Command Palette
Search for a command to run...
TokSuite:衡量分词器选择对语言模型行为的影响
TokSuite:衡量分词器选择对语言模型行为的影响
Gül Sena Altıntaş Malikeh Ehghaghi Brian Lester Fengyuan Liu Wanru Zhao Marco Ciccone Colin Raffel
摘要
分词器(Tokenizers)为语言模型(LMs)对文本的表示与处理提供了基础支撑。尽管分词在语言模型性能与行为中扮演着关键角色,但由于难以在孤立条件下衡量分词的影响,其作用机制至今仍不清晰。为解决这一研究需求,我们提出了TokSuite——一个包含多种模型与基准测试的工具集,旨在支持对分词影响的系统性研究。具体而言,我们训练了十四种语言模型,这些模型在架构、训练数据、训练预算和初始化方式上完全一致,仅使用不同的分词器。此外,我们精心构建并发布了新的基准测试,专门用于评估模型在现实世界中可能引发分词变化的扰动下的表现。通过TokSuite,研究者能够稳健地分离出分词器对模型的影响,从而揭示一系列新颖发现,深入阐明了多种主流分词器各自的优劣势。
一句话总结
来自多伦多大学与向量研究所、麦吉尔大学与Mila等机构的研究人员提出TokSuite,包含14个架构完全相同的语言模型(在统一条件下训练但采用不同分词器)以及面向现实扰动的基准测试,从而实现分词器影响的隔离分析,系统评估主流分词方法的优势与局限。
核心贡献
- 由于难以在模型训练和评估中将分词器效应与其他变量分离,分词对语言模型性能的影响尚未被充分理解。
- 作者提出TokSuite,包含十四个架构、数据和初始化完全相同的同构模型(仅分词器类型不同),以及专为评估现实文本扰动(影响分词效果)而设计的新多语言基准测试。
- 该框架支持跨多种分词器和输入变体的受控分析,通过系统性模型评估揭示主流分词方法的具体优缺点。
引言
分词器从根本上决定了语言模型处理文本的方式,但其对模型行为的独立影响仍不明确——尽管它显著影响性能、训练效率和多语言能力,糟糕的选择甚至会使非英语语言的训练成本增加68%。现有研究存在关键局限:常将分词器效应与架构或数据等变量混淆,缺乏受控模型对比,且缺少针对拼写错误或复杂文字等现实输入变体的鲁棒性基准。作者通过TokSuite解决此问题:提供十四个仅分词器类型不同的严格受控模型(架构、数据和初始化完全一致),以及专为测量分词敏感扰动下性能而设计的新多语言基准测试,首次实现分词器效应的可靠隔离分析。
数据集
作者采用TokSuite基准数据集,通过现实文本扰动评估分词器鲁棒性。关键细节:
-
组成与来源:
TokSuite包含约5,000个样本,涵盖五种语言(英语、土耳其语、意大利语、波斯语、中文)和三个领域:常识知识(80%数据)、基础数学(20题)及STEM(44题)。来源包括母语者翻译的手工整理标准选择题,并包含反映现实变体的扰动。 -
子集详情:
- 多语言平行子集:40个标准英语问题(如"法国首都是...")翻译为全部五种语言。每个问题含10–20个扰动变体,经筛选确保模型在标准版上准确率>70%。扰动覆盖正字法错误(如用英文键盘输入土耳其语)、附加符号(波斯语可选标记)、形态学挑战(土耳其语黏着构词)、噪声(OCR错误)及Unicode格式。
- 数学子集:20道基础算术题(如"100的10%是...")多语言翻译,含数字格式变体(如"1,028.415" vs "1.028,415")。
- STEM子集:44道技术问题,含LaTeX表达式(如m2s2kg)、ASCII结构(如分子图)及领域特定格式。
-
论文中的应用:
数据集用于评估14个仅分词器不同的同构语言模型(如Gemma-2、GPT-2、TokenMonster)。通过对比标准样本与扰动样本的准确率下降评估模型。混合比例侧重多语言覆盖(80%常识知识,20%数学/STEM),语言特异性扰动比例根据语言特征调整(如波斯语增加附加符号变体)。 -
处理细节:
- 标准问题经"模型闭环"流程筛选,仅保留>70%模型能正确回答的问题。
- 扰动由母语者手工整理(按语言/方言专长致谢)。
- 零宽字符按分词器规则保留为新token、维持3字节形式或标准化。
- 词汇统一框架建立分词器特有token间的双射映射,确保嵌入初始化一致性。
- 无截断处理;完整评估扰动序列以测试端到端鲁棒性。
方法
作者通过统一框架评估分词对下游语言模型性能的影响,该框架在共享词汇空间下对齐多种分词器。核心是构建"超词汇表" SV,即所有分词器 T 的独立词汇表 Vi 的并集。此统一在UTF-8字节层面执行,确保系统间字符串表示一致,兼容WordPiece的"##"前缀或Unigram的" _-"空格标记等分词器特有规范。随后为每个分词器建立映射函数 SV:V(X)↦SV(X),将其原始token ID转换至 SV 中的位置,保证共享token字符串无论使用何种分词器均映射到相同索引。这实现了重叠token的嵌入初始化一致性。
参考框架示意图,该图展示了GPT-2、TokenMonster、XGLM等分词器如何集成于统一架构下。同时说明分词行为如何随语言(土耳其语、中文、意大利语)、错误类型(OCR、正字法)及符号领域(表情符号、化学式)变化,并通过TokSuite框架映射至采用14种不同分词器训练的Llama-3.2 1B模型。
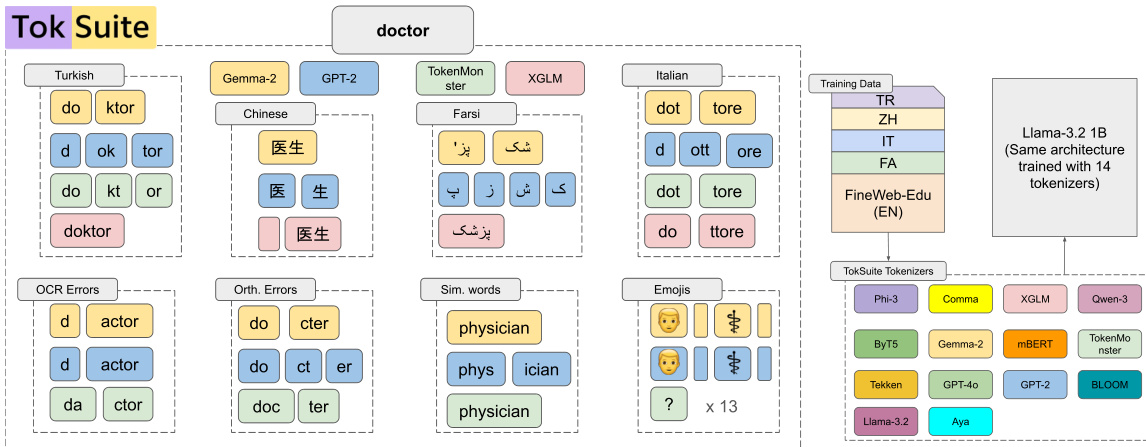
模型初始化沿用Llama-1B配置,但适配超词汇表大小 ∣Esv∣=∣SV∣。各模型嵌入表 E 通过从共享超词汇表嵌入表 Esv 选取行初始化,即 E(x)=Esv(sv(X))。这确保所有模型对 SV 中任意token均以相同初始嵌入开始训练,从而将分词器设计效应与随机初始化方差隔离。训练数据包含多语言语料库(TR、ZH、IT、FA及FineWeb-Edu(EN)),影响最终词汇表的构成与覆盖范围。分词器特有预处理决策(如缩写、数字或空格处理)在训练中保留,但在对齐时标准化以维持系统间可比性。
实验
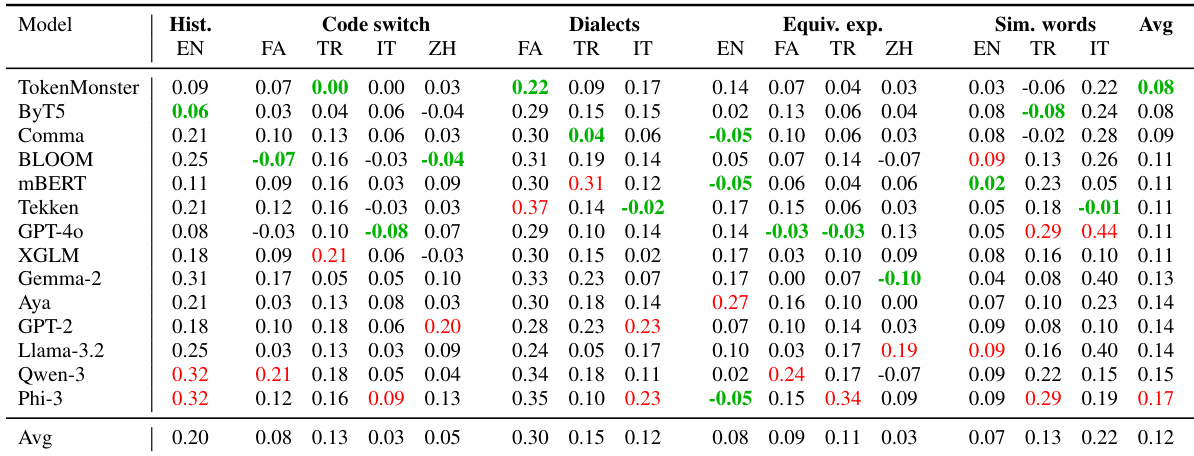
- 在词汇量(259–256k tokens)和算法各异的14种分词器上验证:分词设计对鲁棒性的影响远超词汇规模;TokenMonster(仅英语,32k tokens)在多语言扰动中平均性能下降最低(0.18),优于Aya和XGLM等大型多语言分词器。
- 通过TokSuite基准测试的相对准确率下降衡量鲁棒性:非英语噪声扰动导致的性能下降(0.22)显著高于英语(0.15);STEM和LaTeX内容引发严重下降(XGLM最高达0.30),而Unicode样式平均下降最高(0.53)。
- 字节级分词器ByT5展现卓越噪声鲁棒性(多语言噪声平均下降0.18),对土耳其语/中文处理稳健(正字法错误下降0.04/0.06),但子词生育率指标显示效率欠佳。
- 扩展分析表明:增大模型规模(1B vs 7B参数)或延长训练对鲁棒性提升甚微,证实分词设计而非模型规模主导各类扰动下的鲁棒特性。
作者在包含键盘错误、OCR、字符删除、空格移除及拼写错误的多语言噪声扰动上评估14种分词器,报告相对性能下降值(越低表示鲁棒性越强)。TokenMonster和ByT5平均下降最低(0.18),优于大词汇量模型;ByT5在中文OCR和空格移除中表现尤为突出。结果证实:分词算法设计(而非词汇量)是噪声鲁棒性的主导因素,尤其对非英语语言。
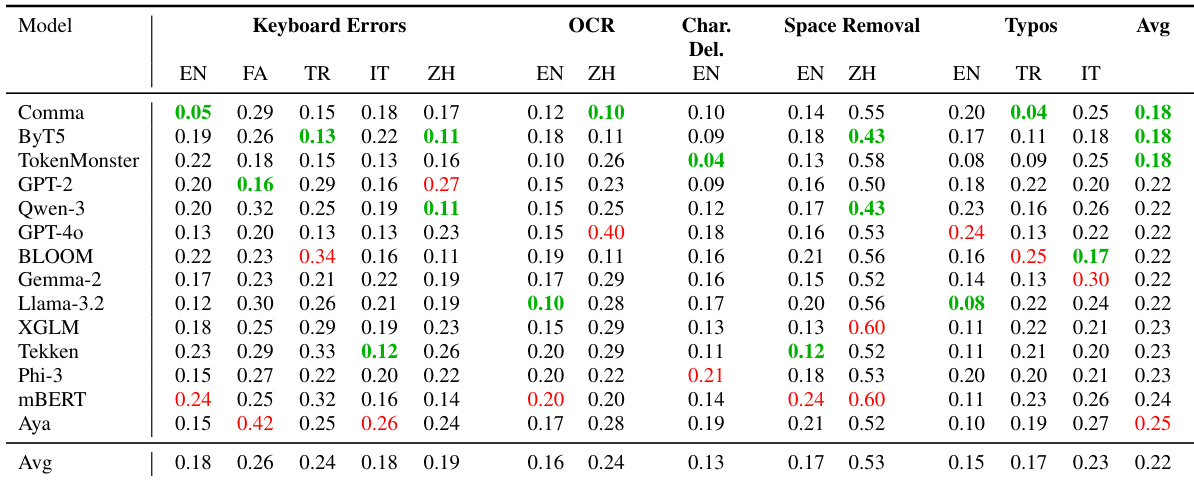
作者通过多类扰动的相对性能下降指标评估分词鲁棒性(值越低表示鲁棒性越强)。TokenMonster和Gemma-2-EBL在噪声和LaTeX处理中表现优异,而Gemma-2在Unicode样式和STEM任务中脆弱性较高。结果证实:分词设计(而非模型规模或词汇量)是决定各类输入扰动下鲁棒性的关键因素。

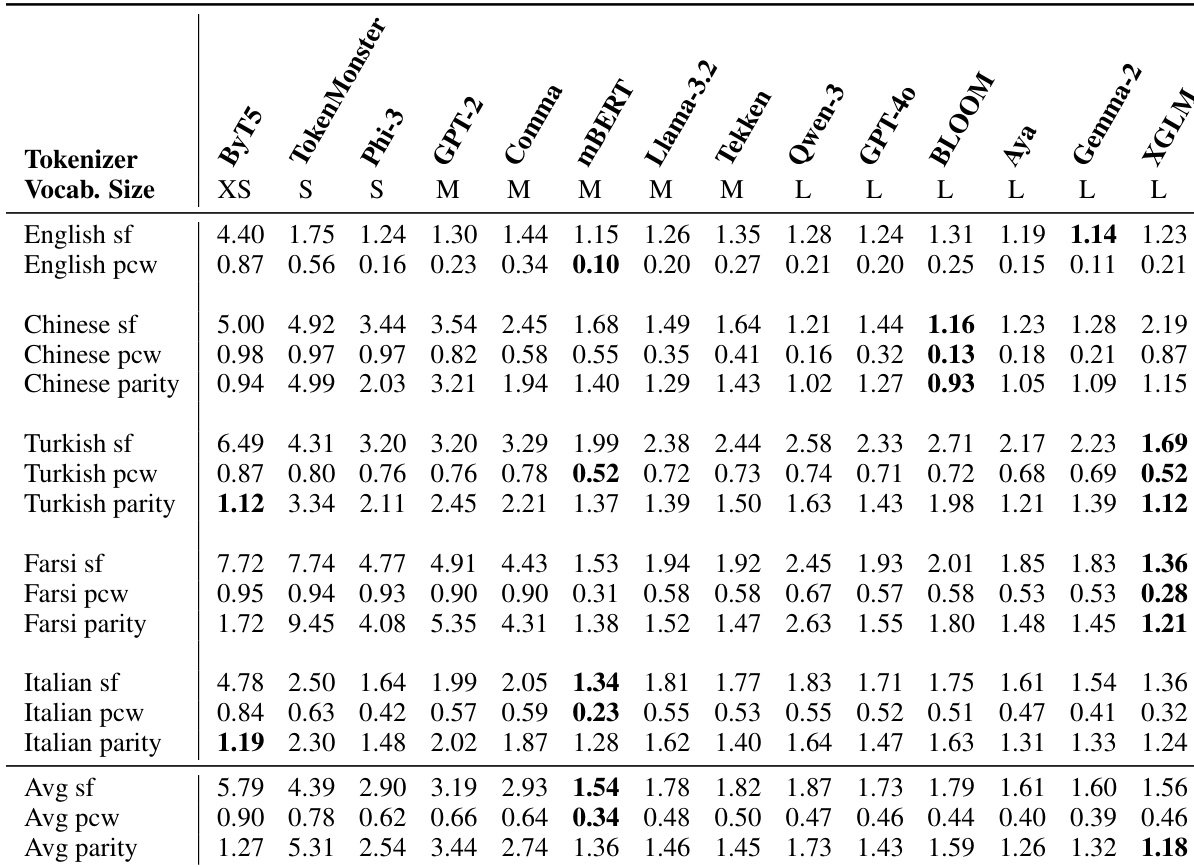
作者通过内在效率指标(子词生育率SF、续词比例PCW、跨语言均衡性)在五种语言上评估14种分词器。结果表明:ByT5和TokenMonster等小词汇量分词器SF和PCW更高,显示更激进的分段策略;而mBERT和XGLM等多语言分词器跨语言均衡性更优且平均SF更低,表明更平衡的跨语言压缩。词汇量本身不保证效率,部分大词汇量分词器在关键指标上表现反不如小词汇量分词器。
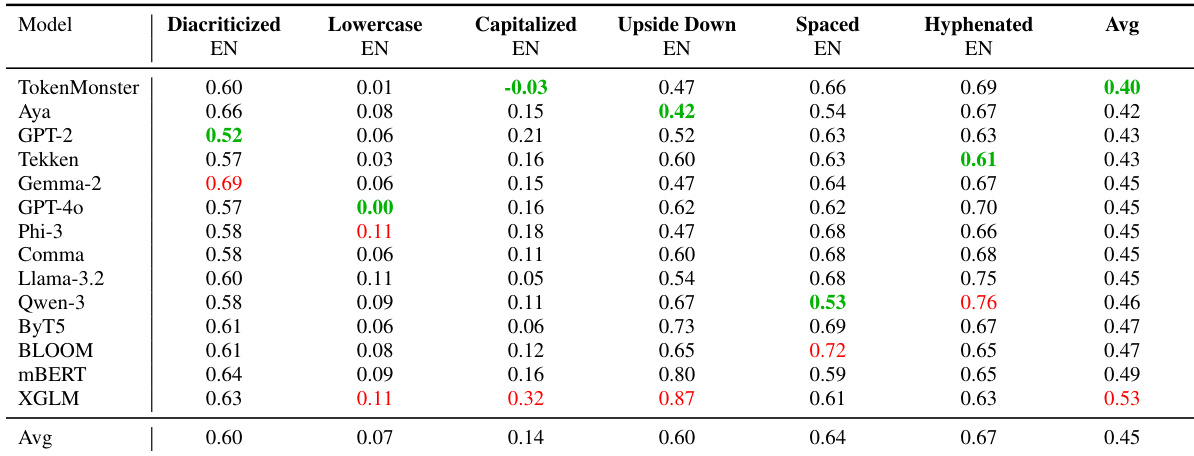
作者在包含附加符号、大小写变化、空格及格式的英语文本扰动上评估14种分词器,测量相对性能下降(值越低表示鲁棒性越强)。TokenMonster平均鲁棒性最佳(0.40),XGLM平均下降最高(0.53),在大写和倒置文本中表现尤为脆弱。结果证实:分词器设计(而非词汇量)对表面文本变体的鲁棒性具有决定性影响。
作者在包含历史拼写、语码转换、方言及等效表达的语言多样性扰动上评估14种分词器,发现TokenMonster和ByT5在多数类别中鲁棒性最强。结果表明:词汇量无法可靠预测性能,ByT5等小词汇量分词器在多项测试中优于大词汇量分词器,凸显分词算法设计比规模更重要。TokenMonster平均相对性能下降最低(0.08),尽管仅用英语训练且词汇量适中,仍展现出卓越一致性。