Command Palette
Search for a command to run...
Step-DeepResearch 技术报告
Step-DeepResearch 技术报告
摘要
随着大语言模型(LLMs)逐步向自主智能体(autonomous agents)演进,深度研究(Deep Research)已成为衡量模型能力的关键指标。然而,现有的学术基准测试(如BrowseComp)往往难以满足现实世界中开放式研究任务的需求,这类任务要求模型具备强大的意图识别能力、长周期决策能力以及跨源信息验证能力。为应对这一挑战,我们提出Step-DeepResearch——一种成本高效、端到端的智能体架构。该方法引入基于原子能力的数据合成策略,以强化任务规划与研究报告生成能力,并采用从智能体中期训练到监督微调(SFT)再到强化学习(RL)的渐进式训练路径。通过引入清单式评估机制(Checklist-style Judger),该方法显著提升了系统的鲁棒性。为进一步弥合中文领域在评估体系上的差距,我们构建了ADR-Bench,旨在模拟真实场景下的深度研究任务。实验结果表明,Step-DeepResearch(32B规模)在Scale AI研究评估标准下的得分为61.4%。在ADR-Bench基准上,其性能显著优于同类开源模型,并接近甚至媲美OpenAI与Gemini DeepResearch等领先闭源模型。上述成果证明,经过精细化训练的中等规模模型,能够在保持行业领先成本效益的同时,实现专家级的深度研究能力。
一句话总结
StepFun 研究团队提出 Step-DeepResearch——一款面向开放式深度研究任务的高性价比 320 亿参数智能体模型,创新性地引入基于原子能力的数据合成策略及清单式奖励系统的渐进训练方法。该模型在 RESEARCHRUBRICS 基准测试中达到专家级性能(61.42 分),并在新构建的中文基准测试中表现优异,性能媲美 OpenAI DeepResearch 等商业服务,同时显著降低部署成本。
核心贡献
- 现有深度研究评估体系(如 BrowseComp)聚焦于具有标准答案的学术多跳搜索,无法应对真实场景中需隐式意图识别、长周期决策及跨源验证的开放式研究需求。此局限导致尽管 OpenAI DeepResearch 等工业系统取得进展,智能体实用性仍受制约。
- 作者提出 Step-DeepResearch:320 亿参数智能体,通过基于原子能力(规划、信息检索、反思与报告撰写)的创新数据合成策略训练,并采用从智能体中期训练到监督微调及清单式评判器奖励强化学习的渐进式训练流程。
- 在覆盖商业、政策与软件工程场景的新型中文 ADR-Bench 基准测试中,Step-DeepResearch 以 61.42 分刷新 RESEARCHRUBRICS 记录,超越开源模型,且在专家 Elo 评分中媲美 OpenAI DeepResearch 与 Gemini DeepResearch,验证了高性价比的专家级性能。
引言
作者指出:真实世界的深度研究——处理开放式复杂信息检索任务——需超越学术多跳问答的能力,包括隐式意图识别、长周期规划、跨源验证与结构化综合。现有智能体系统要么过度优化受限基准(如 BrowseComp)中的检索精度,导致产出碎片化的"网络爬虫"而非连贯研究者;要么依赖复杂多智能体编排,增加部署成本并降低实际场景鲁棒性。为弥合此差距,作者提出 Step-DeepResearch:通过原子能力数据合成策略(将研究拆解为可训练技能:规划、反思、验证)及从中期训练到强化学习的渐进式训练流程,实现单一智能体内化专家级认知循环。该端到端方法以高性价比达成媲美大型商业系统的优质研究能力,同时解决真实场景可用性缺口。
数据集
作者通过三种核心方法构建合成训练数据集,弥补现有研究基准的不足:
-
数据集构成与来源
核心训练数据源自高质量开放源:开源技术报告、学术综述、金融研报、Wikidata5m 与 CN-DBpedia 知识图谱。此方法确保覆盖真实研究复杂性,弥补公开基准深度不足。 -
关键子集详情
- 规划与任务分解数据:通过 LLM 从报告标题/摘要反向推导复杂查询与可行计划,经轨迹一致性校验筛选与预设计划匹配的路径。
- 推理数据:基于图合成(Wikidata5m/CN-DBpedia 的 10-40 节点子图)与多文档遍历(利用 Wiki-doc 超链接)构建,使用 QwQ-32b 过滤可解的"简单问题"。
- 反思与验证数据:通过闭环流水线生成自修正与事实核查数据,融入结构化噪声(如带恢复步骤的工具错误)。
- 报告数据:中期训练采用筛选后的人工报告(如金融分析)中的〈查询, 报告〉对,查询由文档内容反向推导。
-
模型训练应用
- 中期训练:聚焦原子能力(规划、检索),使用领域化〈查询, 报告〉对及推理子集。
- SFT 阶段:优化比例混合两类轨迹:
- 深度搜索:优先"正确且最短"轨迹的基准答案任务,提升效率。
- 深度研究:覆盖全流程(规划至引用丰富报告)的开放式任务,占比主体以强化端到端逻辑。
混合比例侧重深度研究数据,契合真实场景需求。
-
处理与质量控制
- 轨迹效率过滤仅保留最小步数成功路径。
- 严格 N-gram 去重消除重复推理循环。
- 报告强制采用 \cite{} 引用格式确保事实依据。
- 注入可控噪声(如 5-10% 工具错误)提升真实场景鲁棒性。
评估采用 ADR-Bench:涵盖九领域 90 个真实用户查询(20 个专业法律/金融,70 个通用),经领域专家严格验证。
方法
作者采用 ReAct 启发的单智能体架构构建 Step-DeepResearch 系统,通过交替生成思考与工具交互实现动态迭代推理。如下图所示,智能体接收用户查询后启动多轮循环:在 <tool_call> 标签内进行内部推理,通过 <toolcall> 调用外部工具,工具响应反馈至下一轮推理。循环持续至智能体生成 <answer> 标记的最终报告,输出为结构化文档。
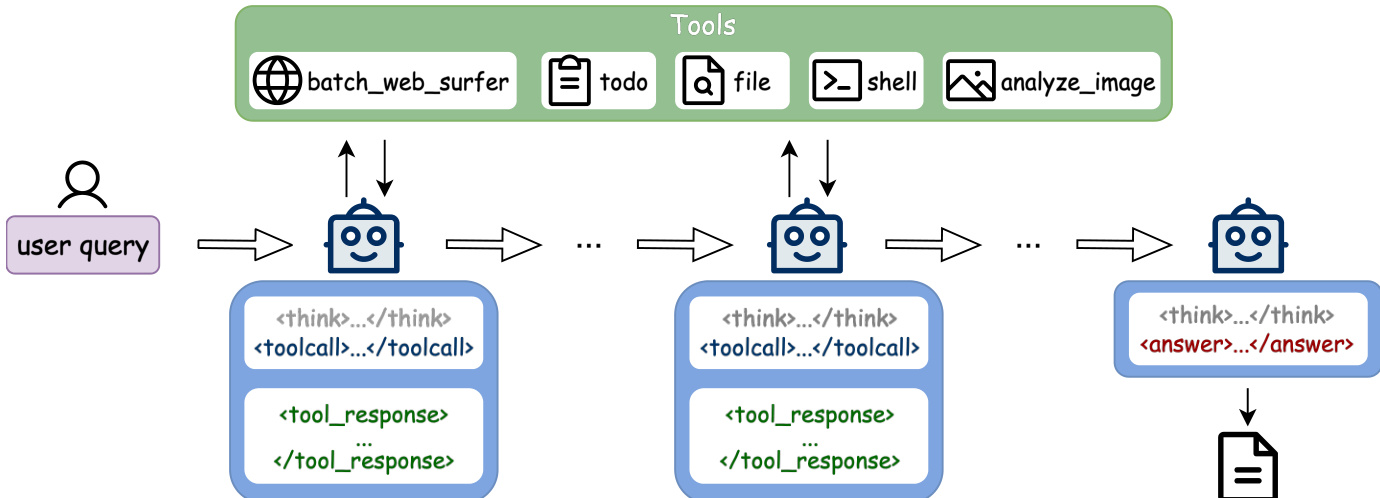
智能体核心操作循环由统一工具系统支撑,实现能力对齐、信息适配与架构简化。关键工具包括:高精度检索的 batch_web_surfer、状态化任务跟踪的 todo、高效文档编辑与本地存储的 file、沙盒终端执行的 shell,以及多模态感知的 analyze_image。这些工具不仅是封装层,更设计保留类人交互逻辑,同时优化 token 效率与长上下文鲁棒性。
信息获取采用精选权威索引策略,隔离 600+ 权威域名确保事实依据。知识密集检索以段落级粒度最大化单 token 信息密度,权威感知排序策略在语义相关性相当时优先高可信源。执行中,智能体通过基于补丁的编辑协议减少报告优化的 token 开销,并采用摘要感知本地存储机制将上下文压力卸载至磁盘,实现近无限上下文支持。
为支持长周期推理,系统集成状态化 todo 管理,将研究进度与模型权重解耦,确保长轨迹目标一致性。通过 tmux 集成沙盒增强交互执行,稳定运行状态化命令行工具;感知优化浏览器通过感知哈希比对抑制冗余视觉反馈,降低多模态 token 冗余。
智能体行为由策略 πθ 驱动:将状态(含用户意图、历史 token 与工具观测)映射至动作(自然语言生成或结构化工具调用)。训练分三阶段:中期训练植入原子能力,监督微调确保指令遵循与格式规范,强化学习优化真实任务性能。RL 阶段中,智能体在显式预算约束的多工具环境中交互,性能由基于量规的奖励系统评估。奖励信号源自训练的 Rubrics Judge 模型:将细粒度量规判断映射为二元信号(1 或 0),仅当量规完全满足时赋值 1,消除中间类别的模糊性。策略更新采用裁剪 PPO 目标,通过 GAE(γ=1,λ=1)进行优势估计,简化长周期稀疏奖励场景的信用分配。
实验
- 阶段一中期训练(32K 上下文)验证结构化推理提升:1500 亿 token 后 FRAMES 基准测试提升 +10.88%,SimpleQA(+1.26%)与 TriviaQA(+2.30%)持续改善。
- 阶段二中期训练(128K 上下文)验证真实任务中工具增强推理能力,支持超长上下文下的检索与多工具协作。
- Step-DeepResearch 在 RESEARCHRUBRICS 基准测试获 61.42 分,超越开源模型 +5.25(如 Kimi-k2-thinking),逼近 Gemini DeepResearch(63.69),单份报告成本低于 0.50 元——不足 Gemini(6.65 元)的十分之一。
- ADR-Bench 人工评估中,Step-DeepResearch 在 70 场对比中击败非中期训练版本 30 次,对顶级商业系统达到 67.1% 非劣效率,在 AI/ML(64.8)、历史分析(65.8)与技术文档(64.6)领域领先。