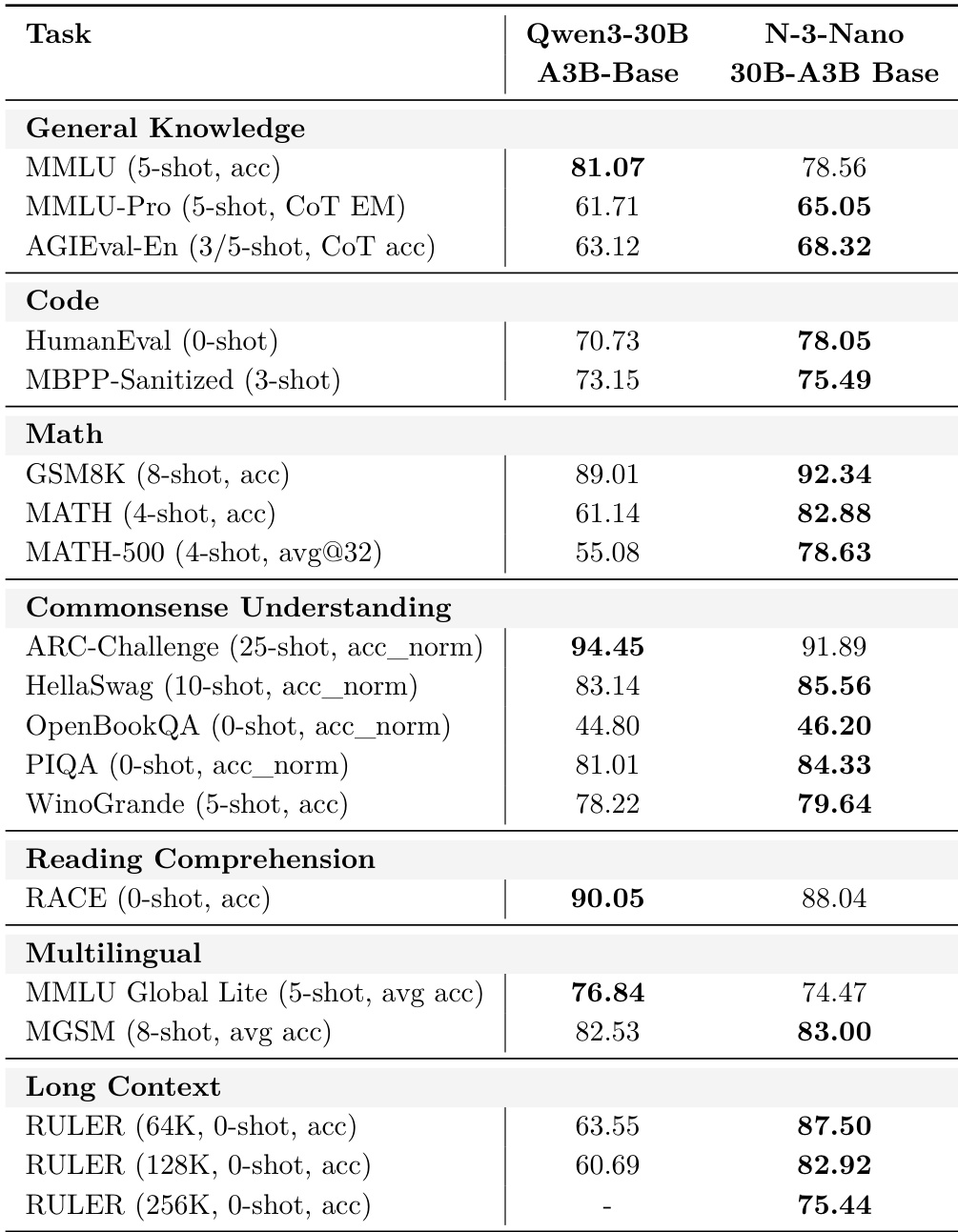
作者将Nemotron 3 Nano 30B-A3B Base与Qwen3-30B-A3B-Base在多基准测试中对比,显示Nemotron 3 Nano在数学、代码、常识理解和长上下文任务上优于Qwen3,但在通用知识和多语言基准上略逊。结果表明Nemotron 3 Nano在GSM8K、MATH、HumanEval及64K/128K上下文长度的RULER上得分更高,证明其更强的推理和长上下文能力,尽管在MMLU和MMLU Global Lite上表现稍低。
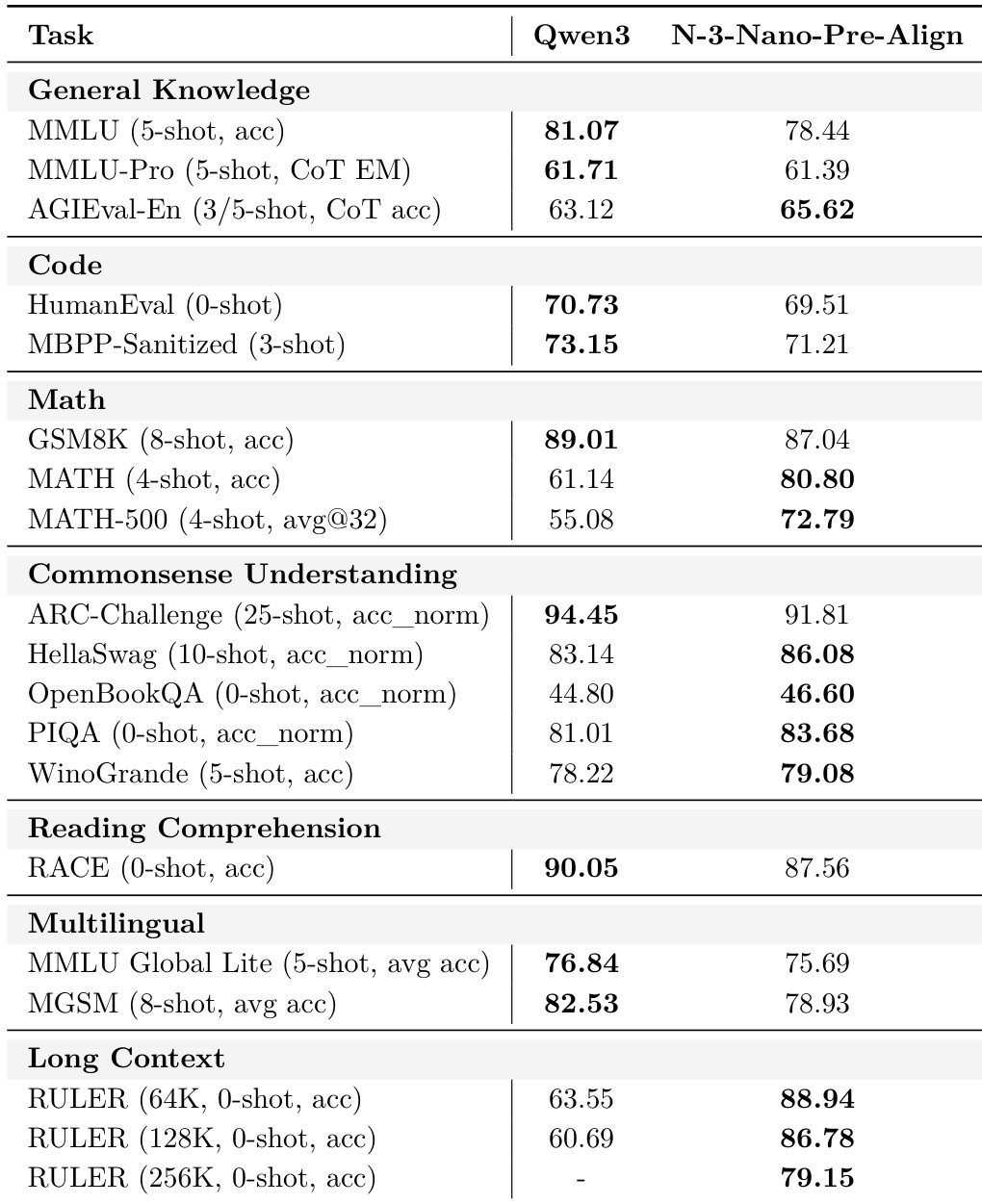
作者将Nemotron 3 Nano预对齐基础检查点与Qwen3-30B-A3B-Base在多基准测试中对比,显示Qwen3在通用知识和多语言任务领先,而Nemotron 3 Nano在数学、常识理解和长上下文推理上表现更优。结果表明Nemotron 3 Nano预对齐基础在数学和阅读理解上性能更强,在64K/128K上下文长度的RULER上得分显著更高。该对比突显早期模型能力的权衡,Nemotron 3 Nano在结构化推理和长上下文任务中表现出色,尽管在部分知识和多语言基准上落后。
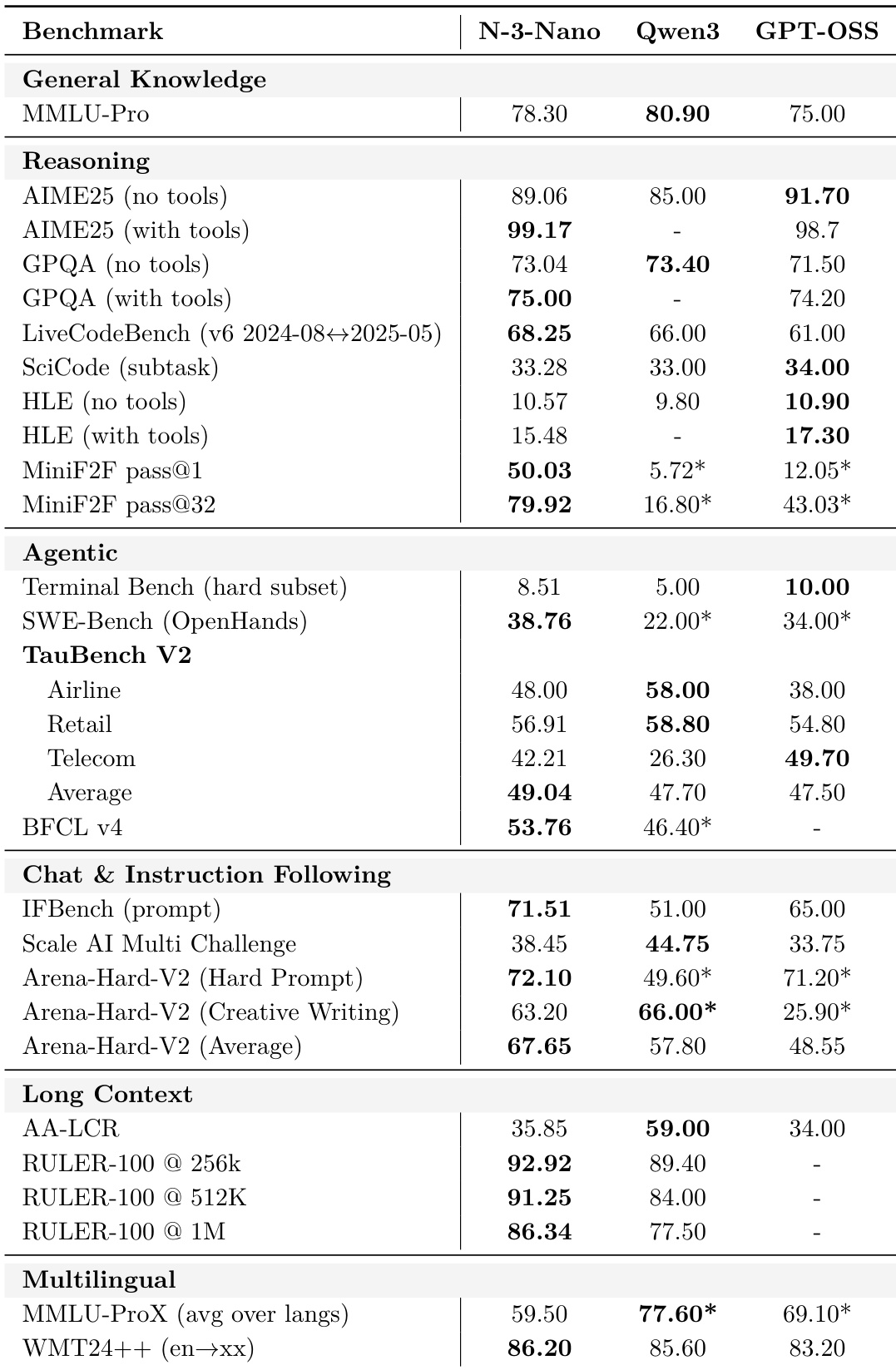
结果显示Nemotron 3 Nano在Terminal Bench和SWE-Bench等智能体基准上优于Qwen3-30B-A3B-Thinking-2507和GPT-OSS-20B,并在256K/100万token的RULER-100等长上下文任务中领先。其在推理和聊天类别中也取得有竞争力的分数,在IFBench和Arena-Hard-V2上表现强劲,同时在多语言翻译任务中匹配或超越Qwen3。该模型在工具增强和指令遵循场景中展现持续优势,尤其在需要结构化输出或环境约束时。
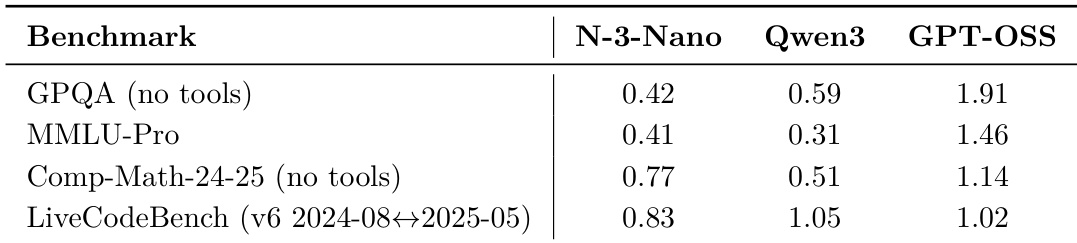
作者在四个推理和编码基准上将Nemotron 3 Nano与Qwen3和GPT-OSS对比,报告归一化至共同尺度的分数。结果显示Nemotron 3 Nano在所有四个基准上优于Qwen3,但显著落后于GPT-OSS(后者在所有任务中得分最高)。数据反映Nemotron 3 Nano在开源模型中的强劲相对性能,但凸显GPT-OSS在这些特定任务中的当前领先地位。