Command Palette
Search for a command to run...
QuCo-RAG:基于预训练语料库量化不确定性以实现动态检索增强生成
QuCo-RAG:基于预训练语料库量化不确定性以实现动态检索增强生成
Dehai Min Kailin Zhang Tongtong Wu Lu Cheng
摘要
动态检索增强生成(Dynamic Retrieval-Augmented Generation, RAG)通过在生成过程中自适应地决定何时进行检索,以缓解大语言模型(LLM)中的幻觉问题。然而,现有方法主要依赖模型内部信号(如 logits、熵值)来判断是否需要检索,这些信号本质上不可靠,因为大语言模型通常存在校准不足的问题,往往在错误输出上表现出过高的置信度。为此,我们提出 QuCo-RAG,该方法摒弃主观置信度,转而采用基于预训练数据的客观统计量进行不确定性量化。我们的方法包含两个阶段:(1)在生成前,识别低频实体以揭示长尾知识缺口;(2)在生成过程中,验证实体在预训练语料库中的共现情况,其中零共现通常预示着幻觉风险。两个阶段均利用 Infini-gram 技术,在四万亿 token 规模的数据上实现毫秒级查询响应,当检测到高不确定性时触发检索。在多跳问答(multi-hop QA)基准上的实验表明,使用 OLMo-2 模型时,QuCo-RAG 相较于当前最优基线方法,准确率(EM)提升 5 至 12 个百分点;且该方法可有效迁移至未公开预训练数据的模型(如 Llama、Qwen、GPT),在这些模型上 EM 提升最高达 14 个百分点。在生物医学问答任务上的领域泛化实验进一步验证了该范式的稳健性。上述结果确立了基于语料库验证的动态 RAG 作为一种原理清晰、实际适用且模型无关的新范式。相关代码已开源,访问地址为:https://github.com/ZhishanQ/QuCo-RAG。
一句话总结
来自伊利诺伊大学芝加哥分校、纽约大学和蒙纳士大学的研究人员提出QuCo-RAG,这是一种动态RAG框架,通过Infini-gram利用预训练语料库统计信息替代不可靠的模型内部置信信号,实现毫秒级实体验证。该方法通过识别低频知识缺口并验证实体共现,在OLMo-2、Llama和生物医学问答基准测试中实现了5–14点的精确匹配得分提升。
主要贡献
- 现有动态RAG方法依赖logits或熵等不可靠的模型内部信号触发检索,但由于大语言模型校准不良且常对错误输出表现出高置信度,导致该方法失效。
- QuCo-RAG用客观的预训练语料库统计信息替代主观置信度指标,采用两阶段方法:生成前识别低频实体,生成期间通过Infini-gram对4万亿token进行毫秒级查询验证实体共现。
- 在多跳问答基准测试中,QuCo-RAG在OLMo-2模型上比最先进的基线方法提升5–12点精确匹配得分,并可迁移至预训练数据未公开的模型(Llama、Qwen、GPT),精确匹配得分最高提升14点,同时在生物医学问答中表现出鲁棒性。
引言
动态检索增强生成(RAG)系统旨在通过在文本生成过程中自适应检索相关知识来减少大语言模型(LLM)的幻觉。然而,现有方法严重依赖token概率或熵等模型内部信号来决定是否需要检索。这些信号本质上不可靠,因为LLM常表现出校准不良特性——对错误输出保持高置信度,从而削弱幻觉检测能力。
作者利用预训练语料库统计信息替代主观模型置信度,以客观量化不确定性。其QuCo-RAG框架分两阶段运行:首先在预生成阶段识别低频实体以标记长尾知识缺口;其次在生成阶段验证预训练数据中的实体实时共现,缺失共现即表明高幻觉风险。两个阶段均使用Infini-gram对万亿级token进行毫秒级查询以触发检索。这种基于语料库的方法在多跳和生物医学问答基准测试中实现5–14点精确匹配得分提升,适用于包括预训练数据未公开模型(Llama、Qwen、GPT)在内的多种LLM,并建立了可靠的模型无关不确定性感知生成范式。
数据集
作者在研究中使用两个主要数据组件:
- OLMo-2预训练语料库:作为核心数据源,包含约4万亿token,来源多样但未公开。该透明语料库支持精确的实体频率与共现分析,与训练代码和配方一同公开,确保可复现性。
- 三元组提取器训练数据:精选的句子-三元组配对数据集,其中:
- 每个输入为陈述句;若存在事实内容,输出为*(头实体, 关系, 尾实体)*格式的知识三元组。
- 尾实体优先选择命名实体(人物、地点、组织、日期)而非通用描述符以提高可验证性。
- 非事实陈述(如以"Thus"开头的推理结论)输出为空。
- 问题生成部分三元组(答案未知),非事实内容返回空三元组。
用于模型评估时:
- 直接使用OLMo-2语料库在OLMo-2-Instruct变体(7B、13B、32B)上训练和验证方法。
- 将OLMo-2语料库作为预训练数据未公开模型(Llama-3-8B-Instruct、Qwen2.5-32B-Instruct、GPT-4.1、GPT-5-chat)的代理,利用已知的网络规模语料库重叠。
- 不进行显式裁剪,而是通过三元组提取规则构建元数据,过滤和结构化事实知识以支持检索。
- 通过三元组提取器处理所有数据以分离可验证事实,确保仅实体丰富且经共现验证的知识用于检索。
方法
作者采用基于语料库的动态检索框架,将不确定性量化与内部模型状态解耦,转而锚定于预训练语料库统计信息。系统分两个主要阶段运行:预生成知识评估和运行时声明验证,均由基于词频和共现信号的离散二元触发器控制。
在预生成阶段,系统在生成任何token前执行初始不确定性检查。轻量级实体提取器从输入问题中识别关键实体,并通过高吞吐索引引擎查询其在预训练语料库中的频率。若平均实体频率低于预定义阈值 τentity,系统将使用原始问题作为查询触发检索。检索到的文档将前置至上下文窗口以指导后续生成。该机制针对输入不确定性——即问题包含模型在预训练中可能未接触过的稀有或长尾实体的情况。
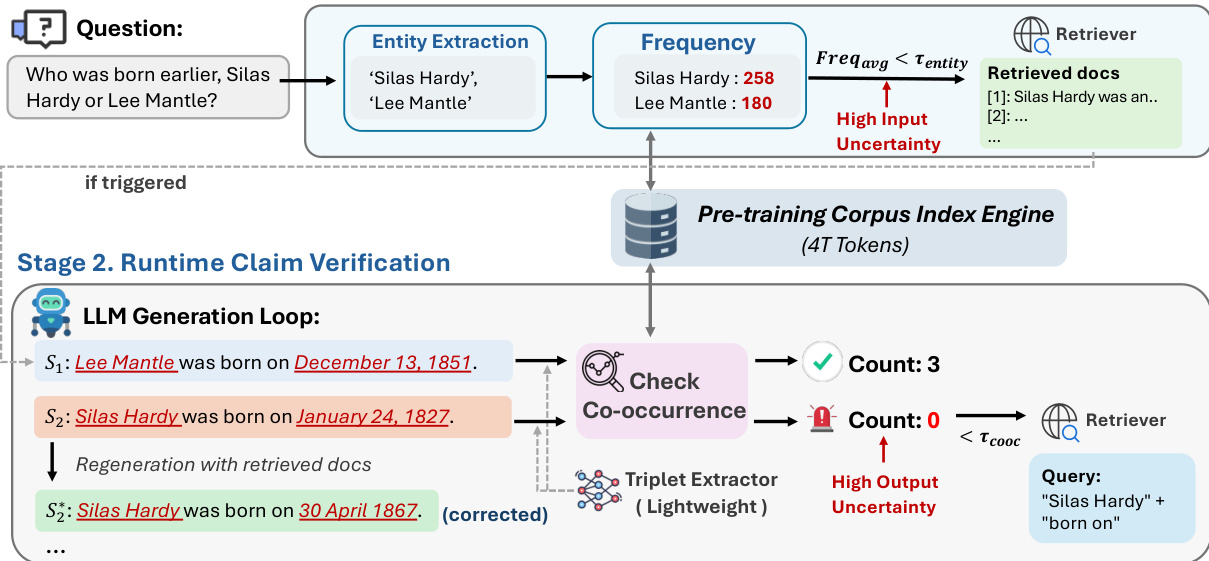
在生成阶段,系统进入运行时声明验证循环。每生成一个句子 si 后,轻量级三元组提取器将句子解析为主语-关系-宾语三元组 (h,r,t)。对于每个三元组,系统计算头尾实体在预训练语料库固定窗口内的共现计数,定义为:
cooc(h,t;P)=∣{w∈P∣h∈w∧t∈w}∣由于关系谓词的词汇可变性,该共现指标优于完整三元组匹配。若任何提取的三元组共现计数低于 τcooc=1,系统将标记该句子为高不确定性并触发检索。检索查询通过拼接头实体和关系构建(q=h⊕r),模型使用新检索的上下文重新生成该句子。该机制针对输出不确定性——即缺乏语料库证据支持因而可能为幻觉的声明。
整个流水线注重效率实现。作者采用基于后缀数组的索引引擎Infini-gram,实现对万亿级token语料库的毫秒级查询。三元组提取器是经过4万条上下文示例微调的0.5B参数蒸馏模型,在低开销下保持提取保真度。触发器的二元特性——基于离散语料库统计而非连续置信度分数——消除了任意阈值校准需求,并提供语义明确的决策边界.
实验
- 在OLMo-2模型(7B–32B)的2WikiMultihopQA和HotpotQA上,QuCo-RAG比最先进基线方法提升5–12点精确匹配(EM)得分,例如在OLMo-2-7B上2WikiMultihopQA提升+7.4 EM,OLMo-2-13B提升+12.0 EM.
- 证明跨模型迁移能力,在2WikiMultihopQA上使用OLMo-2语料库作为代理,Qwen2.5-32B提升+14.1 EM,GPT-5-chat提升+8.7 EM.
- 在PubMedQA验证领域泛化能力,以最低开销(0.93次检索/问题)达到66.4%准确率,优于内部信号方法(过度检索或无法提升).
- 保持高效性,平均每问题仅1.70次检索,且token/LLM调用量低于动态RAG基线,同时最大化EM得分.
QuCo-RAG在PubMedQA上达到最高准确率(66.4%),比最佳基线高11.2点,每问题仅触发0.93次检索,平均消耗54.9个token. 这证明其通过语料库统计精确检测幻觉风险的能力无需领域特定调优,而内部信号方法要么过度检索,要么无法超越无检索基线.
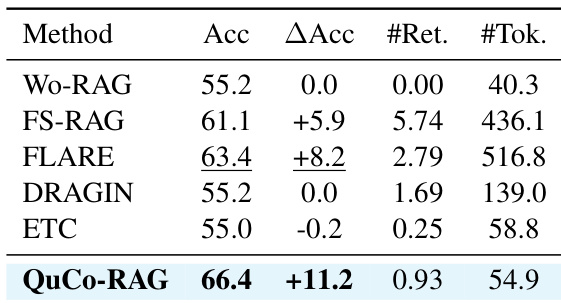
结果表明QuCo-RAG在实体频率各分段均持续优于所有基线,尤其在低频实体上增益最大(内部信号方法无法有效触发检索). 在整体测试集上,QuCo-RAG达到32.7 EM,比最佳基线高9.2点,同时保持适中检索频率. 该方法在高频实体上表现更佳,反映其依赖语料库共现统计可靠检测并修正幻觉.
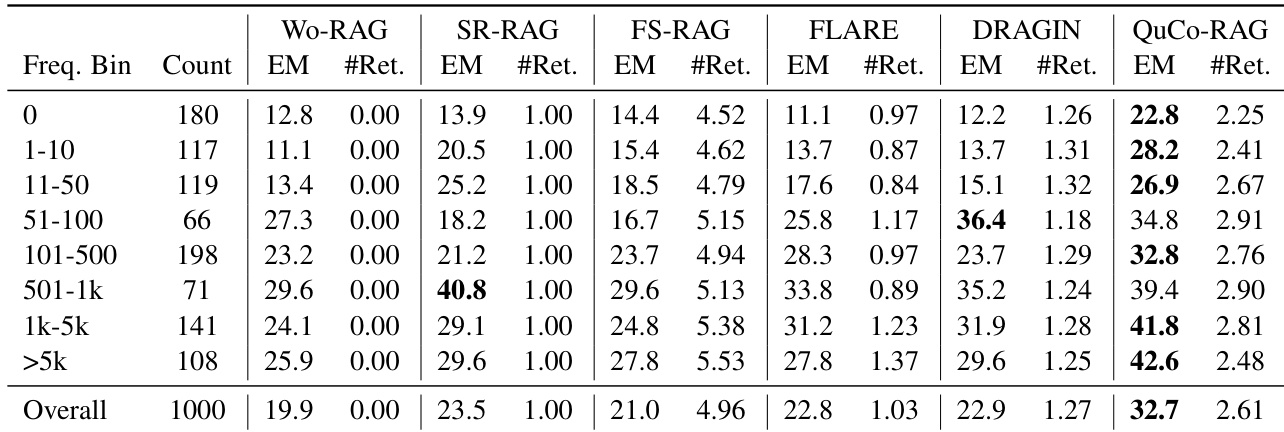
QuCo-RAG在OLMo-2各尺寸模型和两个多跳问答基准测试中持续优于所有基线方法,在最强基线上实现5.3至12.0 EM点的增益. 基于语料库的不确定性量化证明比内部信号方法更可靠——后者表现不稳定且常无法对幻觉内容触发检索. 效率指标证实QuCo-RAG以适中token使用量和检索频率提供最佳性能.
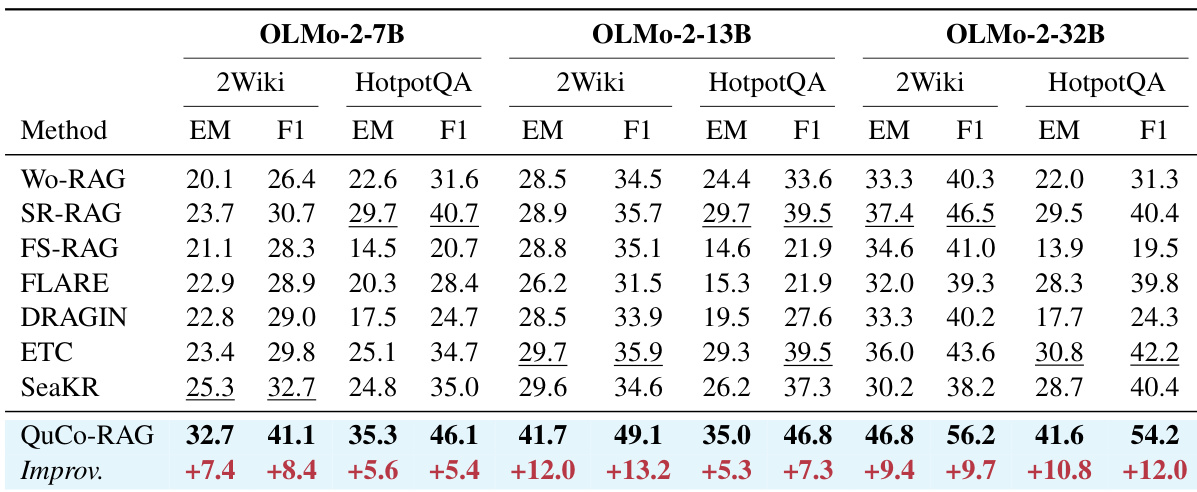
作者通过消融实验评估QuCo-RAG在OLMo-2-7B上的2WikiMultihopQA两阶段检测机制. 移除运行时声明验证阶段导致更大性能下降(5.1 EM),超过移除预生成知识评估阶段(2.5 EM),表明共现验证是更关键组件. 按仅保留初始检查,QuCo-RAG仍以更少检索次数比SR-RAG高3.9 EM.
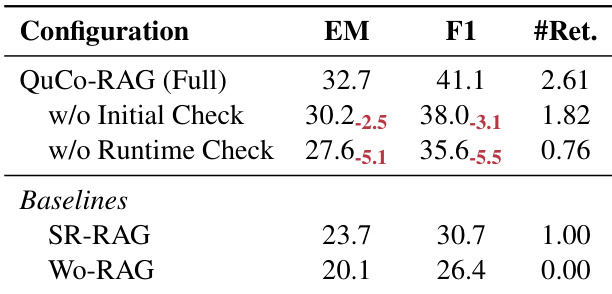
QuCo-RAG在OLMo-2各尺寸模型的2WikiMultihopQA和HotpotQA上持续优于所有基线方法,在保持适中token使用量和检索频率的同时实现更高精确匹配得分. 该方法比FS-RAG和SeaKR等动态基线触发更少检索,却提供更优准确率,证明基于语料库的不确定性检测效率. 效率指标显示QuCo-RAG比多数动态RAG方法使用更少LLM调用和token,尤其在更大规模模型上,且不牺牲性能.