Command Palette
Search for a command to run...
LLM能否评估学生困难?基于能力模拟的师生AI难度对齐在题目难度预测中的应用
LLM能否评估学生困难?基于能力模拟的师生AI难度对齐在题目难度预测中的应用
Ming Li Han Chen Yunze Xiao Jian Chen Hong Jiao Tianyi Zhou
摘要
准确估计题目(问题或任务)的难度对于教育评估至关重要,但这一过程常面临“冷启动”问题。尽管大型语言模型展现出超越人类的问题求解能力,但其是否能够感知人类学习者在认知上的困难,仍是悬而未决的问题。在本研究中,我们对超过20种模型在医学知识、数学推理等多个领域开展了大规模实证分析,系统考察了人类与人工智能在难度认知上的对齐程度。研究发现,存在一种系统性偏差:单纯扩大模型规模并不能可靠提升难度估计的准确性;相反,模型并非趋向于与人类认知对齐,而是逐渐趋同于一种共享的“机器共识”。我们观察到,模型性能越高,反而越难以准确估计难度——即使被明确提示以特定能力水平进行模拟,模型仍难以有效再现学习者的认知局限。此外,我们还发现模型普遍存在深刻的自我反思缺失,无法准确预测自身的局限性。这些结果表明,通用的问题求解能力并不等同于对人类认知困境的理解,凸显了当前模型在自动化难度预测应用中的根本挑战。
一句话总结
马里兰大学、卡内基梅隆大学和布法罗大学的研究人员对20多个大型语言模型进行了人类-人工智能难度对齐的实证分析,揭示出系统性错位现象:扩大模型规模无法捕捉人类认知困难;相反,模型会趋同于机器共识,而高性能反而阻碍了对难度的准确估计,因为它们既无法模拟学生局限性也无法进行自我评估。尽管具备解题能力,这一发现挑战了其在自动化教育评估中的应用。
主要贡献
- 准确的项目难度估计对教育评估至关重要,但面临冷启动问题——新题目缺乏历史作答数据,需借助真实学生进行耗时费力的实地测试,才能在项目反应理论等框架内校准难度参数。
- 作者引入大规模人类-人工智能难度对齐实证分析,通过将模型同时视为预测学生困难的外部观察者和亲历困难的内部执行者,在四个教育领域评估20多个大语言模型,同时分析模型间共识、基于项目反应理论的能力-感知差距以及元认知对齐。
- 研究发现系统性错位现象:扩大模型规模无法提升人类难度感知;相反,模型趋同于共享的机器共识,高性能模型无法模拟学生局限性或预测自身错误。来自医学知识和数学推理等多领域的证据均支持这一结论。
引言
准确的项目难度估计对自适应测试和课程设计等教育应用至关重要,但传统方法需依赖真实学生的昂贵实地测试,导致新题目面临冷启动问题。先前基于监督学习的难度预测方法依赖历史作答数据,对未见题目无效;早期基于大语言模型的方法未能解决模型解题能力与其感知人类认知困难能力之间的根本性错位。作者通过双重视角严格评估现成大语言模型是否能估计难度:作为预测学生困难的外部观察者,以及模拟低水平推理的内部执行者。其贡献包括在20多个模型和四个教育领域扩展分析,并引入元认知对齐和能力水平模拟,以超越简单准确率指标来剖析能力-感知差距.
数据集
作者通过整理四个经真实学生实地测试获得真实难度值的数据集来研究人类-人工智能难度对齐,确保领域多样性并避免私有/混合来源的偏差。各子集关键细节如下:
- USMLE(医学知识):667道高风险医学考试题目,源自NBME/FSMB。难度采用连续转换p值[0, 1.3],经每题300多名医学生实地测试验证(Yaneva et al., 2024)。
- Cambridge(语言能力):793道剑桥英语阅读理解题,需长文本推理。难度采用重缩放项目反应理论b-参数[0, 100]作为真实值(Mullooly et al., 2023)。
- SAT阅读与写作(语言推理):1,338道标准化测试题,已过滤依赖图表的题目。难度采用离散类别(简单/中等/困难)。
- SAT数学(逻辑推理):1,385道代数/几何/数据分析题,同样过滤为纯文本处理。难度采用离散类别(简单/中等/困难)。
这些数据集仅作为评估基准(非训练数据),用于测试20多个大语言模型(包括GPT-4o、Llama3.1和推理专用模型)与真实学生表现的对齐程度。处理流程包括:
- 移除依赖图表的SAT题目以确保纯文本输入。
- 直接使用提供的难度指标(USMLE/Cambridge为连续值;SAT子集为离散值)。
- 除SAT过滤外无其他裁剪,所有子集保留原始实地测试难度标签。
方法
作者采用双模态评估框架,分析人类指定项目难度与大语言模型认知之间的对齐关系。该框架在两个独立角色中运行:作为估计难度的观察者(难度感知)和作为解题的执行者(解题能力)。每个角色均基于模拟不同学生能力水平的提示词,实现对模型行为在不同认知假设下变化的精细分析。
在观察者视角中,模型接收完整题目上下文xi、真实答案ai∗及可选能力提示词p。模型通过Genm(xi,ai∗,p)生成自然语言响应,再经函数ϕ(⋅)解析为归一化数值难度评分y^i,m。此设置将模型对难度的显式感知与其实际解题能力隔离。能力提示词设计用于模拟低、中、高学生能力水平,如下图所示为USMLE、剑桥英语、SAT阅读和SAT数学等领域的难度预测提示模板。



在执行者视角中,模型在零样本设置下运行且无法获取正确答案。它生成解a^i,m=ψ(Genm(xi,p)),其中ψ(⋅)从生成文本中提取最终答案。二元正确性vi,m计算为I(a^i,m=ai∗)。此模式评估模型在模拟能力水平条件下的内在解题能力。
为量化对齐程度,作者采用斯皮尔曼等级相关系数(ρ)作为统一指标。对于感知对齐(ρpred),计算模型预测难度评分y^i,m与人类真实值yi的相关性。对于能力对齐(ρirt),将模型集合M视为合成考生群体,拟合Rasch模型推导每题的经验机器难度βi。模型m答对题目i的概率建模为:
P(vi,m=1∣θm,βi)=1+exp(−(θm−βi))1其中θm表示模型潜在能力,βi表示题目内在机器难度,通过边际最大似然估计。最终能力对齐通过计算βi与yi的斯皮尔曼相关系数得出。
能力水平模拟通过四种配置实现:基线(无能力提示)、低、中、高。每种配置通过系统级提示词实例化以调节模型生成过程。例如在低能力设置中,模型被要求模拟"薄弱学生"(学科掌握有限);在高能力设置中,则扮演"优秀学生"角色。这些提示词针对不同领域和任务定制,如下图所示为问答任务的模板。



此结构化方法系统探究了大语言模型在不同认知假设下对教育题目的感知与表现,为人类-人工智能难度对齐提供全面视角。
实验
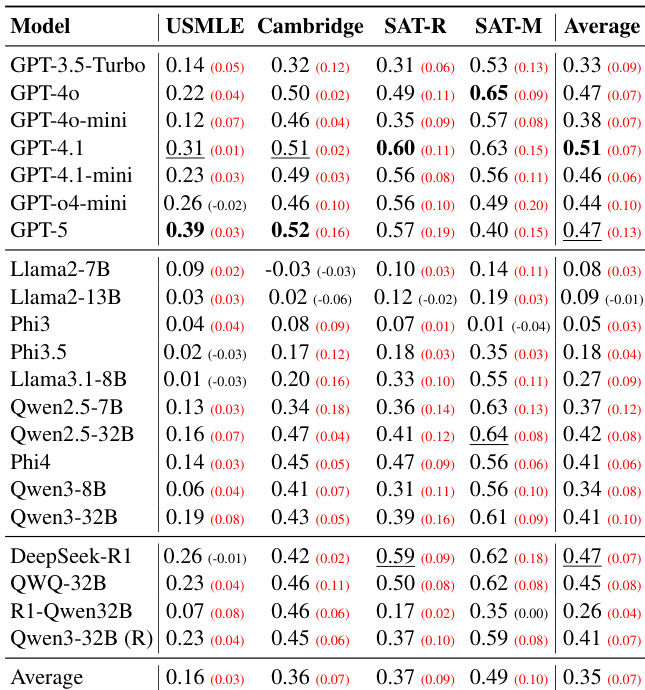
- 跨领域系统性错位验证:在医学(USMLE)和推理(SAT数学)领域,扩大模型规模反而恶化人类-人工智能难度对齐(斯皮尔曼ρ平均低于0.50,USMLE ρ≈0.13,SAT数学 ρ≈0.41),因模型趋同于机器共识而非人类感知。
- 模拟局限性确认:集成方法收益有限(如USMLE集成加入弱模型立即退化);能力提示效果不稳定——GPT-5仅通过角色平均将对齐度从基线0.34提升至ρ=0.47,并非真实模拟学生。
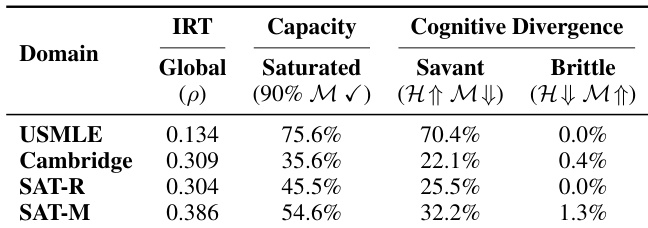
- 知识诅咒实证:项目反应理论分析表明,模型推导难度与人类相关性低于显式估计;高学者率(USMLE达70.4%)显示模型轻易解决多数人类难题;能力提示对准确率影响微弱(<1%变化)。
- 元认知盲区发现:AUROC分数接近0.55(随机水平)表明模型无法预测自身错误,即使GPT-5在剑桥数据集上仅达0.73,显示自我意识与解题能力脱节。
作者评估21个大语言模型在四个教育领域估计项目难度的能力,发现模型规模无法持续提升与人类难度感知的对齐度。结果显示中等至弱斯皮尔曼相关性,GPT-5取得最高平均分0.67;领域敏感性显著——SAT数学对齐最强而USMLE最弱。模型呈现系统性错位,趋同于共享机器共识而非反映人类认知困难。
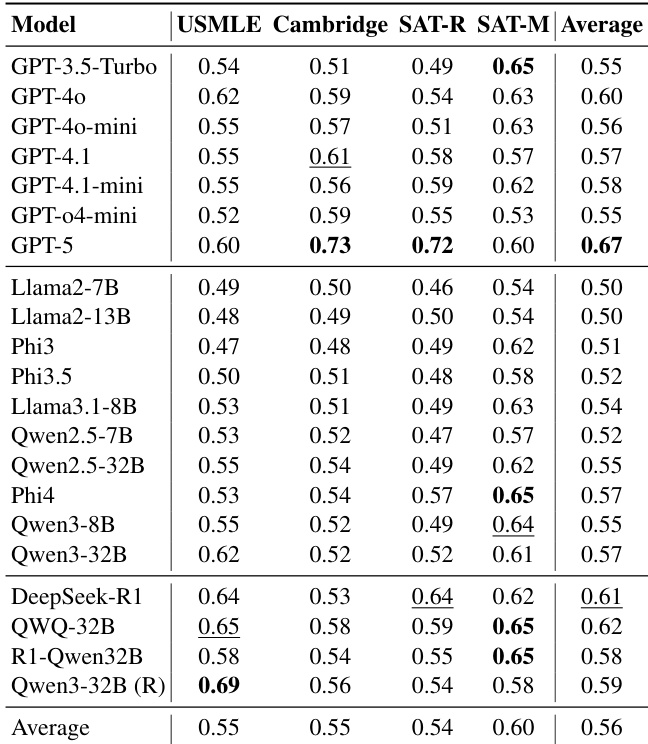
作者评估21个大语言模型在四个领域的能力,发现与人类难度排名的对齐度仍较弱,平均斯皮尔曼相关性低于0.50。扩大模型规模无法可靠提升对齐度;相反,模型彼此间一致性高于与人类现实的一致性,形成系统偏离学生体验的机器共识。即使GPT-4.1和DeepSeek-R1等高性能模型提升有限,且领域表现差异显著——知识密集型任务(如USMLE)对齐度尤其差。
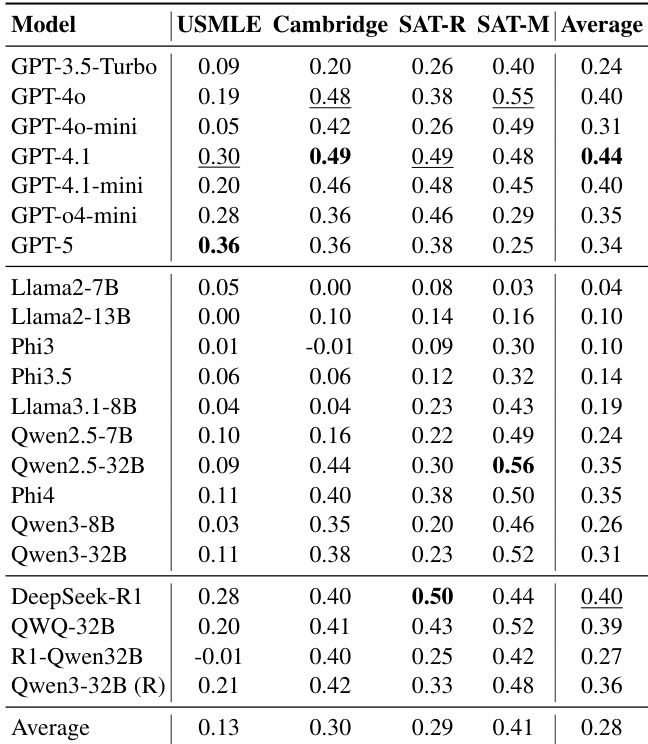
作者在四个领域通过零样本项目难度预测评估21个大语言模型,发现模型规模无法可靠提升与人类难度感知的对齐度。结果显示即使GPT-5和DeepSeek-R1等顶级模型在角色提示下仅取得微弱提升,多数模型趋同于偏离人类现实的机器共识。各领域对齐度普遍较弱——知识密集型任务(如USMLE)表现最差,而SAT数学等推理领域虽略好但仍有限,凸显模型能力与人类认知建模间的持久差距。
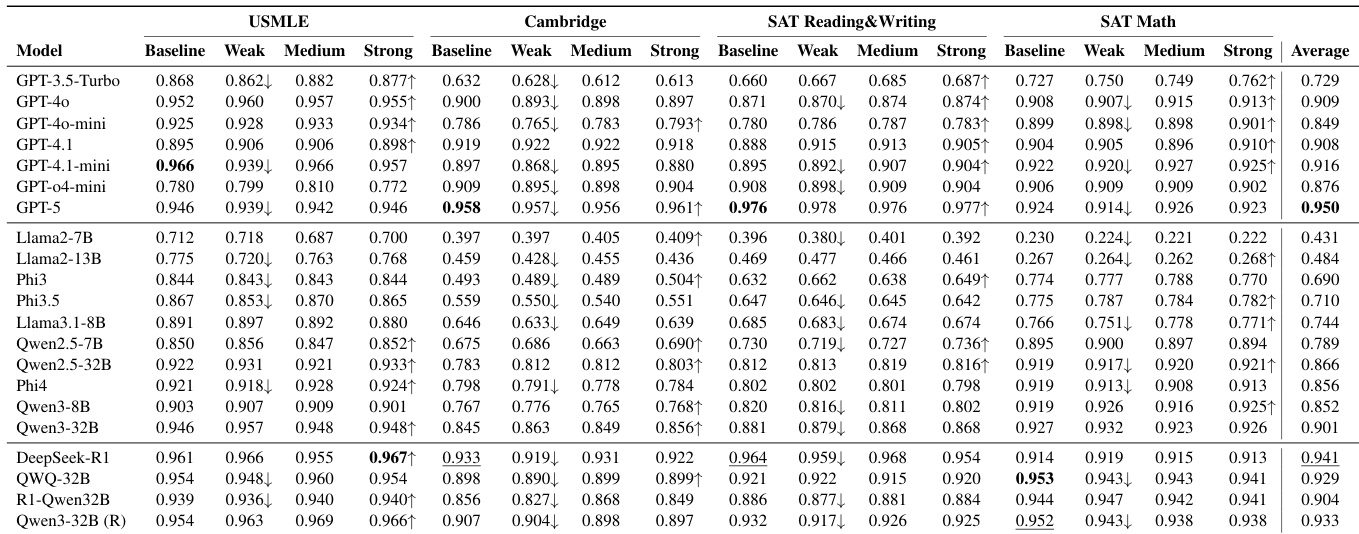
作者评估20多个大语言模型在四个领域的零样本项目难度预测能力,发现更大或更强模型并未持续提升与人类难度感知的对齐度。结果显示系统性错位:模型形成偏离人类现实的凝聚机器共识,且领域表现差异显著——SAT数学对齐度最高而USMLE最低。扩大模型规模或使用能力提示无法可靠提升对齐度,甚至GPT-5等顶级模型相比GPT-4.1等中端基线表现更差。
作者运用项目反应理论量化人类与模型难度感知的认知分歧,发现模型常将人类难题视为简单任务,尤其在USMLE等知识密集型领域中70.4%的人类难题被模型轻松解决。结果显示各领域饱和率普遍较高,表明模型高估学生能力;脆性极低说明模型很少在人类易题上失败。即使提示模型模拟低能力水平,此系统性错位仍持续存在,凸显其无法真实复现人类认知局限。