Command Palette
Search for a command to run...
通过闭环世界建模实现视频虚拟人中的主动智能
通过闭环世界建模实现视频虚拟人中的主动智能
Xuanhua He Tianyu Yang Ke Cao Ruiqi Wu Cheng Meng Yong Zhang Zhuoliang Kang Xiaoming Wei Qifeng Chen
摘要
当前的视频虚拟形象生成方法在身份保持和动作对齐方面表现优异,但缺乏真正的自主性,无法通过适应性环境交互来自主追求长期目标。为此,我们提出了L-IVA(Long-horizon Interactive Visual Avatar,长时程交互式视觉虚拟形象)——一个用于评估随机生成环境中目标导向规划能力的任务与基准,并提出了ORCA(Online Reasoning and Cognitive Architecture,在线推理与认知架构)——首个实现视频虚拟形象主动智能的框架。ORCA通过两项关键创新,实现了内部世界模型(Internal World Model, IWM)的核心能力:(1)闭环的OTAR循环(观察-思考-行动-反思),通过持续将预测结果与实际生成结果进行比对,在生成不确定性环境下实现稳健的状态追踪;(2)分层双系统架构:系统2负责基于状态预测进行战略推理,系统1则将抽象规划转化为精确、模型特定的动作指令。通过将虚拟形象控制建模为部分可观测马尔可夫决策过程(POMDP),并结合基于结果验证的连续信念更新机制,ORCA实现了在开放域场景下的自主多步任务完成能力。大量实验表明,ORCA在任务成功率与行为一致性方面显著优于开环及无反思的基线方法,验证了受内部世界模型启发的设计理念,推动视频虚拟形象从被动动画向主动、目标导向行为的跃迁。
一句话总结
来自香港科技大学、美团和中国科学技术大学的研究人员提出了ORCA——首个通过闭环OTAR循环(观察-思考-行动-反思)和分层双系统架构实现自主视频虚拟人的框架。该框架将控制建模为具有连续信念更新的部分可观测马尔可夫决策过程(POMDP),从而在开放域场景中推动目标导向行为,超越传统的被动动画。
核心贡献
- 现有视频虚拟人方法虽能保持强身份一致性,却缺乏自主目标追求能力。为此提出L-IVA基准,用于评估随机生成环境中需通过多步交互完成开放域任务的长时程规划能力。
- ORCA通过闭环OTAR循环实现主动智能:该循环在生成不确定性下保障鲁棒状态跟踪;分层双系统架构中,系统2负责结合状态预测的战略推理,系统1则将计划转化为精确的执行动作描述。
- 在L-IVA上的实验表明,ORCA在任务成功率和行为连贯性上显著优于开环与非反思基线,验证了其受内部世界模型启发的设计可使虚拟人从被动动画转向目标导向行为。
引言
视频虚拟人技术已能基于语音或姿态序列等输入生成高保真人体动作,应用于虚拟助手等场景。然而现有方法仍处于被动执行预定义动作的状态,缺乏自主目标追求能力——这限制了其在产品演示等需多步规划与环境交互的动态场景中的应用。先前研究未能解决两大核心挑战:(1) 生成不确定性下的状态估计,随机视频输出导致内部状态跟踪不可靠;(2) 开放域动作规划,语义指令在无界动作空间中缺乏精确执行所需的细节。作者提出ORCA框架,首次通过闭环观察-思考-行动-反思循环将主动智能嵌入视频虚拟人:该循环持续验证结果以修正状态误差,并结合双系统架构将高层目标转化为模型特定的控制信号以实现精准执行,从而在随机生成环境中可靠完成长时程任务。
数据集
作者提出L-IVA基准——首个用于评估视频生成中主动智能的评测数据集,涵盖厨房、直播、车间、花园、办公室五大现实场景的100项任务。关键细节:
-
组成与来源:
- 混合数据集含92张合成图像与8张真实图像
- 总计100项任务(每类场景20项),含每类5项双人协作任务
- 每项任务需3–8步交互操作>3个物体,平均5.0个子目标
-
子集特性:
- 真实子集(8张图像):源自Pexels,筛选含可交互物体的场景以支持多步物理操作,高层意图经人工定义
- 合成子集(92张图像):通过Nanobanana采用"先设计后生成"方法——先定义高层意图,再通过文本提示构建场景以确保物体交互逻辑可解
-
标注与处理:
- 所有样本包含物体清单(名称/位置/状态)、自然语言意图及参考动作序列
- 真实数据元信息(子目标/物体描述/动作提示)由Gemini-2.5-Pro基于图像与意图生成
- 标注以图像-YAML对存储,评测聚焦目标完成度(非轨迹匹配),接受有效替代动作序列
-
论文用途:
- 仅用于评测(非训练),测试开环规划器、反应式智能体与VAGEN风格思维链三类范式
- 通过任务成功率(TSR)、物理合理性评分(PPS)及动作保真度评分(AFS)评估,辅以人类偏好研究
- 任务采用固定视角单房间设置,避免视频生成模型的空间不一致性
方法
作者提出ORCA(在线推理与认知架构)框架,使生成式视频虚拟人具备目标导向的长时程交互能力。ORCA基于两大创新设计:受内部世界模型(IWM)理论启发的闭环观察-思考-行动-反思(OTAR)循环与分层双系统架构。这些组件协同工作,在图像到视频(I2V)生成的随机性中维持精确信念状态,并弥合高层战略推理与底层执行保真度之间的鸿沟。
框架以初始场景和用户意图为起点持续运行。战略规划器系统2首先通过场景分析将意图分解为子目标结构化计划,初始化信念状态s^0。该过程由精心设计的提示词引导,强制要求可验证的顺序结果,并利用预训练视觉语言模型(VLM)的广博世界知识。如框架图所示,初始化阶段通过建立任务清单和物体状态跟踪为后续推理奠定基础。
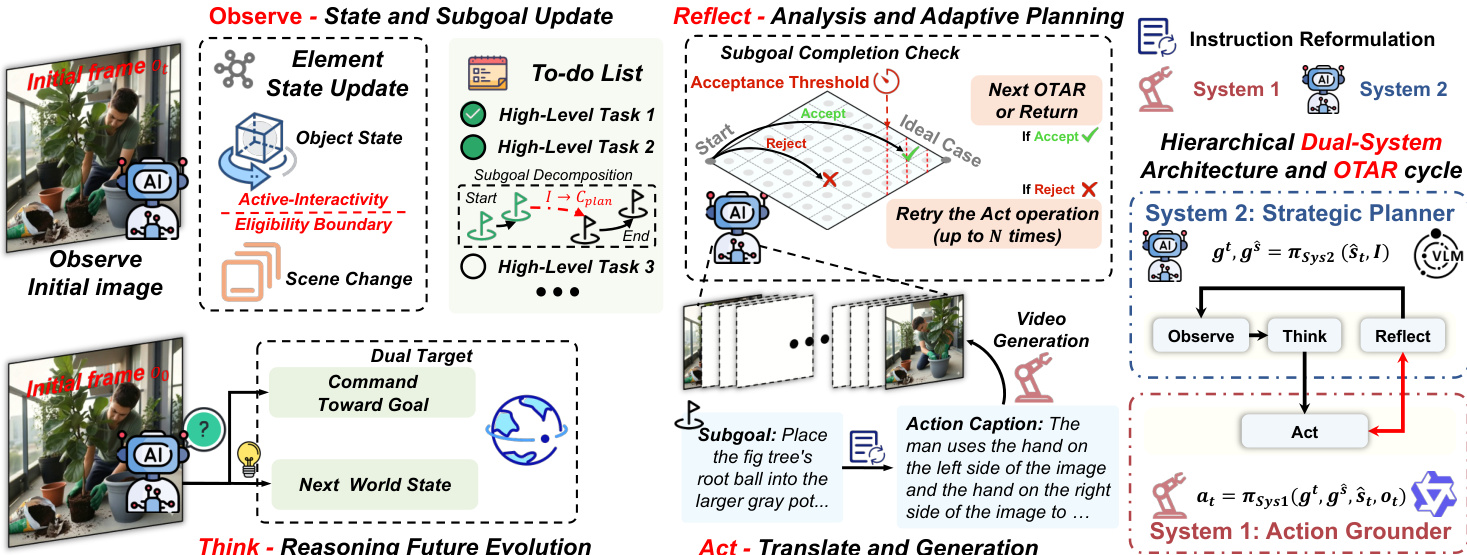
在每个时间步t,观察阶段利用最新视频片段ot和前一信念s^t−1更新信念状态s^t。该更新整合场景变化、物体状态转换及子目标完成状态,确保智能体维持精确的环境内部模型。随后思考阶段中,系统2基于当前信念状态s^t、原始意图I和当前观测ot推理生成文本指令gt与预测下一状态gs^。该战略推理形式化为:
gt,gs^=πSys2(s^t,I)生成的指令与预测状态传递至动作落地器系统1,后者将抽象计划转化为精确的模型特定动作描述at。该落地过程对可靠生成至关重要,因不同I2V模型对提示词表述敏感。落地策略定义为:
at=πSys1(gt,gs^,ot,s^t)行动阶段通过I2V模型Gθ基于当前场景ot和生成描述at采样视频片段vt+1执行动作:
vt+1∼Gθ(ot,at)反思阶段是ORCA闭环设计的关键。系统2将实际结果ot+1与预测状态gs^比对,判定动作是否成功(二元决策δt∈{accept,reject})。若结果被拒绝,系统将重试动作(最多限定次数)或触发自适应重规划。这防止生成失败导致的信念污染,确保智能体内在状态与现实一致。循环持续至所有子目标完成。

整个流程无需任务特定训练,依赖Gemini-2.5-Flash等预训练VLM的结构化提示实现系统1/2功能,并采用蒸馏I2V模型(Wanx2.2+LoRA)生成视频。各模块提示词(初始化/观察/思考/动作落地/反思)均经精心设计,强制结构化输出与领域约束,确保跨多样开放域场景的战略连贯性与执行保真度.
实验
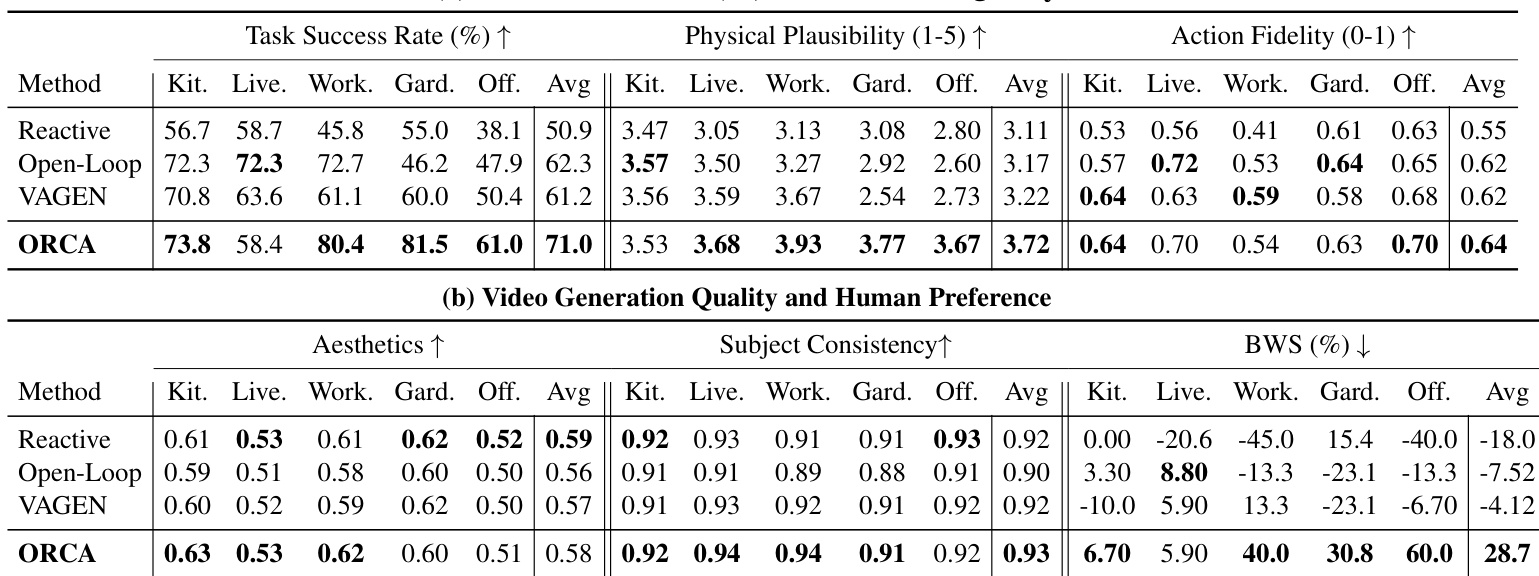
- 在L-IVA基准上采用人机混合评测:ORCA在5大场景(厨房/直播/车间/花园/办公室)中取得71.0%平均任务成功率(TSR)与3.72物理合理性评分,全面超越基线
- 在高依赖性任务(花园/车间)中表现突出,闭环反思防止错误累积;开环规划器在低依赖性场景(厨房/直播)因步数预算效率仍具竞争力
- 通过最佳-最差缩放(BWS)与主体一致性获得最高人类偏好,验证闭环世界建模平衡了任务完成与执行可靠性
- 消融实验确认信念状态跟踪(缺失时TSR骤降)、反思验证与分层动作规范对精确指令落地的关键作用
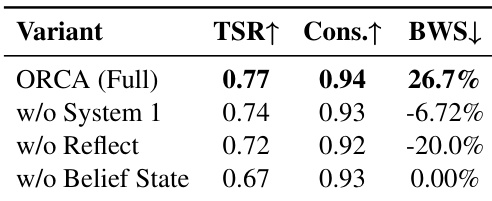
作者在车间场景测试ORCA消融变体:移除系统1、反思或信念状态均导致性能下降。完整ORCA取得最高任务成功率(77%)、主体一致性(0.94)及BWS得分(26.7%),证实三大组件对鲁棒长时程执行的必要性。移除信念状态导致TSR最大降幅,缺失反思则最损害人类偏好.
作者采用人机混合评测框架在L-IVA上评估智能体,从任务成功、物理合理性、动作保真度、主体一致性及人类偏好五维度衡量。结果显示ORCA取得最高平均任务成功率(71.0%)与物理合理性(3.72),同时在主体一致性(0.93)和人类偏好(BWS 28.7%)领先,证明其带反思的闭环架构有效性。尽管开环规划器在厨房/直播等低依赖场景表现尚可,但因未检测执行错误导致主体一致性差且人类偏好为负;反应式智能体与VAGEN则因缺乏世界建模或未修正幻觉,任务完成率与物理合理性较低.