Command Palette
Search for a command to run...
棱镜假说:通过统一自编码实现语义与像素表征的融合
棱镜假说:通过统一自编码实现语义与像素表征的融合
Weichen Fan Haiwen Diao Quan Wang Dahua Lin Ziwei Liu
摘要
跨模态的深度表征本质上是相互关联的。本文系统地分析了各类语义编码器与像素编码器的谱特性。令人瞩目的是,我们的研究揭示了一种极具启发性且长期被忽视的对应关系:编码器的特征谱与其功能角色之间存在紧密联系——语义编码器主要捕捉编码抽象语义的低频成分,而像素编码器则额外保留了传递精细细节的高频信息。这一启发性发现为理解编码器行为提供了统一的视角,将其与底层的谱结构直接关联。我们将其归纳为“棱镜假说”(Prism Hypothesis),即每种数据模态可被视为自然世界在共享特征谱上的投影,如同光通过棱镜发生色散。基于这一洞察,我们提出统一自编码模型(Unified Autoencoding, UAE),该模型通过一种创新的频带调制机制,实现语义结构与像素细节的和谐融合,使二者在潜空间中实现无缝共存。在ImageNet与MS-COCO等基准数据集上的大量实验表明,所提出的UAE能够有效将语义抽象性与像素级保真度统一于单一潜空间中,并在多项指标上达到当前最优性能。
一句话总结
南洋理工大学与商汤研究院的研究人员提出统一自编码器(Unified Autoencoding, UAE),引入棱镜假设(Prism Hypothesis):语义编码器捕获低频全局语义,而像素编码器保留高频细节。UAE创新性地采用频带调制器,在单一潜在空间内协调这两种表征,有效融合语义抽象与像素保真度,在ImageNet和MSCOCO基准测试中实现最先进性能。
核心贡献
- 论文指出基础模型存在关键割裂问题:语义编码器(聚焦高层语义)与像素编码器(保留细节)在分离的异构特征空间中独立运行,导致表征冲突和训练效率下降。
- 提出棱镜假设,揭示语义编码器主要捕获低频谱分量以表征抽象语义,而像素编码器保留高频细节;并设计统一自编码器(UAE),通过频带调制器将二者融合至单一潜在空间。
- 在ImageNet和MSCOCO上的广泛验证表明,UAE在重建指标(rFID、PSNR、gFID)和感知任务(准确率)上均达到最先进水平,通过有效统一语义抽象与像素保真度,性能超越RAE和SVG等同期方法。
引言
作者指出视觉基础模型中的关键割裂问题:语义编码器(捕获高层语义)与像素编码器(保留视觉细节)在分离且互不兼容的潜在空间中运行。这种分离迫使下游系统协调异构表征,降低训练效率并导致表征冲突,损害联合感知-生成任务的性能。现有方法要么将语义知识迁移至生成流程(牺牲细节还原能力),要么通过蒸馏和分层特征将像素级感知注入语义模型,仅能通过折衷实现部分整合,而非真正统一。
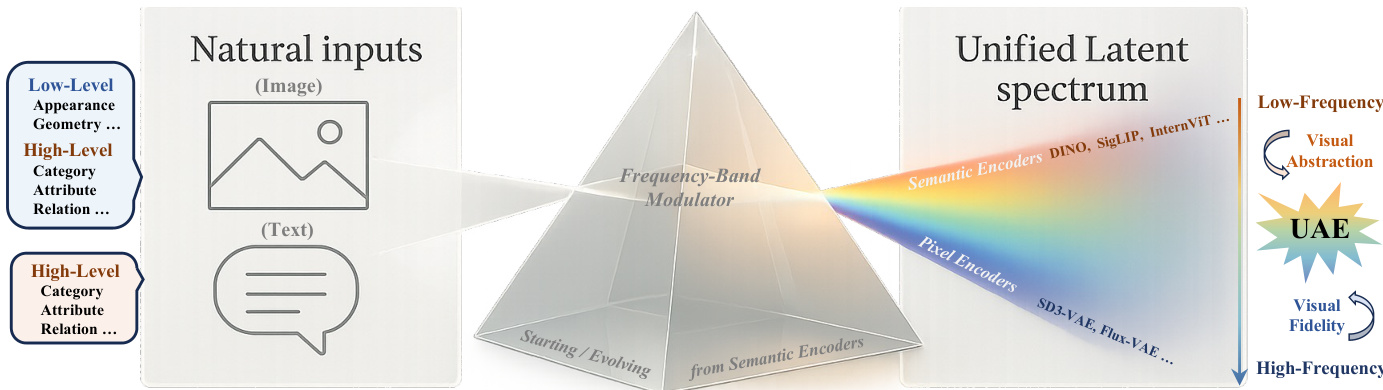
作者提出棱镜假设:自然输入投射到连续频谱上,低频段编码全局语义(如类别与关系),高频段捕获局部纹理与几何结构。基于此,他们设计统一自编码器(UAE)——一种利用频带调制器在单一潜在空间内协调语义与像素表征的分词器。该调制器显式地将内容分解为基础语义频带与残差像素频带,实现可控细节重建。UAE在ImageNet和MS-COCO上超越RAE、SVG和UniFlow等同期统一分词器,在重建(rFID、PSNR)和感知(gFID、准确率)指标上均取得最优结果,证明频谱分解能在无损抽象能力的前提下解决保真度矛盾。
数据集
作者使用两个主要数据集进行训练与评估:
- 训练数据:ImageNet-1K训练集(标准128万张图像),分辨率处理为256×256。除分辨率外未描述额外过滤或裁剪策略。
- 评估数据:
- ImageNet-1K验证集(标准5万张图像)用于分类基准测试。
- MS-COCO 2017验证集用于跨数据集泛化测试。
关键实现细节:
- 模型(UAE)仅在ImageNet-1K训练集上训练,使用DINOv2-B或DINOv2-L作为语义编码器。
- 训练分三阶段进行:
- 固定编码器,仅训练解码器(重建损失)
- 全模型微调(语义损失+重建损失)
- 端到端微调(噪声注入+GAN损失,沿用RAE方法)
- 除分辨率缩放外,未指定数据集混合比例、元数据构建或显式预处理步骤。
方法
作者基于棱镜假设设计统一自编码器(UAE),通过显式建模视觉表征的频谱分解,在单一潜在空间内融合语义抽象与像素级保真度。核心洞见在于:自然输入投射到共享频谱,低频分量编码语义结构,高频段捕获细粒度视觉细节。UAE通过分解潜在表征为频带并进行调制,同时保留全局语义与局部保真度。
参考框架图示,自然输入(图像与文本)经频带调制器映射至统一潜在频谱。DINOv2或CLIP等语义编码器主要占据低频区域(编码视觉抽象),SD-VAE等像素编码器则延伸至高频区域(保留视觉保真度)。UAE通过从预训练语义模型初始化编码器,并经联合优化扩展其频谱覆盖范围,实现跨模态融合。
架构始于从预训练语义编码器(如DINOv2)初始化的统一编码器,将输入图像处理为潜在网格 z∈RB×C×H×W。该潜在表示经FFT频带投影器与迭代分割过程,分解为 K 个频带 zf∈RB×K×C×H×W。投影器应用二维离散傅里叶变换,通过平滑径向掩码 Mk 划分频谱,并将各频带转换回空间域。迭代分割确保解耦:从 r(0)=z 开始,逐级提取频带 zf(k)=Pk(r(k)) 并更新残差 r(k+1)=r(k)−Pk(r(k))。最终得到多频带潜在表示,其中低频带编码全局语义,高频带捕获边缘与纹理。
如下图所示,分解后的频带由频带调制器处理。训练时,噪声注入模块仅对高频带进行扰动:使用二值掩码 m 与高斯噪声 N(0,σ2I) 增强解码器鲁棒性。处理后的频带沿通道拼接,经频谱变换模块(含SiLU激活的双层卷积块)预测残差 Δ。最终融合潜在表示 q=Δ+∑k=0K−1b(k) 保持原始空间维度,并输入基于ViT的像素解码器重建RGB图像。
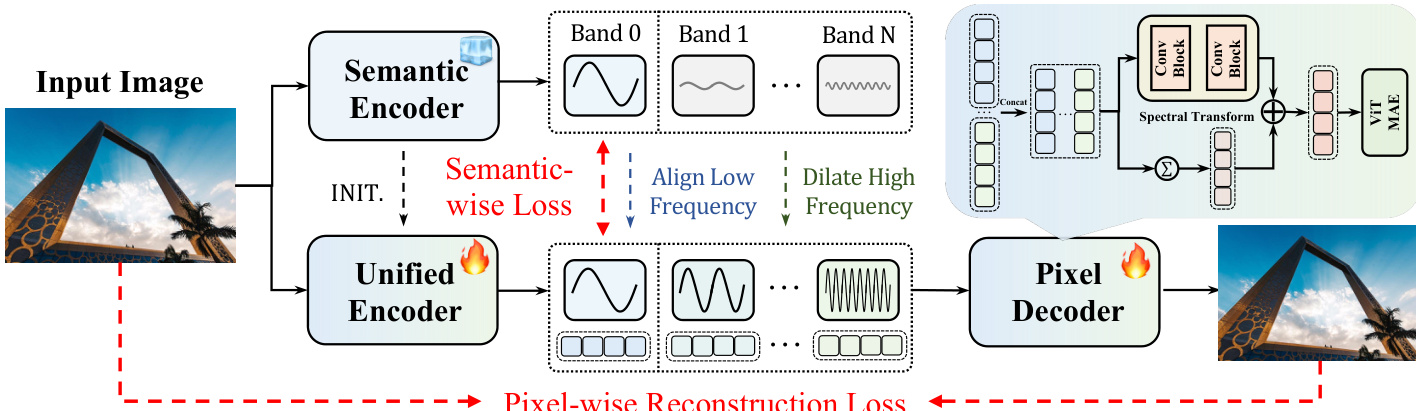
训练由两个互补目标引导。语义损失仅在最低 Kbase 个频带(通常 Kbase=1)上强制统一编码器与冻结语义编码器对齐:
Lsem=Kbase∑k=0Kbase−1∥fuk−fsk∥22此操作保留教师模型的语义布局,同时允许高频带自由学习像素级细节。同步进行的像素级重建损失(解码输出与原始图像间)确保视觉保真度。联合优化在单一潜在空间内协调语义结构与像素细节,使UAE在不牺牲抽象能力或保真度的前提下统一多模态表征。
实验
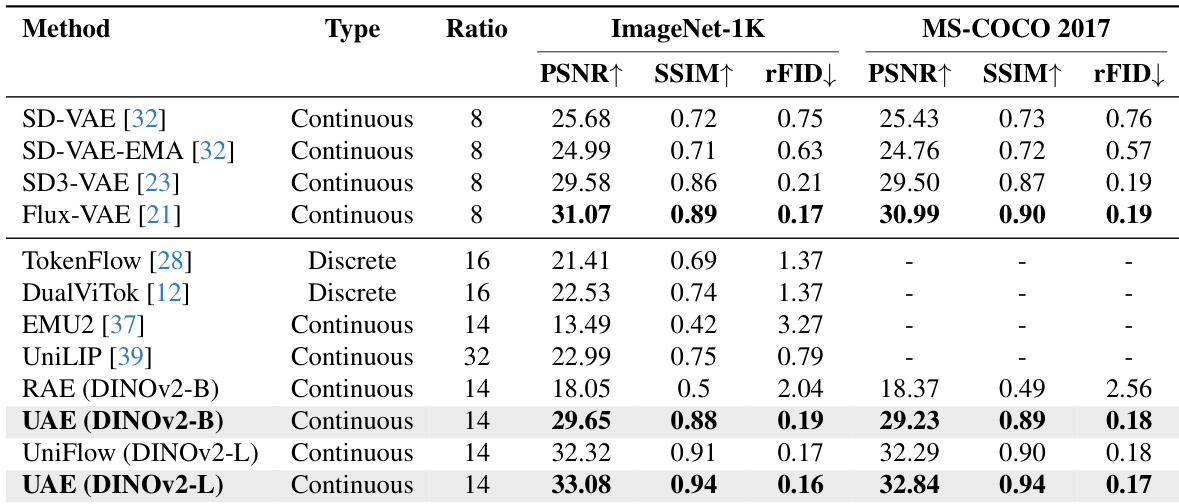
- 视觉重建:在ImageNet-1K上使用DINOv2-base时,UAE达到29.65 PSNR和0.19 rFID,较RAE基线(18.05 PSNR, 2.04 rFID)将rFID降低90%以上,性能匹配Flux-VAE/SD3-VAE。在MS-COCO上达到29.23 PSNR和0.18 rFID。升级至DINOv2-L后,获得33.08 PSNR和0.16 rFID,验证频谱感知分解对细节保留的有效性。
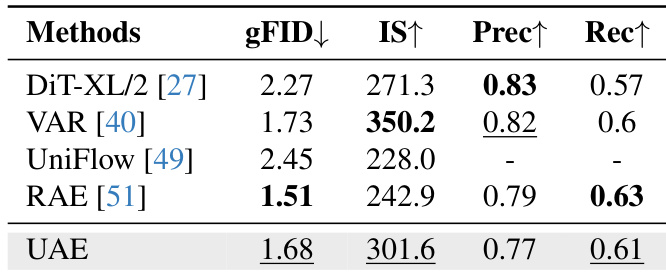
- 生成建模:在ImageNet类别条件生成任务中,UAE取得1.68 gFID和301.6 IS,通过渐进式低频到高频生成,性能匹配最先进的扩散模型与自回归模型。
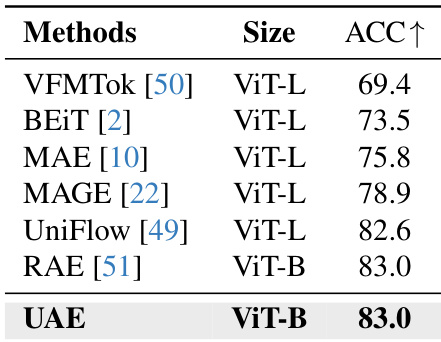
- 语义理解:ImageNet-1K上线性探针测试中,ViT-B骨干网取得83.0% top-1准确率,超越VFMTok(69.4%)和BEiT(73.5%),与UniFlow(82.6%)等更大模型持平,证实统一潜在空间的强语义保留能力。
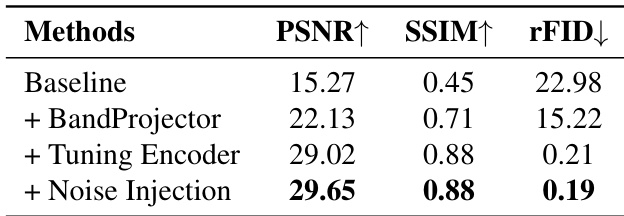
- 消融研究:频带投影器、编码器调优与噪声注入使PSNR从15.27逐步提升至29.65。在2-10个频带范围内性能稳定(PSNR~29, rFID 0.19, 语义准确率83.0%),证明对频带粒度的鲁棒性。
作者使用DINOv2编码器的UAE在统一分词器中取得最先进重建质量,在ImageNet-1K和MS-COCO 2017上显著超越RAE的PSNR、SSIM和rFID指标。升级至DINOv2-L后,UAE获得最佳整体保真度与感知质量,表明频谱感知分解能有效保留语义结构与视觉细节。结果表明UAE在相同编码器配置下,性能可与Flux-VAE、SD3-VAE等强生成自编码器竞争。
作者通过向基线模型逐步添加组件提升重建质量:频带投影器改善结构恢复,编码器调优提升保真度并降低rFID,噪声注入进一步优化感知质量,最终达到PSNR 29.65、SSIM 0.88和rFID 0.19。结果表明频谱分解、语义对齐与噪声正则化共同实现高保真重建,同时保留语义结构。
作者在256×256分辨率ImageNet上评估UAE的类别条件图像生成能力,与最新扩散模型及自回归模型对比。UAE取得1.68 gFID和301.6 IS,生成质量匹配或超越UniFlow、RAE等基线,同时保持竞争力的精度与召回率,证明其频谱潜在空间能有效支持生成任务而不损害语义连贯性。
作者通过ImageNet-1K上线性探针评估语义判别能力,UAE使用ViT-B骨干网取得83.0% top-1准确率。该结果与RAE持平,并超越MAE、MAGE、UniFlow等更大ViT-L模型,表明UAE在较小规模下仍保持强语义对齐能力。
作者使用DINOv2衍生的不同表征进行ImageNet-1K线性探针测试。结果表明:仅使用最低频带(Band₀)取得略高的top-1准确率(83.3%),优于原始DINOv2特征(83.0%)或多频带拼接表示(83.0%),证明低频分量保留主导的全局语义结构。
