Command Palette
Search for a command to run...
GenEnv:LLM Agent 与环境模拟器之间的难度对齐协同进化
GenEnv:LLM Agent 与环境模拟器之间的难度对齐协同进化
Jiacheng Guo Ling Yang Peter Chen Qixin Xiao Yinjie Wang Xinzhe Juan Jiahao Qiu Ke Shen Mengdi Wang
摘要
训练具备能力的大语言模型(LLM)智能体,其核心瓶颈在于真实世界交互数据成本高昂且静态不变。为此,我们提出 GenEnv 框架,构建了一个智能体与可扩展、生成式环境模拟器之间的难度对齐协同进化博弈机制。与传统方法在静态数据集上迭代模型不同,GenEnv 实现了“数据动态演化”:环境模拟器充当动态课程策略,持续生成针对智能体“最近发展区”(zone of proximal development)量身定制的任务。该过程由一种简单而高效的 α-课程奖励(α-Curriculum Reward)引导,确保任务难度与智能体当前能力保持同步。我们在五个基准任务上评估了 GenEnv,涵盖 API-Bank、ALFWorld、BFCL、Bamboogle 和 TravelPlanner。在这些任务中,GenEnv 相较于 7B 规模的基线模型,性能提升最高达 +40.3%,并达到或超越更大模型的平均水平。与基于 Gemini 2.5 Pro 的离线数据增强方法相比,GenEnv 在仅使用其 1/3.3 数据量的情况下,仍实现了更优的性能表现。通过从静态监督转向自适应模拟,GenEnv 为智能体能力的高效扩展提供了一条数据利用率更高的可行路径。
一句话总结
普林斯顿大学、字节跳动Seed等研究团队提出GENEnv框架,通过建立基于α课程奖励的难度对齐协同进化博弈,使LLM智能体与环境模拟器动态生成匹配智能体能力的任务,在API-Bank和ALFWorld等五项智能体基准测试中以3.3倍少于Gemini增强的数据量实现最高40.3%的性能提升,显著超越7B基线模型。
核心贡献
- 针对训练LLM智能体时高成本静态真实交互数据的瓶颈,提出GENEnv框架,在智能体与生成式环境模拟器间建立难度对齐的协同进化博弈。
- 提出数据演化范式:模拟器通过α课程奖励动态生成适配智能体能力的任务,用自适应模拟替代静态数据集,实现能力持续进阶。
- 在五项基准测试(API-Bank、ALFWorld、BFCL、Bamboogle、TravelPlanner)中实现显著提升,较7B基线模型最高提升+40.3%,在仅使用Gemini 2.5 Pro增强数据3.3倍的情况下匹配大模型性能。
引言
训练强大LLM智能体的关键瓶颈在于昂贵的静态交互数据,这限制了超越专家演示的探索能力,阻碍了真实应用场景中的稳健泛化。依赖固定数据集或离线合成数据增强的先前方法无法根据智能体演进的技能水平调整任务难度,导致学习效率低下和能力停滞。作者提出GenEnv,通过建立难度对齐的协同进化循环,使生成式环境模拟器基于α课程奖励动态调整任务至智能体的近端发展区,从而通过自适应模拟而非静态监督实现高效能力扩展。
数据集
作者通过智能体-环境交互维护两个动态演化的数据集:
-
数据集构成与来源:
训练数据源自在线交互:环境策略(πenv)生成任务批次(Tt),每批包含多个任务实例(含提示词、评估规范及可选标准动作)。智能体随后生成交互轨迹(rollouts)存入两个池:- 智能体训练池(Dtrain):收集有效交互轨迹(格式正确、可评估的轨迹,含最终动作与奖励)。
- 环境SFT池(Denv):存储环境生成的(条件上下文 → 任务实例)对,按环境奖励加权(如 ∝exp(λRenv))。
-
关键子集细节:
- GenEnv-Random:使用Qwen2.5-7B-Instruct动态生成每提示词每轮次4个任务变体,无模型更新(固定权重)。
- GenEnv-Static:为544个基础训练样本预生成5个变体,构建固定3,264样本数据集。
- Gemini-Offline:Gemini 2.5 Pro生成过滤变体——"Gemini-2x"含957样本(1.76×基础),"Gemini-4x"含1,777样本(3.27×)。
-
训练中的数据使用:
Dtrain由基础数据、历史轨迹和新策略轨迹动态混合构成,智能体从中采样持续学习。Denv通过奖励加权回归(RWR)训练πenv,将任务难度调整至目标成功率α。两池每轮更新,闭合数据演化循环。 -
处理细节:
轨迹需有效(如工具调用解析正确、输出匹配模式)方可进入Dtrain。Denv按exp(λRenv)(λ=1.0)加权记录环境生成。无裁剪操作;成功统计等元数据为πenv的条件上下文提供信息。
方法
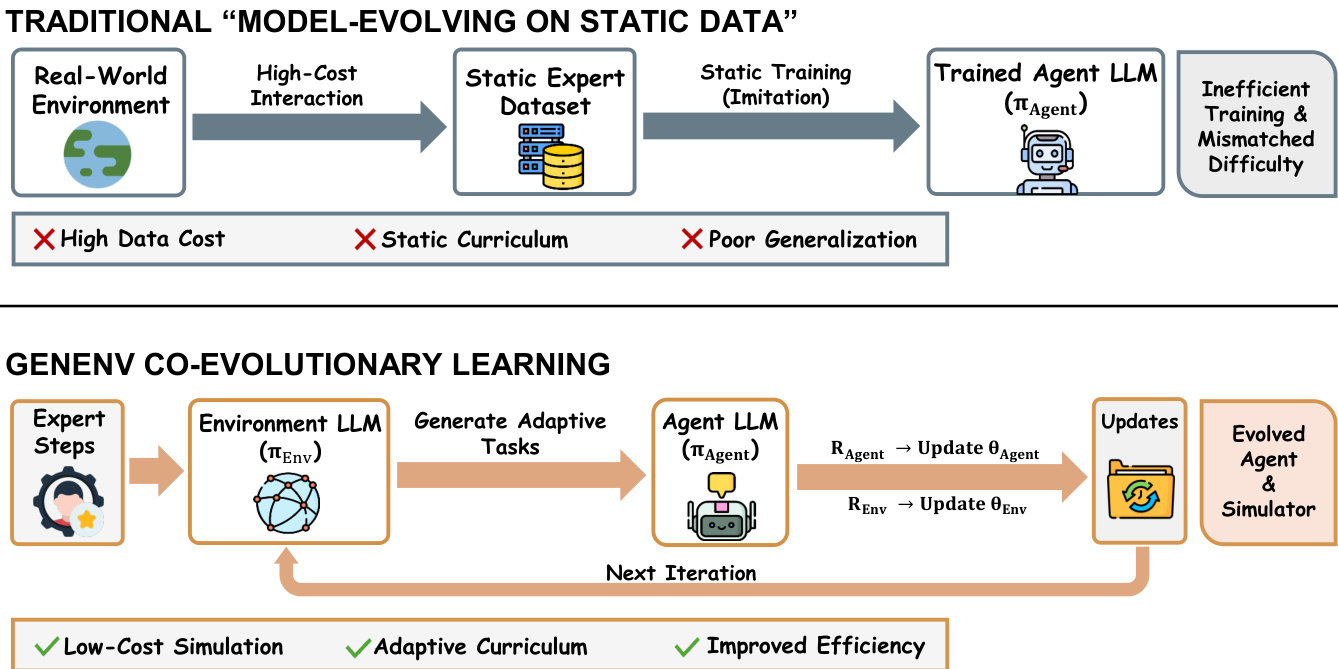
作者提出名为GENEnv的协同进化框架,将智能体训练重构为智能体策略πagent与环境策略πenv间的双人课程博弈。不同于依赖静态专家数据集的传统方法,GENEnv通过基于LLM的环境模拟器动态生成训练数据,实现与智能体能力同步演进的自适应课程学习。此范式转变用低成本可扩展的模拟替代昂贵的真实世界交互,如下图所示(传统静态训练与GENEnv协同进化循环对比)。
训练过程每轮分三阶段进行:阶段1中,环境LLM基于智能体历史表现生成任务批次,智能体LLM尝试执行并产生轨迹;阶段2评估轨迹计算两类奖励:智能体奖励Ragent(通过结构化动作的精确匹配或自由输出的软相似度衡量任务成功)与环境奖励Renv(评估难度对齐)。环境奖励定义为Renv(p^)=exp(−β(p^−α)2),其中p^为批次经验成功率,α为目标成功率(通常0.5),确保任务难度适中。难度过滤器排除∣p^−α∣>kmin的批次,防止过拟合瞬时性能峰值。
阶段3同步更新双策略:智能体策略通过组相对策略优化(GRPO)最大化E[Ragent];环境策略基于加权监督微调集用奖励加权回归(RWR)微调,权重正比于exp(λRenv(p^))。为保障稳定性,环境更新通过KL散度惩罚(相对于初始模拟器)和最大KL阈值约束。有效智能体轨迹与加权环境生成被聚合至对应训练池用于后续迭代,闭合协同进化循环。
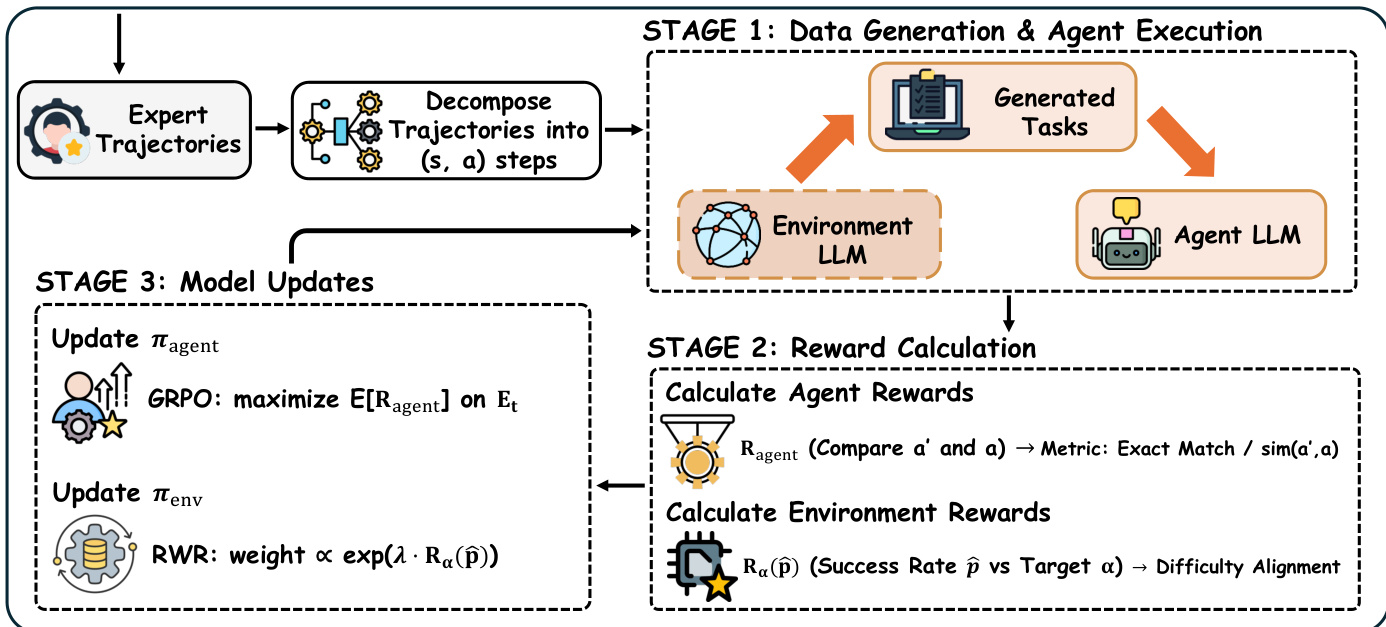
该架构使环境模拟器学会生成针对智能体"近端发展区"的任务,在保持数据效率的同时最大化学习信号。理论分析证实:中等难度任务(成功率p(τ)=0.5)为策略更新提供最强梯度信号,α课程奖励为任务难度排序提供统计一致信号,确保模拟器随时间收敛至生成最优挑战性任务。
实验
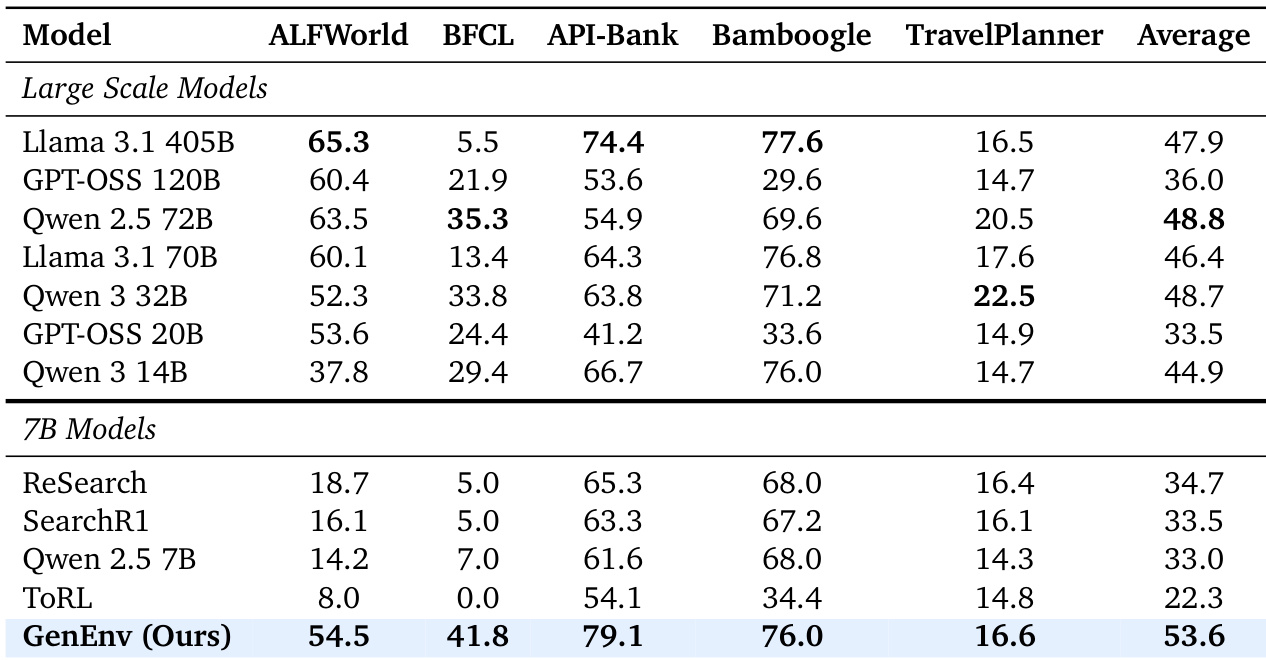
- GenEnv(7B)在五项基准测试中全面超越7B基线模型,ALFWORLD达54.5%(基线14.2%),API-Bank达79.1%,平均分53.6超越多个72B/405B模型的平均表现。
- 协同进化过程验证了涌现式课程学习:训练中任务复杂度(以响应长度衡量)提升49%而成功率保持稳定,确认难度对齐演进。
- GenEnv展现卓越数据效率:仅用动态生成的策略内数据,在验证得分上以2.0%优势超越使用3.3倍数据的Gemini-Offline,并因奖励引导模拟比GenEnv-Random高12.3%。
- α课程奖励成功校准任务难度,智能体成功率收敛至α=0.5的目标区间[0.4, 0.6],确保训练全程任务处于近端发展区。
作者使用GenEnv(7B模型与协同演化环境模拟器训练)在五项多样化基准测试中超越其他7B基线模型,并匹配或超越多个高达405B参数大模型的平均表现。结果表明:GenEnv在ALFWorld和API-Bank分别实现54.5%和79.1%,显著优于静态数据基线,证明难度对齐的数据生成可媲美甚至超越单纯扩大模型规模。该框架的涌现课程与稳定训练动力学在无奖励崩溃或手动难度调度的情况下实现此性能。