Command Palette
Search for a command to run...
LoGoPlanner:基于定位的度量感知视觉几何导航策略
LoGoPlanner:基于定位的度量感知视觉几何导航策略
Jiaqi Peng Wenzhe Cai Yuqiang Yang Tai Wang Yuan Shen Jiangmiao Pang
摘要
在非结构化环境中进行轨迹规划是移动机器人的一项基础且极具挑战性的能力。传统的模块化处理流程在感知、定位、建图与规划等模块之间存在延迟问题,并易产生级联误差。近年来,端到端学习方法通过将原始视觉观测直接映射为控制信号或轨迹,有望在开放世界场景中实现更高的性能与效率。然而,大多数现有端到端方法仍依赖独立的定位模块,而这些模块需要精确的传感器外参标定以实现自我状态估计,从而限制了其在不同机器人本体(embodiments)和环境间的泛化能力。为此,我们提出LoGoPlanner——一种基于定位引导的端到端导航框架,通过以下三方面有效解决了上述局限:(1)对长时程视觉-几何主干网络进行微调,使其预测结果具备绝对度量尺度,从而实现隐式状态估计,提升定位精度;(2)利用历史观测重建周围场景的几何结构,提供密集且细粒度的环境感知信息,增强障碍物避让的可靠性;(3)将策略网络的输入条件依赖于前述辅助任务所构建的隐式几何先验,从而有效抑制误差传播。我们在仿真与真实世界环境中对LoGoPlanner进行了评估,结果表明,其全端到端的设计显著降低了累积误差,而具备度量感知的几何记忆机制进一步提升了路径规划的一致性与避障能力。相比基于理想定位的基线方法,LoGoPlanner在性能上提升超过27.3%,并在不同机器人本体与多种环境之间展现出优异的泛化能力。相关代码与模型已公开发布于项目主页:https://steinate.github.io/logoplanner.github.io/。
一句话总结
Peng 等人提出了 LoGoPlanner,一种完全端到端的导航框架,通过隐式状态估计和度量感知的几何重建消除了对外部定位的依赖。该框架通过深度导出的尺度先验微调长时域视觉几何骨干网络,并以隐式几何特征为条件生成基于扩散的轨迹,在无需外部定位的情况下实现了比真值定位基线高 27.3% 的性能,同时支持非结构化环境中的跨具身化稳健导航。
核心贡献
- LoGoPlanner 解决了现有端到端导航方法仍需依赖精确传感器校准的独立定位模块的局限性,通过微调长时域视觉几何骨干网络实现隐式状态估计,使预测基于绝对度量尺度。这消除了对外部定位的依赖,同时提供精确的自状态感知。
- 该框架通过历史视觉观测重建稠密场景几何结构,为避障提供细粒度环境上下文,克服了先前单帧方法中常见的部分或尺度模糊的几何重建问题,从而在遮挡区域和后视区域实现稳健的空间推理。
- 通过将导航策略直接建立在该隐式度量感知几何结构上,LoGoPlanner 降低了轨迹规划中的误差传播,在仿真和真实世界评估中均比真值定位基线提升超过 27.3%,同时在不同机器人平台和环境中展现出强大的泛化能力。
引言
在非结构化环境中导航的移动机器人需要稳健的轨迹规划能力,但传统模块化流程在感知、定位和规划阶段存在延迟和级联误差问题。虽然端到端学习方法通过将原始视觉直接映射为控制信号提升了效率,但仍严重依赖需要精确传感器校准的外部定位模块,限制了跨机器人和环境的泛化能力。单目视觉里程计方法进一步受困于固有的尺度模糊性和漂移问题,常需额外传感器或场景先验,降低了实际应用性。作者通过引入 LoGoPlanner 克服了这些局限——该端到端框架将度量尺度的视觉几何估计直接集成到导航中,利用微调的视觉几何骨干网络隐式估计绝对尺度和状态,通过历史观测重建场景几何结构实现避障,并以该自举几何结构为条件最小化误差传播,无需外部定位输入。
方法
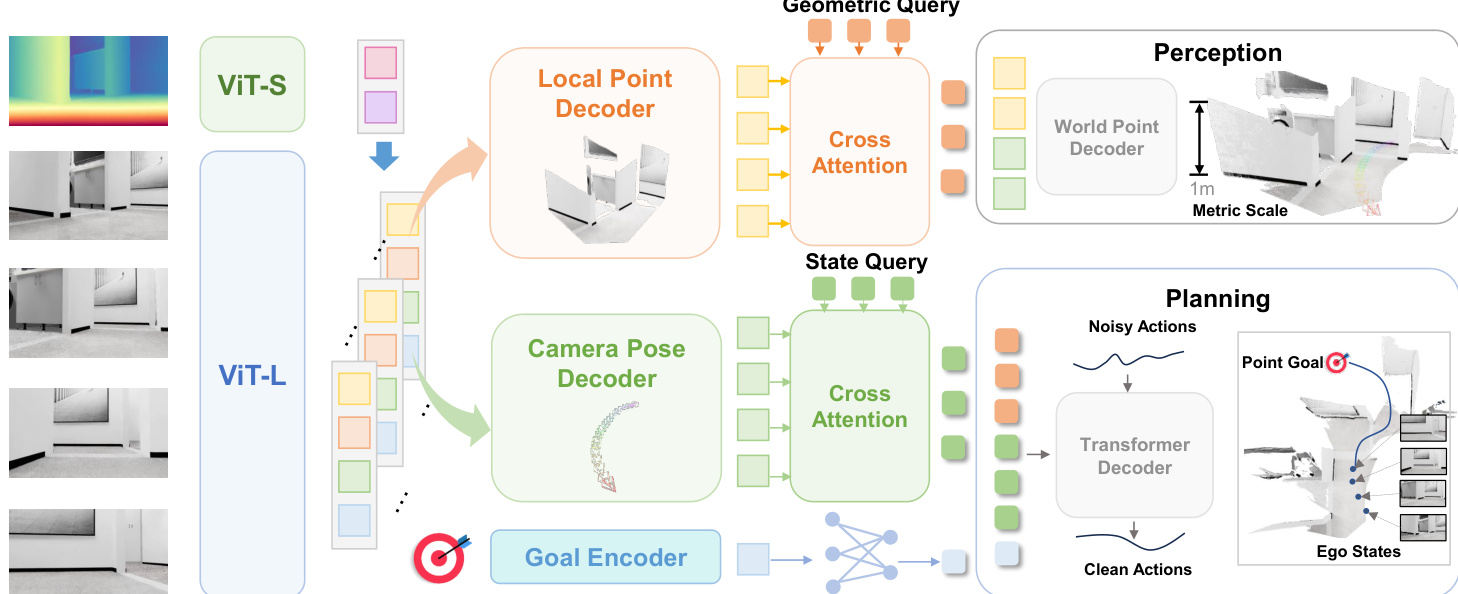
作者采用统一的端到端架构——LoGoPlanner,联合学习度量感知的感知、隐式定位和轨迹生成,无需依赖外部模块。该框架基于预训练的视频几何骨干网络构建,通过深度导出的尺度先验增强以实现度量尺度的场景重建。系统核心处理因果序列的 RGB-D 观测数据,提取紧凑的、世界对齐的点嵌入,同时编码细粒度几何结构和长期自运动信息。
参考框架图示(整体流程示意图)。架构以视觉 Transformer (ViT-L) 开始,将序列 RGB 帧处理为块标记(patch tokens)。这些标记与通过轻量级 ViT-S 编码器从深度图导出的几何标记在块级别融合。融合后的标记经由增强 Rotary Position Embedding (RoPE) 的 Transformer 解码器处理,生成度量感知的逐帧特征:
timetric=Attention(RoPE((tiI,tiD),pos))其中 pos∈RK×2 编码 2D 空间坐标以保持位置关系。为提升重建保真度,通过两个任务专用头施加辅助监督:局部点头(local point head)和相机姿态头(camera pose head)。局部点头将度量标记映射为潜在特征 hip,再解码为相机坐标系中的规范 3D 点:
hip=ϕp(timetric),Pilocal=fp(hip)监督通过针孔模型实现:
pcam,i(u,v)=Di(u,v)K−1[uv1]⊤同时,相机姿态头将相同度量标记映射为特征 hic,再解码为相机到世界的变换 Tc,i,该变换相对于上一时间步的底盘坐标系定义以确保规划一致性。
为在不显式校准的情况下连接感知与控制,作者解耦相机与底盘姿态估计。底盘姿态 Tb,i 和相对目标 gi 由 hic 预测:
Tb,i=fb(hic)gi=fq(hic,g)外参变换 Text(捕获相机高度和俯仰角)通过具有不同相机配置的训练数据隐式学习,实现跨具身化泛化。
系统采用受 UniAD 启发的基于查询设计,而非传播显式姿态或点云。状态查询 QS 和几何查询 QG 通过交叉注意力提取隐式表示:
QS=CrossAttn(Qs,hc)QG=CrossAttn(Qd,hp)这些查询与目标嵌入融合形成规划上下文查询 QP,作为扩散策略头的条件。策略通过迭代去噪含噪动作序列生成轨迹片段 at=(Δxt,Δyt,Δθt):
αk−1=α(αk−γϵθ(QP,αk,k)+N(0,σ2I))其中 ϵθ 为噪声预测网络,α,γ 为扩散调度参数。这种迭代优化确保生成无碰撞、可行的轨迹,同时避免显式中间表示带来的误差累积。
实验
- 在 40 个未见 InternScenes 环境的仿真测试:LoGoPlanner 在 Home Success Rate 上比 ViPlanner 提升 27.3 个百分点,在 Success weighted by Path Length 上提升 21.3%,验证了无需外部定位的稳健无碰撞导航能力。
- TurtleBot、Unitree Go2 和 G1 平台的真实世界测试:在杂乱家居场景中,Unitree Go2 达到 90.0% 成功率和 82.0% SPL,证明了无需 SLAM 或视觉里程计的跨平台泛化能力.
- 消融研究:证实点云监督对避障至关重要,尺度注入的几何骨干网络可降低导航误差并提升规划精度。
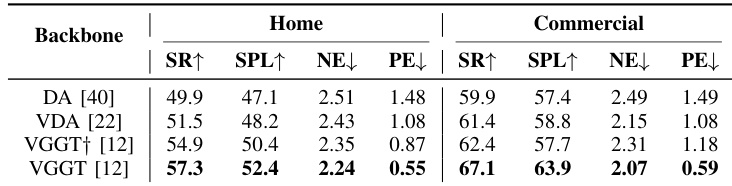
作者在家居和商业场景中评估导航性能,以成功率(SR)和路径长度加权成功率(SPL)为指标。LoGoPlanner 通过隐式状态估计实现无外部定位导航,性能超越所有基线,在家居场景达到 57.3 SR 和 52.4 SPL,在商业场景达到 67.1 SR 和 63.9 SPL。结果表明其在家居场景的 SR 和 SPL 分别比 ViPlanner 提升 27.3 个百分点和 21.3%,凸显了自定位与几何感知规划集成的优势。
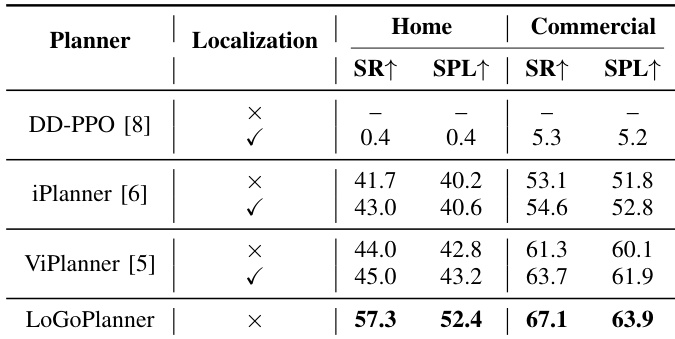
作者在三个机器人平台和环境类型中评估 LoGoPlanner 与 iPlanner、ViPlanner 的性能。LoGoPlanner 在所有场景中均取得最高成功率:办公环境 TurtleBot 达 85%,家居场景 Unitree Go2 达 70%,工业场景 Unitree G1 达 50%,显著优于两个基线。结果证明 LoGoPlanner 无需外部定位即可运行,并能有效应对平台引起的相机抖动和复杂障碍物配置。
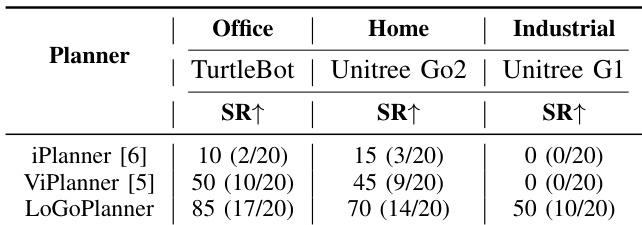
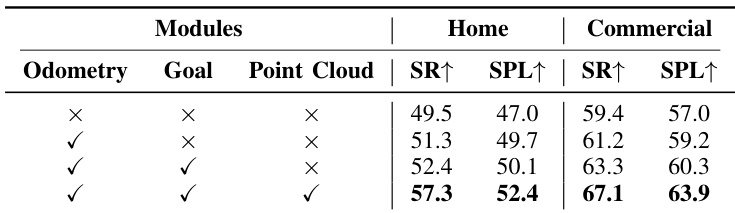
作者通过移除辅助任务(里程计、目标、点云)评估模型变体,在家居和商业场景中以成功率(SR)和路径长度加权成功率(SPL)衡量性能。结果显示三模块联合使用性能最优,家居场景 SR 达 57.3,商业场景达 67.1,表明联合监督提升了轨迹一致性和空间感知能力。移除任一模块均导致性能下降,证实各模块对稳健导航均有实质性贡献。
作者评估不同视频几何骨干网络的导航性能,发现注入尺度的 VGGT 在家居和商业场景中均取得最高成功率和 SPL,同时降低了导航和规划误差。结果表明,相比单帧或未标定多帧模型,引入度量尺度监督可提升轨迹精度和规划一致性。