Command Palette
Search for a command to run...
SAM Audio:音频中的任意分割
SAM Audio:音频中的任意分割
摘要
通用音频源分离是多模态人工智能系统感知与推理声音信息的关键能力。尽管近年来取得了显著进展,现有分离模型仍存在局限:部分模型局限于特定领域,仅针对语音或音乐等固定类别进行设计;另一些模型则在可控性方面受限,仅支持单一提示模态(如文本提示)。在本研究中,我们提出 SAM Audio——一种面向通用音频分离的基础模型,首次在统一框架内融合了文本、视觉和时间区间三种提示方式。SAM Audio 基于扩散Transformer架构,利用涵盖语音、音乐及各类通用声音的大规模音频数据,通过流匹配(flow matching)进行训练,能够灵活地根据语言描述、视觉掩码或时间区间提示,分离出目标声源。该模型在涵盖通用声音、语音、音乐以及乐器分离等多个任务的多样化基准测试中均达到当前最优性能,无论是在真实场景采集的音频(in-the-wild)还是专业制作的音频中,均显著超越此前的通用型与专用型系统。此外,我们还构建了一个新的真实世界分离基准,包含人工标注的多模态提示,并提出一种无需参考音频的评估模型,其评估结果与人类判断具有高度相关性。
一句话总结
Meta Superintelligence Labs 研究人员等提出 SAM AUDIO,这是一种通用音频分离基础模型,首次在单一扩散变换器框架内统一了文本、视觉和时间跨度提示,并通过流匹配技术在多样化音频数据上进行训练。与局限于单一模态的领域专用先驱模型不同,它在声音、语音和音乐基准测试中均达到最先进性能,同时引入了新的真实世界评估框架——其无参考指标与人类判断高度相关。
主要贡献
- 现有基于文本提示的音频分离方法在复杂场景(如重叠语音或细微音效)中难以区分目标声音,因为纯文本描述缺乏时间精度,且专用领域性能仍逊于任务特定系统。
- 作者提出时间跨度提示(span prompting),这是一种新型时间条件机制,通过直接在混合音频中指定目标时间区间实现精确声音事件分离,无需外部参考音频或注册语音。
- 该方法解决了现有说话人提取系统需清洁参考样本的关键限制,在保持内容无损分离(不改变混响等固有音频属性)的同时提供灵活的时间控制。
引言
音频分离对语音识别和助听器等应用至关重要,它能从混合信号中分离目标声音以实现更清晰的音频处理。先前研究存在关键局限:多数模型受限于固定本体(如音乐分离仅支持4-5种音轨),而基于文本提示的方法在缺乏参考音频时难以区分细微声音,且常在非真实的合成混合数据上训练。作者通过引入 SAM Audio 弥合这些差距:该模型利用伪标签数据引擎,基于文本提示和严格多阶段过滤从未标注音频生成真实训练样本;同时提出无参考感知评估模型,其与人类判断更一致,克服了 SDR 等传统指标与真实音频质量相关性差的问题。
数据集
- 作者构建 SAM AUDIO 使用两大主要数据源:大规模(约100万小时)中等质量音视频语料库,以及覆盖语音、音乐和通用音效的小型高质量音频数据集。
- 关键子集包括:
- 全真实音乐:10,610首作品(536小时)含乐器音轨;通过组合内混音构建三元组,音轨经±5 dB 信噪比偏移重缩放。
- 全真实语音:21,910小时对话音频;从双说话人混合信号创建三元组,残余信号经±15 dB 信噪比偏移重缩放。
- 合成混合信号:清洁音乐/语音与通用音效库噪声混合(±15 dB 信噪比);通用音效组合覆盖"野外"和专业录音。
- 视频提示数据:通过 ImageBind 评分(>阈值)筛选自然视频确保视听一致性;使用 SAM 2 生成视觉掩码。
- 时间跨度提示数据:源自 HQ SFX(孤立事件)的目标声音,通过 VAD 检测跨度(静音阈值:-40 dBFS,最小持续时间:250 ms)。
- 训练时,作者在所有子集中混合真实与合成数据,形成元组 (xmix,xtgt,xres,c),其中 c 表示文本/视频/跨度提示。全真实数据提供直接监督,合成数据扩展领域覆盖。
- 关键处理步骤包括:基于信噪比的重缩放增强鲁棒性、ImageBind 过滤排除视频数据中的叙事外声音、PLM-Audio 从声音描述生成文本提示。跨度提示由二值 VAD 掩码转换为时间区间。
方法
作者基于扩散变换器(DiT)构建统一生成框架实现多模态音频源分离。如图所示,该核心架构接收音频混合信号,并基于文本、视觉或时间跨度提示的任意组合进行条件分离,在单次前向传递中同步生成目标音轨和包含其余内容的残余音轨。
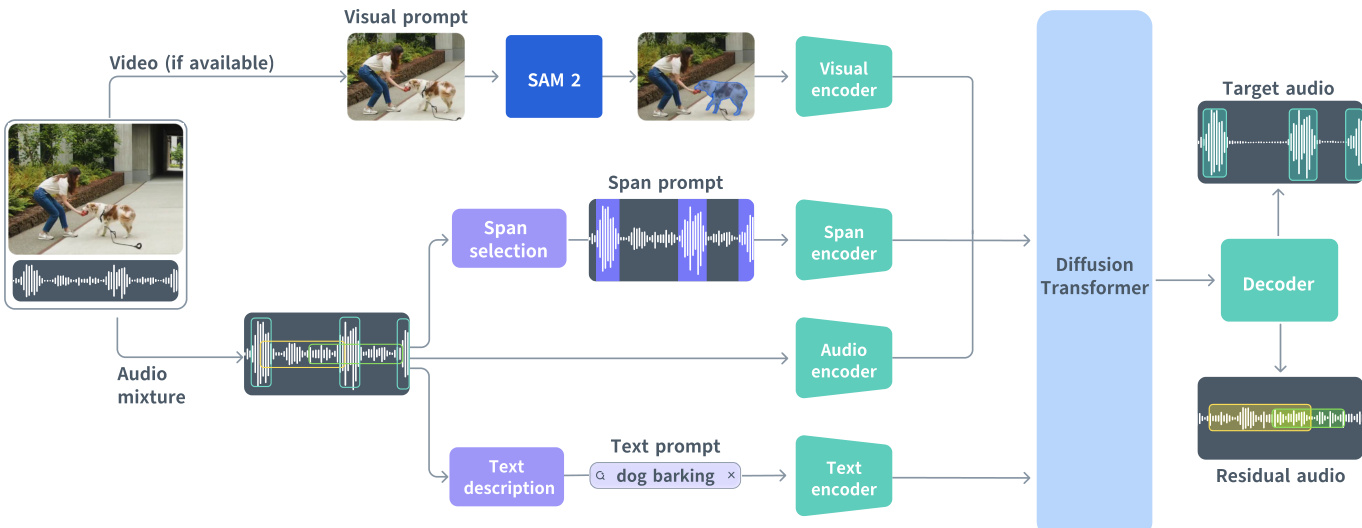
模型核心是在 DAC-VAE 潜空间中运行的流匹配目标。音频混合信号首先编码为紧凑潜序列 xmix∈RT×C(25 Hz,C=128)。模型学习将高斯先验 x0∼N(0,I) 传输至联合目标-残余表示 x=[xtgt,xres]∈RT×2C(连续时间变量 t∈[0,1])。DiT 主干预测瞬时速度场 u(xt,c,t;θ),经积分生成最终输出。每个变换器块通过缩放-移位操作受流时间 t 调制,参数跨块共享以减小模型规模同时保持性能。
三种提示模态经不同方式编码整合。文本提示(通常为简短动宾短语如"狗吠叫")通过冻结的 T5-base 编码器编码为全局词元特征序列 ctxt∈RNtxt×768,经交叉注意力层注入 DiT。视觉提示源自用户通过 SAM 2 在视频帧上的交互,由感知编码器(PE)提取帧级特征,重采样匹配音频帧率后与音频潜特征通道拼接。跨度提示定义为时间区间集合 S∈Rk×2,转换为指示激活/静默帧的帧同步二值词元序列,经可学习表嵌入后与音频特征拼接以提供显式时间先验。
训练时针对缺失模态使用虚拟条件:文本为空字符串,视频为全零向量,跨度为无效词元。模型进一步通过训练时随机丢弃各提示类型(可配置概率)增强鲁棒性。训练目标结合流匹配损失 LFM 与辅助对齐损失 Laux:后者将 DiT 中间表示投影至外部音频事件检测(AED)模型的嵌入空间,并最小化与真实目标嵌入的余弦距离。总损失为 L=LFM+λLaux。
针对长音频,作者采用重叠窗口的多扩散策略。在每个流步骤中,独立求解各窗口的常微分方程,并通过归一化软掩码合并预测结果以确保时间连贯性并避免边界伪影。推理时默认为纯文本提示启用跨度预测:使用辅助模型 PEA-Frame 估计帧级活动性,生成近似跨度序列后与原始文本提示结合进行条件控制。
实验
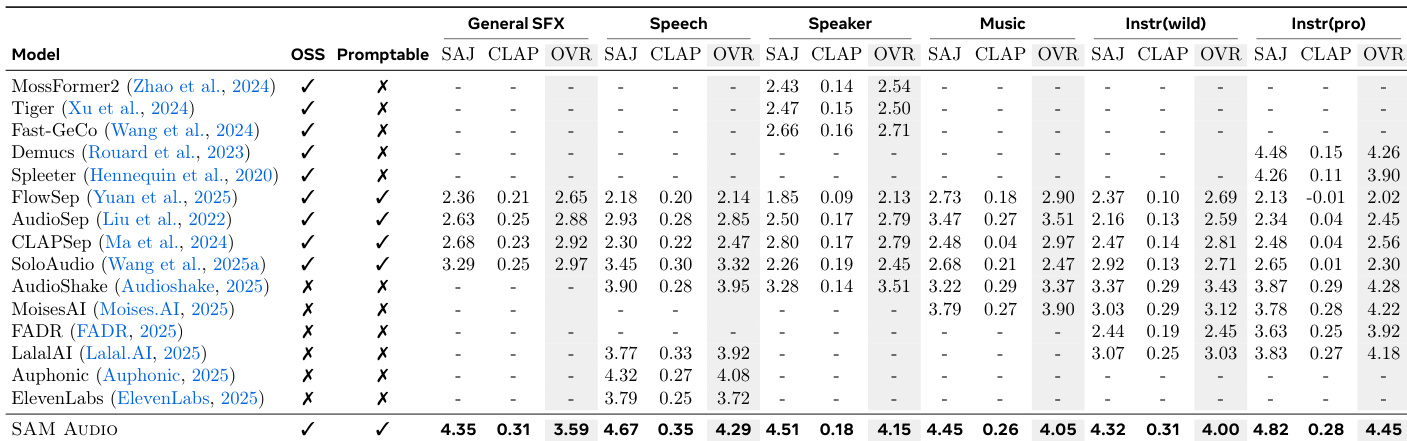
- 文本提示分离:MUSDB 上 OVR 达 4.45,超越 AudioShake (4.28);通用音效事件中对 SoloAudio 净胜率提升 36%。
- 视觉提示分离:各项任务中对 DAVIS 净胜率领先 5-48%,说话人分离质量提升 25%。
- 跨度提示分离:文本与跨度输入组合使净胜率较纯文本条件提升 12.9-39.0%。
- 音乐移除:在目标声音抑制的残余音频质量上超越 MoisesAI 和 AudioShake。
- SAJ 评估模型:语音分离中与人类评分的皮尔逊相关系数达 0.883,优于 CLAP 和 SDR Estimator。
- 模型扩展:30 亿参数变体在乐器分离任务中净胜率较小型模型提升 23%。
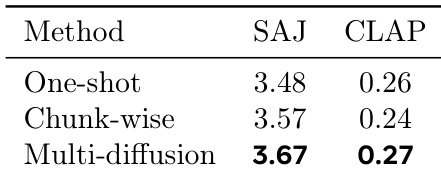
作者使用 SAJ 和 CLAP 指标评估三种长音频分离策略,发现多扩散策略在两项指标中均获最高分,表明其感知质量与语义对齐性更优。结果证实多扩散策略优于单次处理和分块方法(后者分别存在质量下降和不连续性问题)。
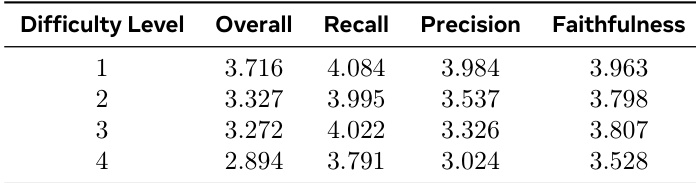
人类评分显示,随着任务难度增加分离质量下降:整体评分从 1 级 3.716 降至 4 级 2.894。查全率与保真度逐步退化,而查准率降幅最显著,从 3.984 降至 3.024。
作者使用客观指标(SAJ, CLAP)和主观总分(OVR)评估 SAM Audio 在文本提示分离任务中与多个基线的对比。SAM Audio 在所有类别中均获最高 OVR 分数,超越通用和专用模型,在说话人与专业乐器分离中优势尤为显著。结果证实统一训练使 SAM Audio 能有效泛化并树立新最先进性能。
在文本提示音乐移除任务中,SAM AUDIO 主观总分(4.05)高于 AudioShake (3.75) 和 MoisesAI (4.00),表明其在抑制目标声音的同时能更好地保持残余音频感知质量。

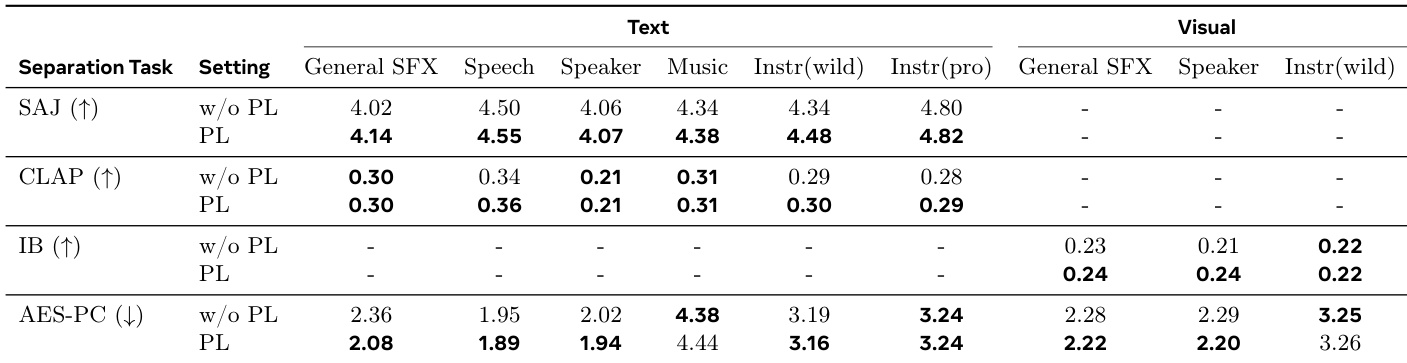
作者通过客观指标评估文本与视觉提示下的 SAM AUDIO,表明伪标签数据(PL)微调普遍提升性能:文本提示中 PL 在多数任务提升 SAJ 分数,并增强音乐与专业乐器分离的 AES-PC 分数,CLAP 分数保持稳定;视觉提示下 PL 改善通用音效与乐器分离的 ImageBind 对齐度,降低 AES-PC 值(指示更纯净输出)。