Command Palette
Search for a command to run...
TongSIM:一种用于模拟智能机器的通用平台
TongSIM:一种用于模拟智能机器的通用平台
摘要
随着人工智能(AI)的迅速发展,尤其是在多模态大语言模型(MLLMs)领域,研究重点正从单一模态的文本处理,逐步转向更为复杂的多模态与具身智能(embodied AI)领域。具身智能致力于在高度逼真的模拟环境中训练智能体,通过物理交互与动作反馈来学习,而非依赖传统的标注数据集。然而,目前大多数现有的仿真平台仍局限于特定任务,设计目标较为狭窄。能够支持从底层具身导航到高层复合任务(如多智能体社会模拟和人-机协作)的通用、多功能训练环境,目前仍十分缺乏。为弥合这一差距,我们提出 TongSIM——一个高保真、通用的具身智能体训练与评估平台。TongSIM 具备多项实用优势:提供超过100种多样化的多房间室内场景,以及一个开放式的、交互丰富的室外城镇仿真环境,可广泛适配各类研究需求。其全面的评估框架与基准测试体系,能够对智能体的感知、认知、决策、人-机器人协作、空间推理与社会推理等能力进行精准评估。TongSIM 支持自定义场景、任务自适应仿真精度、多种类型智能体以及动态环境演化等特性,为研究人员提供了高度的灵活性与可扩展性。该平台作为统一的科研基础设施,将显著加速具身智能体的训练、评估与通用具身智能的发展进程。
一句话总结
BIGAI 研究团队等提出 TongSIM,一个高保真通用具身智能平台,通过 100+ 多房间室内场景和开放世界城镇模拟突破传统任务专用模拟器的局限。该平台支持通过可定制场景和动态环境保真度统一训练与评估导航、社会模拟及人机协作任务,推动面向通用具身智能的可扩展研究。
核心贡献
- 现有具身智能模拟平台局限于特定任务,缺乏能同时支持底层导航与高层复合活动(如多智能体社会模拟和人机协作)的通用环境。
- TongSIM 引入高保真通用平台,包含 100+ 多样化室内场景和开放世界城镇模拟,提供可定制场景、任务自适应保真度、多样化智能体形态及动态环境模拟,实现灵活的智能体训练。
- 平台提供涵盖单智能体、多智能体、人机交互及家庭复合任务的五大基准测试类别,全面评估智能体在感知、认知、决策和社会推理方面的能力。
引言
具身智能研究日益依赖真实模拟环境,通过物理交互(而非标注数据集)训练智能体,从单一模态文本处理迈向多模态与社会智能。然而现有平台仍局限于导航或物体操作等特定任务,迫使研究者在简化物理的高速模拟与高保真物理但计算成本过高的方案间权衡,且缺乏对多智能体社会动态或人机协作等复杂场景的支持。作者针对这些缺口推出 TongSIM——统一高保真平台,包含 100+ 多样化室内场景和开放世界城镇模拟。它通过可定制环境、任务自适应保真度及综合基准测试套件,独特支持底层具身导航与高层复合任务,评估感知、空间推理和社会交互能力,实现通用具身智能的可扩展训练与评估。
数据集
作者通过 TongSIM 平台提供多样化的模拟环境用于智能体训练与评估,结构如下:
-
数据集构成与来源:
数据集包含 115 个专家设计的室内场景及统一的城市级户外大都会,均由 TongSIM 模拟平台生成。 -
关键子集详情:
- 室内场景(共 115 个):由专业设计师手动构建,确保语义真实性和符合人类行为逻辑。覆盖现代、中世纪、传统日式/中式等建筑风格的住宅单元、咖啡馆及零售店。通过自动化流程从初始专家布局扩展而来。
- 户外场景:连贯的虚拟大都会,整合教育、居住、商业及医疗区域,配备完整道路网络与动态交通系统,支持跨空间连接区域的无缝长程导航。
-
论文中的应用:
数据用于训练和评估 Multi-Agent Cooperative Search (MACS) 基准测试中的智能体——需在部分可观测条件下协作应对洪水后场景。核心任务包括:- 多智能体物资收集
- 规避随机动态危险
- 基于局部感官数据的节能导航
环境配置为连续 2D 动作空间(Box(-1.0, 1.0))及径向射线传感器的高维观测。
-
处理与元数据:
室内场景通过专家布局自动化扩展;户外区域保持空间连续性以支持上下文导航。MACS 任务采用径向射线模拟部分可观测性(绿色传感器线可视化),训练阵列中智能体感知范围由蓝色虚线圆周定义。无显式裁剪——平台利用全场景连续性实现整体任务执行。
方法
作者采用模块化引擎驱动架构构建 TongSIM,专为具身智能研究设计的模拟平台。系统核心集成 Unreal Engine 5.6 与基于 Python 的控制层,实现高保真渲染与程序化智能体操控的双向通信。这种双栈设计同时支持底层物理模拟与高层任务编排,为可扩展智能体训练与评估奠定基础。
参考框架图,该图展示了平台的分层结构。基础设施层结合 Unreal Engine 的原生渲染与物理能力及 Python SDK,使开发者能动态实例化物体、管理场景并获取实时状态数据(包括语义分割、物体元数据和导航网格)。此接口支持对智能体形态的精细控制,可执行运动基元及倾倒液体、组装家具等复杂多步交互。
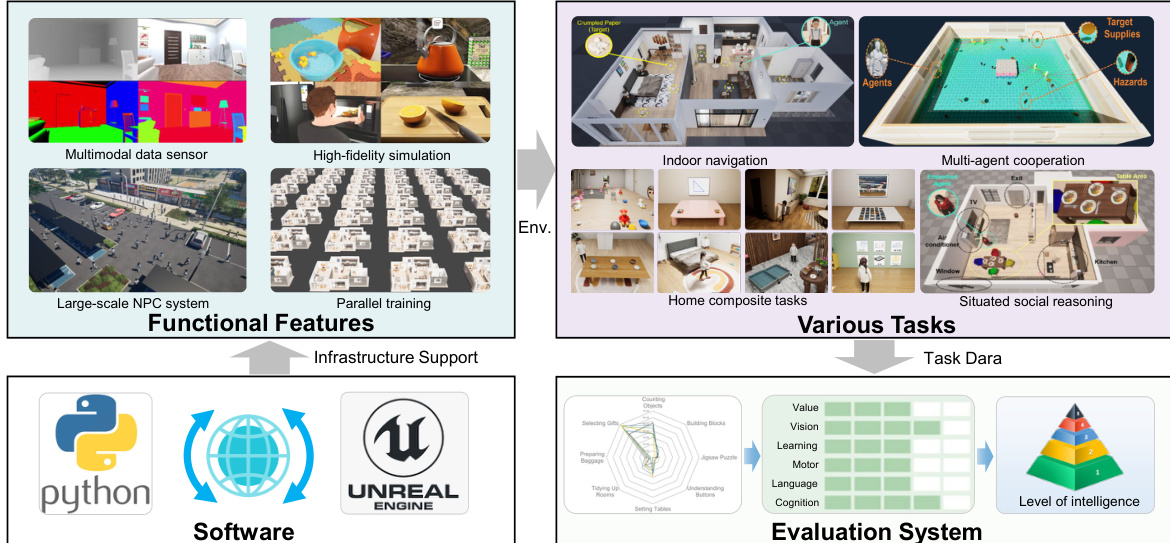
模拟环境通过四大功能模块增强:多模态数据传感器(感知)、高保真渲染(视觉真实感)、大规模 NPC 系统(社会动态)及并行训练基础设施(可扩展实验)。这些模块共同支持多样化具身任务——从室内导航、家庭复合活动到多智能体协作及情境社会推理。每个环境均配备提供真实数据的场景管理器(包括生成点、语义标注和烘焙导航网格),支持基于规则与学习的智能体控制。
为确保环境多样性与泛化性,作者实现两阶段程序化生成流程:粗粒度阶段将现有室内场景分解为功能单元(如厨房、卧室),以门框为对齐锚点随机重组;细粒度阶段通过随机物体摆放及精选物体库的资源替换引入微变体。此过程经人工协同校验剔除语义不合理配置。
平台智能体系统同时支持 AI 驱动形态与基于规则的 NPC,由混合控制机制管理(结合确定性逻辑与大语言模型决策)。智能体具备丰富动作空间,涵盖底层运动基元、目标导向导航及高层复合行为。物体交互通过协议系统实现,定义 28 种交互基元(包括机电逻辑(解耦电源状态与激活状态)和空间交互锚点(如精确物体对接的放置点))。
为实现物理真实感,TongSIM 利用 Unreal 的 Chaos 物理引擎模拟刚体、流体及可变形材料。作者还集成 NVIDIA Flex 作为实验扩展,实现跨异构物体类型的统一粒子模拟。该能力对评估现实物理约束下的具身智能体至关重要(如操控液体容器时需考虑质心偏移)。
评估框架分层设计,从底层运动与感知到高层社会智能及多智能体协作多维度评估智能体。针对座位安排等复杂任务引入标准化测试流程,要求智能体提取 NPC 偏好、构建环境表征并生成多约束解。性能通过优先级差距(PG)等指标量化,定义为:
PG=Shigh−Slow其中 Shigh 和 Slow 分别表示高权重与低权重偏好的满足率。
如下图所示,平台还支持带标准 ROS2 接口的实时机器人模拟,实现与机器人控制栈的无缝集成。此桥梁便于在动态社会环境中测试,智能体需导航真实感人群并响应行人避让等安全关键场景。

最后,平台支持情境规划任务(如社会座位安排),智能体需综合环境知识、NPC 偏好及空间约束生成最优配置。如下图所示的工作流,阐释了具身探索、社会交互建模与情境规划如何汇聚,在现实约束下评估高层推理。
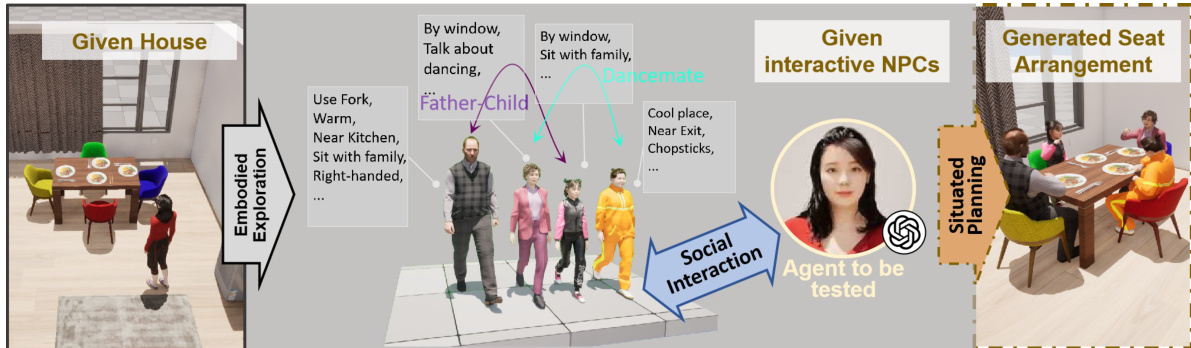
架构具备可扩展性,通过标准化 API 和第三方资源导入(glTF, FBX, Datasmith)支持自定义任务创建。这种灵活性使研究者能构建领域特定场景——从家庭服务任务到极端环境操作——不受预定义基准测试限制.
实验
- 空间探索任务验证并行训练机制:随环境数量增加,每秒步数实现近线性扩展,高并行度时因系统开销达到饱和.
- 空间探索基准(清理任务):PPO 强化学习智能体成功率达 60%,因障碍规避和长程导航能力不足显著落后于人类表现.
- MACS 任务的多智能体强化学习评估:MAPPO 以 19.24 对 14.75 的平均每智能体回合回报超越 IPPO,证实集中式训练对多智能体协调的有效性.
- 动态人群中的社会导航:人类遥操作总分 92.7,而 MPPI 规划器得 43.1,DWA 失败(10.4),凸显传统规划器缺乏社会认知.
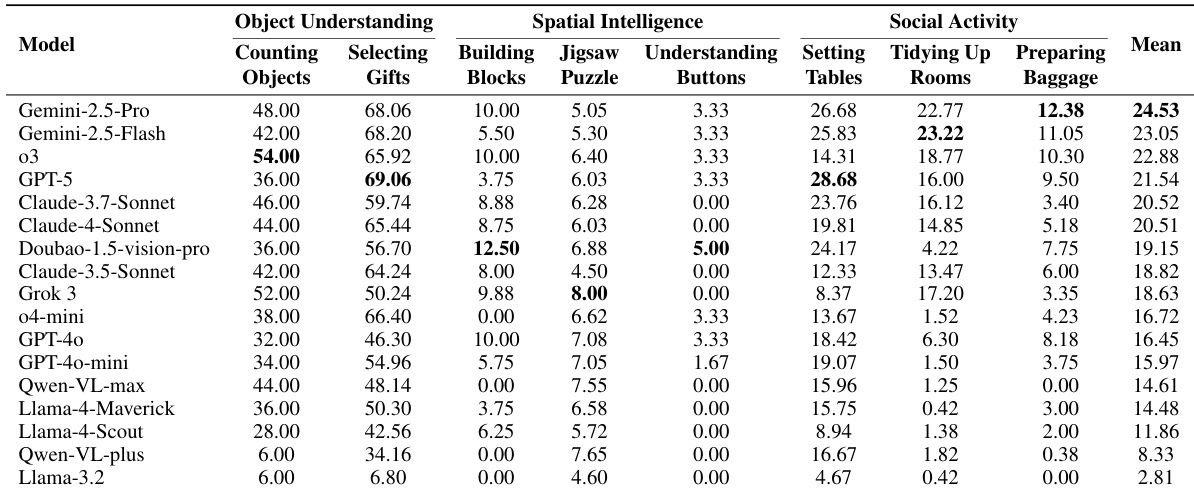
- 家庭任务的大语言模型评估:Gemini-2.5-Pro 以平均 24.53/100 分领先,空间智能被识别为所有模型的最弱领域.
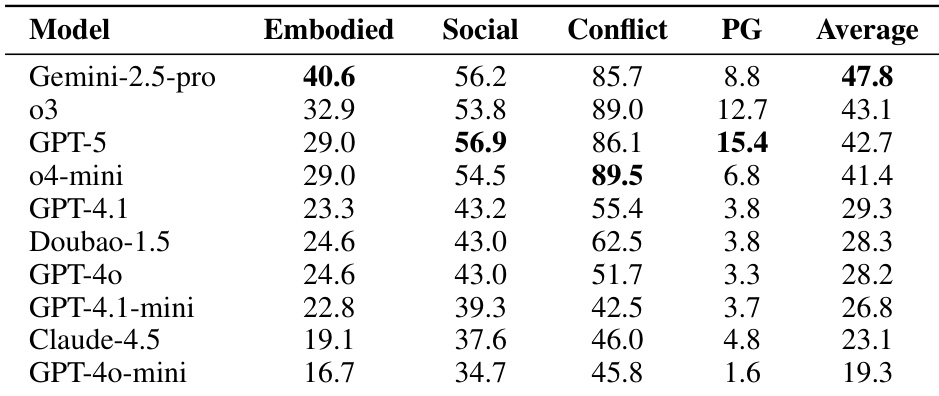
- S³IT 基准测试:Gemini-2.5-Pro 得 47.8 分,证明空间智能是具身社会推理的基础,而模型在具身维度表现持续不足.
作者在拥挤社会环境中使用效率、成功率、安全性和社会规范合规性指标评估三种导航策略.人类遥操作获得最高总分 92.7,显著优于自动化规划器:A* + DWA 仅 10.4 分(因频繁碰撞且零安全合规),A* + MPPI 提升至 43.1 但仍远落后于人类.结果证实缺乏社会推理的传统规划器无法安全适当地导航动态人群.

作者在空间探索与导航任务中对比 PPO 训练的强化学习智能体与人类操作者,发现智能体成功率为 60%、效率为 0.34,显著低于人类基线(100% 成功率、0.54 效率).结果表明智能体在杂乱环境中面临障碍规避和长程导航困难.

结果显示 Gemini-2.5-pro 在 S³IT 基准测试中以 47.8 的平均分领先,主要归功于其在具身维度(40.6)的卓越表现.所有模型在具身与社会维度得分均低于冲突解决,证实空间智能是具身社会推理的关键瓶颈.GPT-5 展现出最强的偏好优先级处理能力,其优先级差距得分最高(15.4).
作者在协作任务中评估两种多智能体强化学习算法,发现采用集中训练分散执行范式的 MAPPO 获得更高平均每智能体回合回报(19.24),优于完全分散的 IPPO(14.75).结果显示两种基于学习的方法均显著超越随机策略基线,表明训练中利用全局状态信息可改善智能体协调.

作者在涵盖物体理解、空间智能和社会活动领域的复合具身任务基准测试中评估 17 个大语言模型.结果显示即使表现最佳的 Gemini-2.5-Pro 也仅获平均 24.53/100 分,揭示具身推理能力存在显著差距.空间智能任务(如积木搭建和解谜)在所有模型中持续得分最低,凸显物理推理与操作规划的关键缺陷.