Command Palette
Search for a command to run...
SemanticGen:语义空间中的视频生成
SemanticGen:语义空间中的视频生成
摘要
当前最先进的视频生成模型通常在变分自编码器(VAE)空间中学习视频潜在表示,并通过VAE解码器将其映射为像素。尽管该方法能够生成高质量的视频,但在生成长视频时存在收敛速度慢、计算开销大的问题。本文提出了一种新方法——SemanticGen,旨在通过在语义空间中生成视频来解决上述局限性。我们的核心思想是:由于视频本身具有固有的冗余性,生成过程应首先在紧凑且高层的语义空间中进行全局规划,随后逐步添加高频细节,而非直接使用双向注意力机制建模大量低层视频标记。SemanticGen采用两阶段生成流程。第一阶段,一个扩散模型生成紧凑的语义视频特征,用于定义视频的整体结构布局;第二阶段,另一个扩散模型在这些语义特征的条件下生成VAE潜在表示,从而输出最终的视频。实验表明,相较于在VAE潜在空间中直接生成,基于语义空间的生成方式具有更快的收敛速度。此外,该方法在扩展至长视频生成时仍保持高效性与有效性。大量实验证明,SemanticGen能够生成高质量视频,并在性能上超越当前最先进的方法及多个强基线模型。
一句话总结
浙江大学、快手科技(Kling团队)与中国香港中文大学的研究人员提出SemanticGen,一种在语义空间而非VAE潜在空间中运行的两阶段视频生成框架。该框架首先通过扩散模型创建紧凑的语义特征以进行全局视频规划,然后基于这些特征生成VAE潜在表示,从而加速收敛并实现高效的高质量一分钟视频合成,同时优于先前的基于VAE的方法。
主要贡献
- 当前视频生成模型因在VAE潜在空间中使用双向注意力机制建模低级视频标记,导致长视频生成收敛速度慢且计算成本高,对扩展序列而言不切实际。
- SemanticGen引入两阶段扩散框架:先生成紧凑语义特征用于全局视频布局规划,再基于这些特征条件化生成VAE潜在表示以添加高频细节,利用视频冗余性提升效率。
- 实验表明该方法比VAE潜在空间生成收敛更快,在视频质量上优于现有最先进方法,同时能有效扩展至长视频生成场景。
引言
视频生成模型面临关键权衡:基于扩散的方法能生成高保真短视频,但受限于双向注意力机制同时处理所有帧的计算瓶颈,难以生成长序列;而自回归方法虽更适用于长视频,但质量较差。混合方法试图弥合这一差距,但仍逊色于纯扩散模型。另一方面,研究表明整合语义表示(如预训练编码器的输出)比原始潜在空间能加速训练并提升图像生成质量。作者通过提出新型基于扩散的视频生成框架解决上述挑战:微调扩散模型学习压缩语义表示,再将其映射至VAE潜在空间。该方法比直接生成VAE潜在表示收敛更快,且能有效扩展至长视频合成,在不牺牲保真度的前提下克服了先前的可扩展性障碍。
数据集
作者为短视频和长视频生成使用两个独立数据集:
-
数据集构成与来源:
训练数据包含用于短视频的内部文本-视频对数据集,以及由电影和电视剧片段构建的长视频数据集。 -
关键子集细节:
- 短视频子集:使用内部文本-视频对(确切规模未说明)。
- 长视频子集:将影视片段分割为60秒片段,通过内部描述器自动生成文本提示。未详细说明过滤规则。
-
训练中的数据使用:
- 训练时VAE输入采样帧率为24 fps,语义编码器输入为1.6 fps。
- 语义编码器采用Qwen2.5-VL-72B-Instruct的视觉塔。
- 训练聚焦文本到视频生成,未指定混合比例或划分比例。
-
处理细节:
- 未提及裁剪策略。
- 长视频元数据(文本提示)通过内部描述器合成构建。
- 帧率差异(24 fps vs. 1.6 fps)适配VAE和语义编码器的工作流程。
方法
作者提出名为SemanticGen的两阶段扩散框架,通过先建模高级语义表示再精炼为VAE潜在表示来生成视频。该设计解决了传统方法直接在VAE潜在空间操作导致的计算效率低下和收敛缓慢问题。整体架构将全局场景规划与细粒度细节合成解耦,实现可扩展高效生成,尤其适用于长视频。
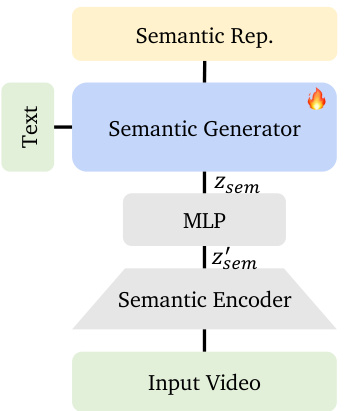
在第一阶段,语义生成器被训练为基于文本提示生成紧凑语义表示。这些表示源自现成的视频语义编码器——具体为Qwen-2.5-VL的视觉塔——它通过下采样帧并将空间块压缩为低维标记序列来处理输入视频。为提升训练稳定性和收敛速度,作者引入轻量级MLP,将高维语义特征zsem′压缩至低维潜在空间zsem,参数化为高斯分布。MLP输出均值和方差向量,并在损失函数中添加KL散度项以正则化压缩空间。该压缩表示随后作为第二阶段的条件输入。
参见语义生成流程框架图。语义生成器以文本提示为输入输出zsem,再经MLP处理得到zsem′(用于条件化的压缩语义嵌入)。该设计确保语义空间既紧凑又适配扩散采样。
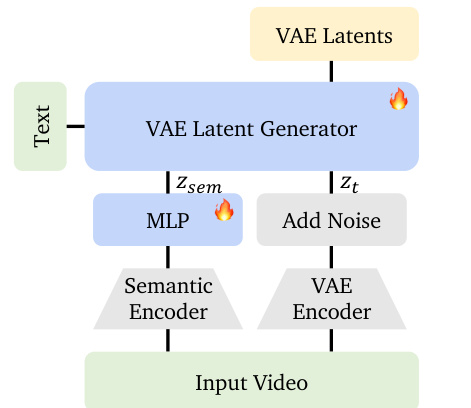
在第二阶段,视频扩散模型基于压缩语义表示条件化生成VAE潜在表示。训练时,模型接收拼接输入:加噪VAE潜在表示zt和语义嵌入zsem。这种上下文内条件化使扩散模型能在生成低级视觉细节时利用高级语义线索(如物体运动和场景布局)。作者观察到该条件化在保留全局结构和动态的同时允许纹理与颜色变化,这在基于参考的生成实验中得到验证。
如下图所示,VAE潜在生成器通过语义编码器和MLP从输入视频提取并压缩语义特征,再与加噪VAE潜在表示一同注入扩散模型。推理时,语义生成器从文本生成zsem,并添加噪声以弥合训练-推理差距,遵循RAE的实践。
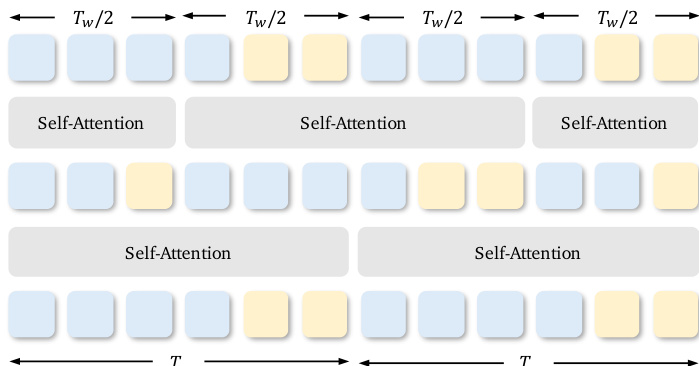
对于长视频生成,SemanticGen采用混合注意力策略管理计算复杂度。在语义空间应用全自注意力以维持场景和角色的全局一致性;映射至VAE潜在空间时,使用移位窗口注意力限制计算成本的二次增长。作者在大小为Tw的注意力窗口内交错VAE潜在标记和语义标记,并在奇数层将窗口偏移Tw/2。该设计确保语义空间(比VAE空间压缩16倍)保持可计算性,同时实现高保真重建。
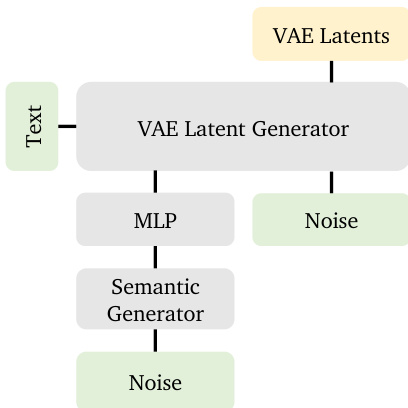
推理流程整合两个阶段:语义生成器从文本生成zsem,再输入VAE潜在生成器产出最终视频。整个过程在整体框架图中展示,突显语义到潜在表示的顺序生成特性。
基础扩散模型遵循Rectified Flow框架,前向过程定义为zt=(1−t)z0+tϵ(其中ϵ∼N(0,I))。训练最小化条件流匹配损失LLCM=Et,p+(z,ϵ),p(ϵ)∥vΘ(zt,t)−ut(z0∣ϵ)∥22,推理使用欧拉离散化:zt=zt−1+vΘ(zt−1,t)⋅Δt。该基础在保持时间连贯性的同时实现高效采样。
作者强调SemanticGen不依赖特定语义编码器;V-JEPA 2、VideoMAE 2或4DS等替代方案均可替换。该框架的模块化设计及对预训练语义编码器的依赖,使其能适配不断演进的视频理解模型,同时保持生成效率与质量.
实验
- 验证语义空间压缩效果:8维表示获得最高VBench分数,相比高维变体(64维和未压缩)显著减少伪影和断裂帧.
- 确认语义空间收敛更快:在预训练语义表示上训练比建模压缩VAE潜在表示收敛显著更快,在相同训练步数下生成连贯视频,而VAE方法仅产出粗略色块.
- 长视频生成超越最先进方法:在时序一致性和减少漂移问题上优于所有基线(包括MAGI-1、SkyReels-V2及持续训练变体),实现更低ΔdriftM分数且背景稳定无色彩偏移.
- 短视频质量匹配最先进水平:在VBench指标上与领先方法相当,同时展现更优文本遵循能力(例如正确生成基线遗漏的特定动作,如转头或融化的雪花).
作者通过比较不同输出维度的模型,评估语义空间压缩对视频生成质量的影响。结果显示:将语义表示压缩至低维(dim=8)相比未压缩(dim=2048)提升了连贯性、平滑度和美学质量,dim=8变体在多数指标上得分最高。这表明降维同时增强了语义生成流程的收敛速度和输出保真度.

作者使用长视频生成的定量指标评估SemanticGen与基线方法,显示其在主体一致性和运动平滑度上表现最佳,同时保持强背景一致性和最小时间闪烁。SemanticGen在主体一致性上优于Hunyuan-Video和Wan2.1-T2V-14B,在其他稳定性指标上匹配或超越它们,但在成像和美学质量上略低于Wan2.1-T2V-14B。结果证实SemanticGen能在不显著降低视觉保真度的前提下保持长期连贯性.

SemanticGen在多项视频质量指标上超越基线方法,在主体一致性、背景一致性、运动平滑度和成像质量上均获得最高分。其漂移指标(Δ_drift^M)最低,表明相比SkyReels-V2、Self-Forcing、LongLive和Base-CT-Swin等方法具有更优的长期时间稳定性.
