Command Palette
Search for a command to run...
MACE-Dance:用于音乐驱动舞蹈视频生成的运动-外观级联专家模型
MACE-Dance:用于音乐驱动舞蹈视频生成的运动-外观级联专家模型
Kaixing Yang Jiashu Zhu Xulong Tang Ziqiao Peng Xiangyue Zhang Puwei Wang Jiahong Wu Xiangxiang Chu Hongyan Liu Jun He
摘要
随着在线舞蹈视频平台的兴起以及人工智能生成内容(AIGC)技术的飞速发展,音乐驱动的舞蹈生成已成为一个引人注目的研究方向。尽管在音乐驱动3D舞蹈生成、姿态驱动图像动画以及音频驱动的人脸合成等相关领域已取得了显著进展,但现有方法难以直接适配这一任务。此外,目前该领域有限的研究仍难以同时实现高质量的视觉外观和逼真的人体运动。为此,我们提出了MACE-Dance,这是一种基于级联专家混合模型(Mixture-of-Experts, MoE)的音乐驱动舞蹈视频生成框架。其中,“运动专家”(Motion Expert)负责将音乐转化为3D动作,并在确保运动学合理性的同时兼顾艺术表现力;“外观专家”(Appearance Expert)则执行基于动作和参考条件的视频合成,通过时空一致性保持视觉身份特征。具体而言,“运动专家”采用具有BiMamba-Transformer混合架构以及无引导训练(Guidance-Free Training, GFT)策略的扩散模型,在3D舞蹈生成任务中达到了最先进水平(SOTA)。“外观专家”采用解耦的运动学与美学微调策略,在姿态驱动图像动画任务中同样达到了最先进水平(SOTA)。为了更好地对该任务进行基准评估,我们构建了一个大规模且多样化的数据集,并设计了一套运动与外观联合评估协议。基于该评估协议,MACE-Dance也取得了最先进水平(SOTA)的性能。项目主页:https://macedance.github.io/
一句话总结
MACE-Dance 是一个级联的专家混合(Mixture-of-Experts)框架,用于音乐驱动的视频生成。该框架采用带有无引导训练的 BiMamba-Transformer 混合扩散模型以强化运动合理性,并结合解耦的运动学-美学微调策略以保留视觉身份,在 3D 舞蹈生成、姿态驱动图像动画以及新制定的运动-外观评估协议上均取得了最先进的性能。
核心贡献
- MACE-Dance 被提出为一个级联的专家混合框架,通过将音乐驱动的 3D 编舞合成与视觉渲染解耦,解决了以往生成管线中的根本性不匹配问题。
- 运动专家(Motion Expert)利用带有无引导训练策略的 BiMamba-Transformer 混合扩散模型来强化运动合理性,而外观专家(Appearance Expert)则采用解耦的运动学-美学微调策略,以维持视觉身份与时空连贯性。
- 构建了大规模数据集并配套专用的运动-外观评估协议,使模型在 3D 舞蹈生成与姿态驱动图像动画任务上均实现了可基准测试的最先进性能。
引言
舞蹈类平台上 AI 生成内容的激增,使音乐驱动的视频生成成为关键研究方向,但现有方法难以同时保证运动合理性与高保真视觉外观。现有方法通常依赖孤立的 3D 运动合成或姿态驱动动画管线,无法捕捉舞蹈的全身复杂性,或因 2D 投影导致信息丢失,或需要手动编舞,从而导致运动质量下降与视觉失真。为克服这些局限,本文提出 MACE-Dance,一种将运动生成与视频合成分离的级联专家混合框架。运动专家利用带有无引导训练的 BiMamba-Transformer 混合扩散模型生成高效且符合物理规律的 3D 舞蹈序列,而外观专家则应用解耦的运动学-美学微调策略渲染视频,以保留视觉身份与时空连贯性。作为模型的补充,研究团队构建了 MA-Data 数据集并设计专用的运动-外观评估协议,为该新兴任务建立稳健的基准。
数据集
-
数据集构成与来源: 本文引入 MA-Data,一个专为音乐驱动舞蹈视频生成设计的大规模数据集。该数据集包含 70,000 个片段,每个片段时长 5 至 10 秒,总计约 116 小时,涵盖爵士、拉丁和东方民间等 20 余种舞蹈类型。它结合了两种互补来源:专业 3D 运动数据与现实社交媒体视频。
-
3D 渲染子集(运动为中心): 源自 FineDance 数据集,该部分包含 20,000 个片段(约 28 小时)。研究团队将原始运动序列重定向至标准角色模型并渲染正面视角视频。为最大化数据多样性,采用滑动窗口策略提取随机 5 至 10 秒片段。
-
自然场景子集(外观为中心): 筛选自 TikTok 和 YouTube 上高互动创作者的视频,该部分包含 50,000 个片段(约 88 小时)。研究团队应用严格的多阶段清洗管线以过滤低质量或不同步的内容。首先使用 TransNet V2 进行镜头边界检测,丢弃短于 5 秒的片段。随后利用光流幅度阈值移除近乎静态的画面。接着通过 ViTPose 强制单表演者约束,过滤包含多人或运动极少的片段。最后,使用带随机偏移的滑动窗口将长视频切分为 5 至 10 秒片段。
-
训练用途与混合比例: 研究团队将完整的 70,000 个片段集合用作主要训练集,保持 3D 渲染子集与自然场景子集之间 2:5 的比例。该混合比例在技术运动精度与视觉娱乐价值之间取得平衡。另外预留 200 个跨多种类型的高互动 5 秒片段作为测试集。
-
处理与裁剪策略: 该数据集高度依赖时间裁剪与对齐技术。两个子集均使用带随机偏移的滑动窗口提取以生成一致的片段长度。3D 源数据需要正面渲染与运动重定向,而自然场景源数据则通过 TransNet V2、光流分析与姿态估计进行自动化质量控制。除分类与策展期间使用的平台互动指标外,未详细说明其他元数据模式。
方法
MACE-Dance 框架采用级联专家混合(MoE)架构来解决音乐驱动舞蹈视频生成问题,将任务解耦为两个独立阶段:运动生成与外观合成。该设计使模型能够专注于特定子问题,降低整体复杂度并提升数据效率。框架输入音乐序列 M 与参考图像 I,生成对应的舞蹈视频 D。流程始于运动专家,将音乐转化为符合运动学合理性且具有艺术表现力的 3D 运动序列 X。该中间表示作为外观专家的基础,后者利用 X 和 I 生成具有时空连贯视觉外观的视频。通过明确使用 3D 运动作为两个专家间的桥梁,该框架避免了端到端模型的缺陷(如虚假的跨模态相关性),并为视频合成提供了可解释且可控的接口。采用 SMPL 作为 3D 运动表示进一步增强了模型捕捉全身几何结构与处理复杂运动的能力,相较于基于 2D 关键点的方法,提供了更丰富的空间保真度、更清晰的监督信号以及更强的鲁棒性。
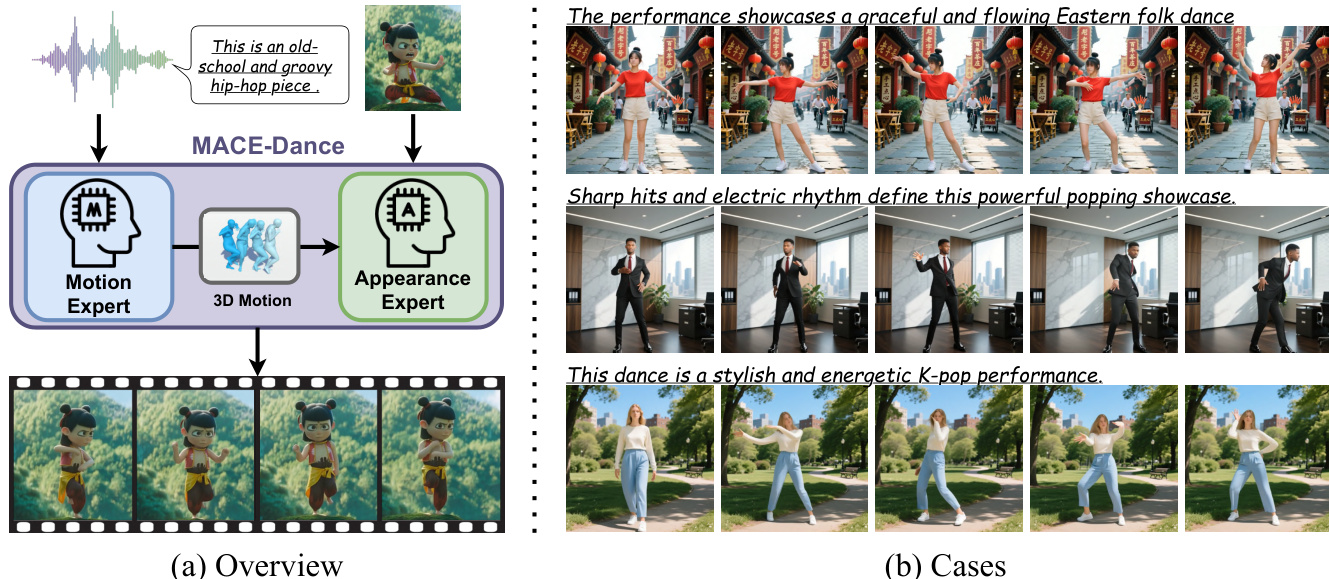
运动专家旨在生成时间连贯且与音乐对齐的 3D 舞蹈动作。它采用 BiMamba-Transformer 混合主干网络,结合两种架构的优势以建模局部与全局依赖关系。使用 Librosa 提取的输入音乐特征经过 Lm 层 BiMamba 处理,以捕捉模态内时间动态。扩散时间步 t 与温度参数 β 被编码为正弦嵌入,并通过逐元素相加融合为 t-β 嵌入,在生成器中全程使用。生成器核心由 Ld 个堆叠块组成。每个块将当前状态 zt 通过 BiMamba 处理以建模模态内局部依赖,随后使用 t-β 嵌入进行 FiLM 调制。Transformer 随后对音乐编码执行跨模态注意力以整合全局音乐上下文,结果进一步通过前馈网络处理。第二次 FiLM 调制强化了 t-β 条件控制。该架构实现了整个序列的非自回归生成,提升了效率并避免了曝光偏差。模型采用基于扩散的方法进行训练,具体为去噪扩散概率模型(DDPM)。前向加噪过程向 3D 运动序列添加高斯噪声,模型则学习在每个时间步从含噪潜在变量中估计原始运动以逆转该过程。为增强物理合理性与美学表现力,训练目标不仅包含重建损失,还包含 3D 关节、速度与脚部接触损失。模型采用无引导训练(GFT),通过参数化使模型在训练期间隐式表示温度控制的采样行为,缓解分布不匹配并实现更稳定的生成。推理阶段,模型使用去噪扩散隐式模型(DDIM)进行加速采样,其中 β 参数控制运动多样性与保真度之间的权衡。
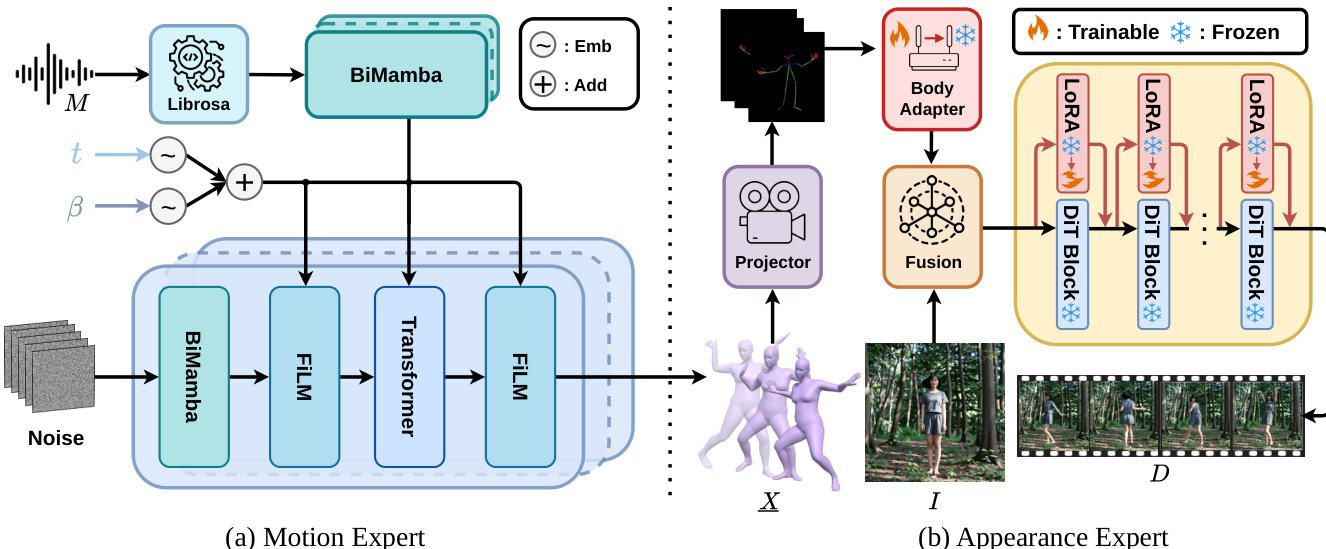
外观专家基于 Wan-Animate 框架构建,通过解耦的运动学-美学微调策略适配舞蹈视频生成。该策略在保持严格运动遵循的同时确保高保真外观合成。架构以参考图像 I 与 3D 运动序列 X 为输入。运动序列首先通过 3D 至 2D 运动投影器投影至 2D 关键点,该投影器在固定相机下渲染 SMPL 网格并使用 ViTPose 提取 2D 关键点。这些 2D 关键点由身体适配器编码以生成运动特征,随后与从参考图像提取的潜在变量融合。生成的潜在变量经过由堆叠 DiT 块组成的主干网络处理,其中轻量级 LoRA 适配器集成至每个块中。运动学阶段仅微调身体适配器,通过跨尺度重加权身体特征来强化运动条件控制,在不改变主干网络的前提下强制执行运动遵循。美学阶段仅微调 LoRA 参数,这些参数附着于每个 DiT 块中的注意力与前馈投影层。这使得模型能够专注于舞蹈特定美学(如锐化纹理与稳定服装),而不干扰运动控制路径。LoRA 的使用使得以少量可训练参数实现高效适配成为可能。训练过程包含两个阶段:首先训练运动学阶段以确保运动遵循,其次训练美学阶段以优化视觉质量。这种解耦方法使模型在保持底层预训练架构鲁棒性与效率的同时,实现高保真结果。
实验
评估建立了一套全面的运动-外观协议,将提出的双专家架构与最先进基线及通用视频基础模型进行基准测试,并辅以由舞蹈专家进行的人类偏好研究。定性与定量比较一致表明,明确将运动合成与视觉渲染分离,显著提升了运动合理性、节奏同步性与艺术多样性,同时消除了时间闪烁与物理不可能等常见伪影。消融研究与交叉验证进一步证实,关键架构选择(包括混合扩散架构、无引导训练策略与三维运动表示)对于维持长序列稳定性与高保真主体一致性至关重要。最终,客观测量与人类判断之间的高度一致性验证了该框架作为音乐驱动舞蹈视频生成的稳健且符合感知标准的地位。
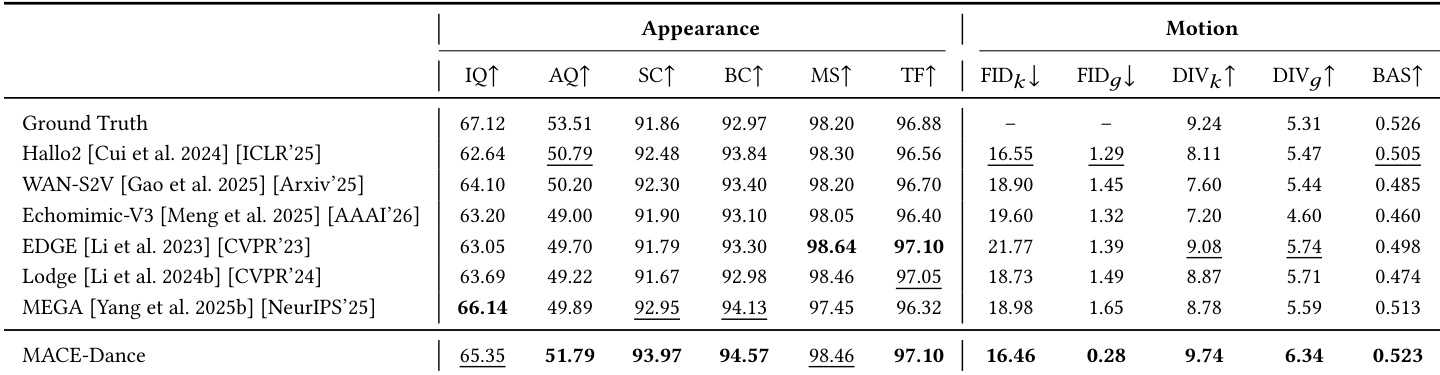
研究团队将所提方法与通用视频基础模型进行对比,使用全面协议评估运动与外观质量。结果表明,该方法在视觉保真度、身份一致性与音乐-运动对齐等关键指标上表现优异,在多数方面超越基线。用户研究进一步证实,参与者在运动表现力与视觉连贯性方面更偏好所提方法。与通用视频模型相比,所提方法在身份一致性与节拍对齐上取得最佳性能。该方法在视觉质量与运动同步性上优于基线模型,定量指标与用户偏好均验证了这一点。用户研究结果与定量评估一致,显示在运动与外观方面均强烈偏好所提方法。
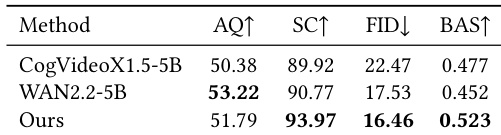
研究团队对 MACE-Dance 方法进行了全面评估,聚焦运动与外观质量。结果显示,所提方法在多项指标上达到最先进性能,展现出优越的运动合理性、艺术表现力,以及高保真且时间连贯的视觉外观。评估协议与人类感知高度吻合,用户研究证实该方法持续优于基线。MACE-Dance 在运动与外观质量上均取得最佳性能,展现出卓越的运动合理性与视觉保真度。评估指标与人类偏好高度相关,验证了所提运动-外观评估协议的有效性。该方法在生成多样化且富有表现力的舞蹈动作方面超越基线,同时保持时空一致性与身份保留。
研究团队通过用户研究评估 MACE-Dance,在舞蹈视频生成的多个维度上与多种最先进基线进行对比。结果显示,MACE-Dance 在所有六项评估指标的用户偏好上持续优于所有对比方法,表明其在运动与外观质量上表现卓越。用户研究的定量指标与所提运动-外观评估协议高度一致,证实其在捕捉人类感知方面的有效性。MACE-Dance 在所有六项评估维度(包括舞蹈创意、质量、同步性,以及感知与身份一致性)上获得最高用户偏好。用户研究结果表明,MACE-Dance 显著优于所有基线方法,各指标偏好率介于 50% 至 65% 以上。定量评估指标与人类感知高度相关,验证了所提运动-外观评估协议作为评估音乐驱动舞蹈视频生成任务的可靠框架。
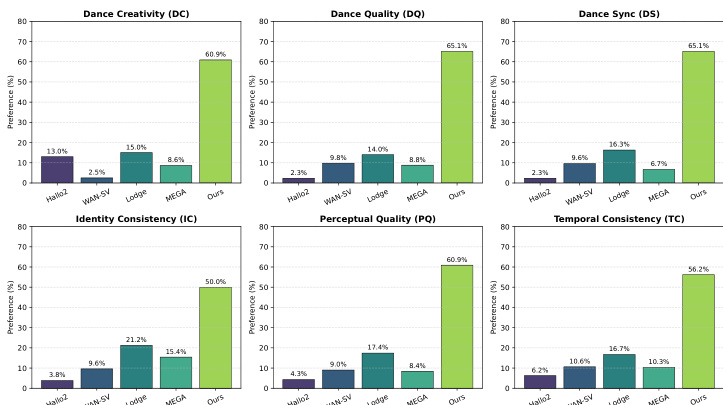
研究团队对提出的 MACE-Dance 方法进行了全面评估,在外观与运动维度上与多种最先进基线进行对比。结果显示,MACE-Dance 在多数指标上取得最佳性能,尤其在运动质量与外观保真度方面,在运动合理性、音乐同步性与视觉连贯性上超越其他方法。评估包含定量指标与用户研究,证实 MACE-Dance 能够生成高质量、富有表现力且一致的视频。MACE-Dance 在多数指标上表现最佳,尤其在运动质量与外观保真度方面。该方法在运动合理性、音乐-运动同步性与视觉一致性上优于基线。用户研究证实,MACE-Dance 在所有评估维度(包括运动表现力与视觉质量)上均获偏好。
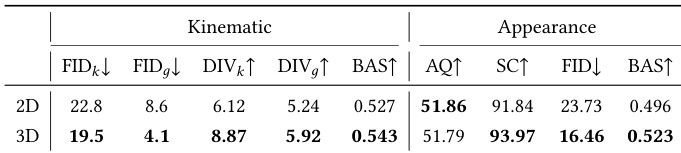
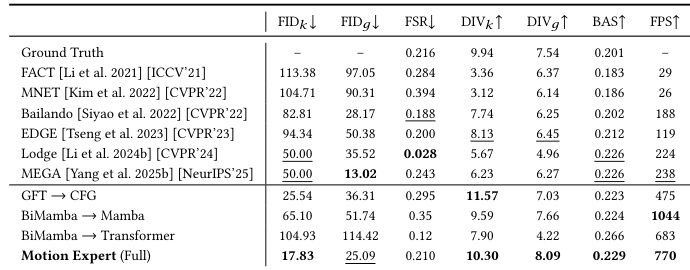
研究团队在音乐驱动 3D 舞蹈生成任务上评估所提出的运动专家模型,并与多种最先进方法进行对比。结果显示,运动专家在运动保真度、多样性与同步性等多项指标上取得最佳性能,表明其具备卓越的生成质量与效率。评估包含定量比较与定性分析,凸显了模型架构与训练策略的有效性。运动专家在所有运动相关指标(包括保真度、多样性与同步性)上均取得最佳结果。相较于现有方法,该模型在运动质量与生成效率上展现出优越性能。评估证实了所提架构与训练策略在生成高质量 3D 舞蹈动作方面的有效性。
研究团队结合定量指标与用户研究,将所提方法与通用视频基础模型及最先进基线进行全面对比。实验验证了运动保真度、视觉外观与音乐同步性,表明该方法在运动合理性、身份保留与时序连贯性上持续优于现有方法。定性评估与用户偏好与定量结果高度一致,凸显出学界对该方法卓越运动表现力与视觉质量的明确共识。这些发现证实,评估框架准确捕捉了人类感知,同时确立了该方法作为高质量音乐驱动舞蹈生成任务的稳健解决方案。