Command Palette
Search for a command to run...
LongVideoAgent:基于长视频的多Agent推理
LongVideoAgent:基于长视频的多Agent推理
Runtao Liu Ziyi Liu Jiaqi Tang Yue Ma Renjie Pi Jipeng Zhang Qifeng Chen
摘要
近年来,多模态大语言模型(LLM)及利用工具进行长视频问答(long-video QA)的系统发展,预示着对时长一小时以上的视频内容进行推理的潜力。然而,许多现有方法仍依赖有损压缩将内容简化为摘要,或受限于有限的工具集,导致时间定位能力弱化,并遗漏细粒度的线索。为此,我们提出一种多智能体框架:由一个主控大语言模型协调一个定位智能体,用于精确定位与问题相关的时间片段,以及一个视觉智能体,用于提取针对性的文本观察。主控智能体在步数限制下进行规划,并通过强化学习进行训练,以促进简洁、准确且高效的多智能体协作。该设计使主控智能体能够通过时间定位聚焦于相关视频片段,结合视觉信息丰富字幕内容,同时生成可解释的推理轨迹。在我们提出的两个新数据集——LongTVQA 与 LongTVQA+ 上(这两个数据集为从 TVQA/TVQA+ 汇总而得的剧集级数据集),所提出的多智能体系统显著优于多个强大的非智能体基线方法。实验结果还表明,强化学习进一步增强了智能体的推理与规划能力。
一句话总结
香港科技大学等机构的研究人员提出了一种基于强化学习训练的多智能体框架,用于长视频问答任务。该框架通过主控大语言模型协调定位代理和视觉代理,替代传统的有损摘要方法。该方法实现了精确的时间定位和视觉细节提取,在LongTVQA数据集上通过可解释的、步骤受限的协作推理显著超越基线模型。
核心贡献
- 现有长视频问答方法受限于有损压缩和工具集不足,导致时间定位能力弱化且丢失细粒度线索;本工作提出模块化多智能体框架,其中主控大语言模型协调定位代理完成片段定位,同时协调视觉代理提取目标视觉观察结果。
- 主控代理采用步骤受限的规划策略,并通过强化学习进行训练(奖励机制促进简洁、准确、高效的多智能体协作),使推理聚焦于相关视频片段,同时融合字幕与视觉细节生成可解释的推理轨迹。
- 在新提出的剧集级LongTVQA和LongTVQA+数据集上评估表明,该系统显著优于强非智能体基线模型;消融实验确认多智能体架构与强化学习共同提升了推理与规划能力。
引言
多模态大语言模型(MLLMs)在长视频理解任务中面临挑战,因为关键信息通常分散在数小时的视频流中,需对帧、音频和对话进行细粒度分析。现有方法通常通过静态有损压缩或单次重采样处理视频,这会不可逆地丢弃时间细节,难以应对复杂且时间跨度大的查询。即使是早期基于智能体的系统(如VideoAgent)也仅依赖有限工具集(例如通用字幕模型),无法捕捉精确对象引用或细微视觉线索,同时未能充分利用结构化推理。
作者提出LongVideoAgent多智能体框架予以解决:主控智能体协调专用定位代理和视觉代理,通过迭代式工具增强推理主动检索任务相关片段并提取细粒度视觉细节。同时提出基于奖励的训练策略,强制执行简洁的分步证据收集,并构建新基准LongTVQA进行严格评估。该方法通过动态聚焦稀疏证据避免不可逆预处理,实现当前最佳准确率。
数据集
作者通过扩展TVQA和TVQA+构建剧集级LongTVQA和LongTVQA+数据集,关键细节如下:
-
数据集构成与来源:
基于TVQA(6部电视剧,21.8K短片段上的152.5K多选题)和TVQA+(含时空标注的精炼子集,主要聚焦《生活大爆炸》)。 -
子集特性:
- LongTVQA:将TVQA每集片段聚合为小时级序列,保留152.5K问题及字幕、时刻标注和片段级上下文。
- LongTVQA+:聚合TVQA+片段(4,198片段上的29.4K问题),保留310.8K帧级边界框用于实体定位和精确时间戳。
-
论文中的数据使用:
- 所有结果均基于剧集级聚合后的原始验证集划分。
- 对比基于帧的输入(利用视觉证据)与纯字幕输入,证实帧数据普遍提升性能。
- 在这些数据集上应用多智能体框架(MASTERAGENT)及强化学习微调。
-
处理细节:
- 同集片段合并为单一时间线,时间戳调整至剧集尺度。
- 按剧集整合视觉流、字幕和问题;TVQA+边界框保持帧对齐。
- 无额外裁剪——长视频在聚合剧集级原生处理。
方法
作者采用多智能体推理框架解决长视频问答问题,其中主控大语言模型调度两类专用代理:定位代理负责时间定位,视觉代理负责细粒度视觉观察提取。该架构支持对小时级剧集进行迭代式证据收集推理,无需依赖有损压缩或固定摘要。
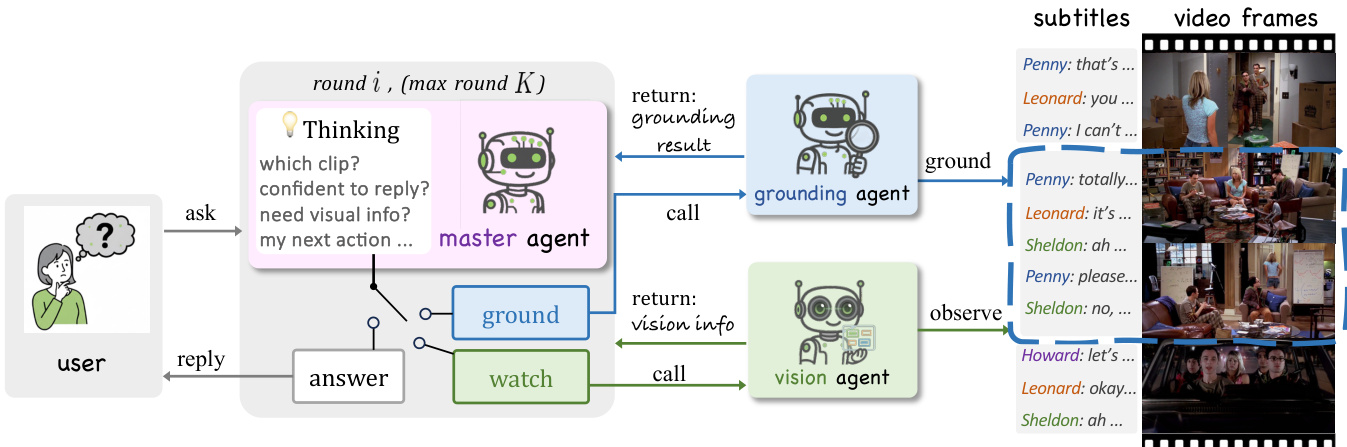
如下图所示,系统在有限多轮循环中运行,主控代理维护包含字幕、定位片段标签和提取视觉观察的增量上下文。每轮主控代理输出三种结构化动作标记之一:<request_grounding>用于精炼时间定位,触发视觉观察提取,终止流程生成最终答案。定位代理根据问题和完整字幕返回符号标签(如<clip_X>)标识相关时间片段。视觉代理基于该片段标签和动态生成的视觉查询,从对应帧中提取对象、动作、场景线索或屏幕文本的描述。这些输出追加至主控上下文,指导后续决策。
对于开源大语言模型作为主控代理的场景,作者通过GRPO应用强化学习优化策略行为。训练目标结合两类基于规则的奖励:结构有效性 rtfmt(每步精确输出单一动作标记的奖励)和答案正确性 rans(多选题答案完全匹配的终止奖励)。轨迹回报定义为 R(τ)=α∑t=0Trtfmt+rans,其中 α>0 平衡每步结构塑造与最终任务奖励。策略更新采用带学习值基线的序列级优势计算,定位与视觉代理在训练中保持冻结。这种极简奖励结构促使主控代理生成简洁规范的动作序列和准确最终答案,无需密集中间监督。
参考框架图理解完整交互流程:用户提交问题和视频,主控代理启动推理,系统通过定位与视觉调用迭代直至积累足够证据生成正确答案。最终推理轨迹可解释、分步且同时基于时间与视觉证据。
实验
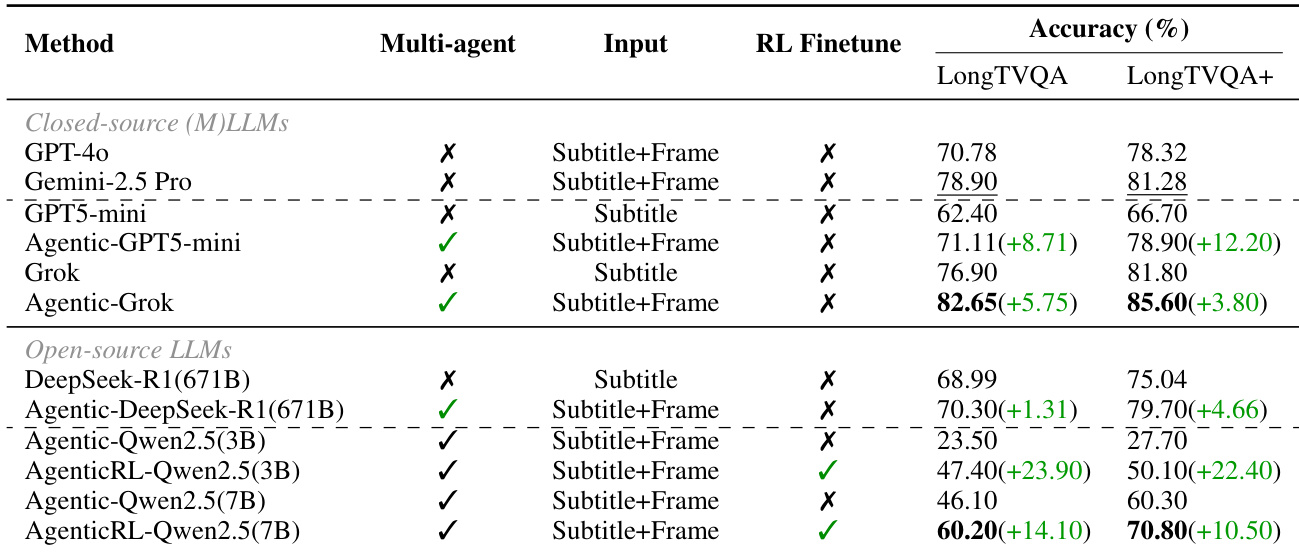
- 多智能体框架对比非智能体基线:在LongTVQA/LongTVQA+验证集上,整合定位与视觉代理实现74.8%答案准确率,超越非智能体基线+10.5个百分点,验证智能体行为在上下文定位与视觉检查中的有效性。
- 强化学习影响:Qwen2.5-7B经RL训练后准确率媲美GPT-5-mini(相同评估协议),证实强化学习为开源模型带来稳定增益。
- 执行步数限制消融:最大步数从2增至5使答案准确率达73.67%(+5.37)且定位准确率达71.0%(+4.0),K>5时性能饱和,表明最优步数效率。
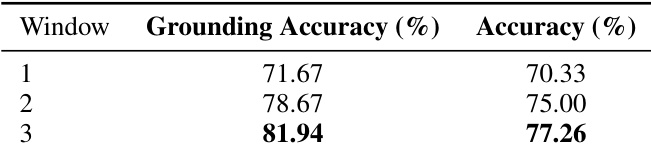
- 上下文窗口分析:证据窗口从1扩展至3个片段使答案准确率达77.26%(+6.93)且定位准确率达81.94%(+10.27),证实相邻片段上下文助于消歧但收益递减。
- 视觉代理对比:GPT-4o作为视觉骨干实现78.00%答案准确率,超越Qwen3-VL-235B-a22b达+4.33个百分点,凸显强视觉识别对最终任务性能的关键作用。
作者评估主控代理最大执行步数(K)的影响,发现K从2增至5时定位准确率从67.0%提升至71.0%,答案准确率从68.30%提升至73.67%。K增至10后答案准确率无进一步增益,定位准确率仅微幅提升,表明K>5时收益显著递减。

作者采用含定位与视觉模块的多智能体框架增强长视频问答,证明在闭源与开源大语言模型上均稳定超越非智能体基线。结果表明即使使用相同骨干网络,添加智能体组件仍能提升性能,强化学习进一步推动Qwen2.5-7B等开源模型接近闭源模型水平。最大增益出现在多智能体协同与帧级视觉输入结合时,尤其在LongTVQA+上表现突出。
作者在多智能体框架内对比两种视觉模型,发现GPT-4o在定位准确率(73.30% vs. 71.00%)和答案准确率(78.00% vs. 73.67%)上均优于Qwen3-VL-235B。结果表明视觉代理的强视觉识别能力直接提升长视频问答的最终任务性能。

作者评估扩展时间证据窗口对定位与答案准确率的影响。结果表明窗口从1增至3个片段时,定位准确率从71.67%提升至81.94%,答案准确率从70.33%提升至77.26%。更大窗口提供丰富消歧上下文但收益递减且延迟增加。
作者使用相同骨干模型评估多智能体系统与纯文本基线。添加时间定位将准确率从64.3%提升至69.0%,进一步整合视觉代理后达74.8%,证明智能体协作通过定位相关片段和提取视觉证据增强推理能力。这些增益源于工具的结构化使用,而非基础模型或提示词的改变。
