Command Palette
Search for a command to run...
世界即你的画布:通过参考图像、轨迹与文本绘制可提示事件
世界即你的画布:通过参考图像、轨迹与文本绘制可提示事件
摘要
我们提出 WorldCanvas,一个可由提示驱动的世界事件生成框架,通过结合文本、轨迹和参考图像,实现丰富且由用户主导的模拟。与仅依赖文本的方法以及现有的轨迹控制图像到视频生成方法不同,我们的多模态方法将轨迹(编码运动、时间与可见性)与自然语言(表达语义意图)及参考图像(提供物体身份的视觉锚定)相结合,从而生成具有多智能体交互、物体进出、参考引导的外观变化以及反直觉事件的连贯、可控的场景。生成的视频不仅具备时间上的连贯性,还展现出涌现的一致性,即使物体短暂消失,其身份与场景结构仍能被有效保持。通过支持富有表现力的世界事件生成,WorldCanvas 使世界模型从被动预测者演进为可交互、由用户塑造的模拟器。项目主页详见:https://worldcanvas.github.io/。
一句话总结
来自香港科技大学、蚂蚁集团等机构的研究人员提出了 WorldCanvas 框架,该框架通过独特整合文本提示、运动编码轨迹和参考图像进行视觉定位,从而生成可控的世界事件。与先前仅依赖文本或轨迹受限的方法不同,它支持多智能体交互、物体进出场景及反直觉场景,同时保持涌现一致性,将世界模型推进为复杂事件模拟的交互式仿真器。
核心贡献
- WorldCanvas 解决了现有世界模型作为被动预测器且用户控制能力有限的问题,通过引入框架生成语义明确的"可提示世界事件",使用户能够主动塑造环境动态而不仅是被动观察。
- 该框架通过空间感知加权交叉注意力机制,独特整合了用于运动与时间的轨迹、用于物体身份的参考图像及用于语义意图的自然语言,实现对多智能体交互和物体进出等复杂事件的精确控制。
- 生成的视频展现出时间连贯性与涌现物体一致性,在临时遮挡期间保持身份与场景上下文,同时支持反直觉事件和参考引导的外观生成,无需定量基准或特定数据集。
引言
传统世界模型专注于通过低级重建进行被动预测,将用户控制限制在导航层面而非主动环境变更。先前基于文本提示的方法缺乏复杂事件所需的空间与时间精度,而轨迹控制的视频生成方法将运动路径视为粗略位置线索,未建模可见性、时间或物体身份,导致多智能体交互或物体进出场景的可控性较差。作者提出多模态框架 WorldCanvas——整合自然语言(语义意图)、参考图像(视觉定位)及编码运动、时间与可见性的轨迹,实现对世界事件中"何事、何时、何地、何人"的精确指定。其贡献包括:构建定制多模态数据流水线,以及空间感知加权交叉注意力机制,将上述输入融合至预训练视频模型,从而在遮挡期间生成具有涌现物体一致性的反直觉事件。这使世界模型从被动预测器进化为支持用户主导环境动态的交互式仿真器。
数据集
作者构建了轨迹-参考图像-文本三元组数据集,以实现多智能体场景中的精确语义-时空对齐。关键细节包括:
-
来源与构成:
基于公开视频分割为镜头一致的片段。每个三元组关联被追踪物体轨迹、聚焦运动的描述文本及转换后的参考图像。 -
子集处理:
- 追踪:首帧通过 YOLO 检测物体,SAM 生成掩码;每掩码提取 1-3 个代表性关键点(含背景点)并用 CoTracker3 追踪。随机裁剪模拟物体入场景,运动分数过滤(基于累积位移)剔除近静态片段。
- 描述生成:在视频上可视化轨迹(按物体身份着色),使用 Qwen2.5-VL 72B 生成描述。描述保留最小主体标识符(如"一名男子")并关联运动描述,确保语言聚焦运动。
- 参考图像:首帧前景物体经轻微仿射变换(平移、缩放、旋转)创建交互生成的灵活起始位置。
-
训练用途:
流水线生成描述与单条轨迹明确对应的三元组。参考图像实现视觉定位,裁剪帧与变换物体模拟屏幕外进入。这些三元组训练模型的空间感知加权交叉注意力,使描述与轨迹对齐,支持通过拖放界面实现用户控制动画。未指定显式划分比例,但运动分数过滤确保高质量动态序列主导训练数据。
方法
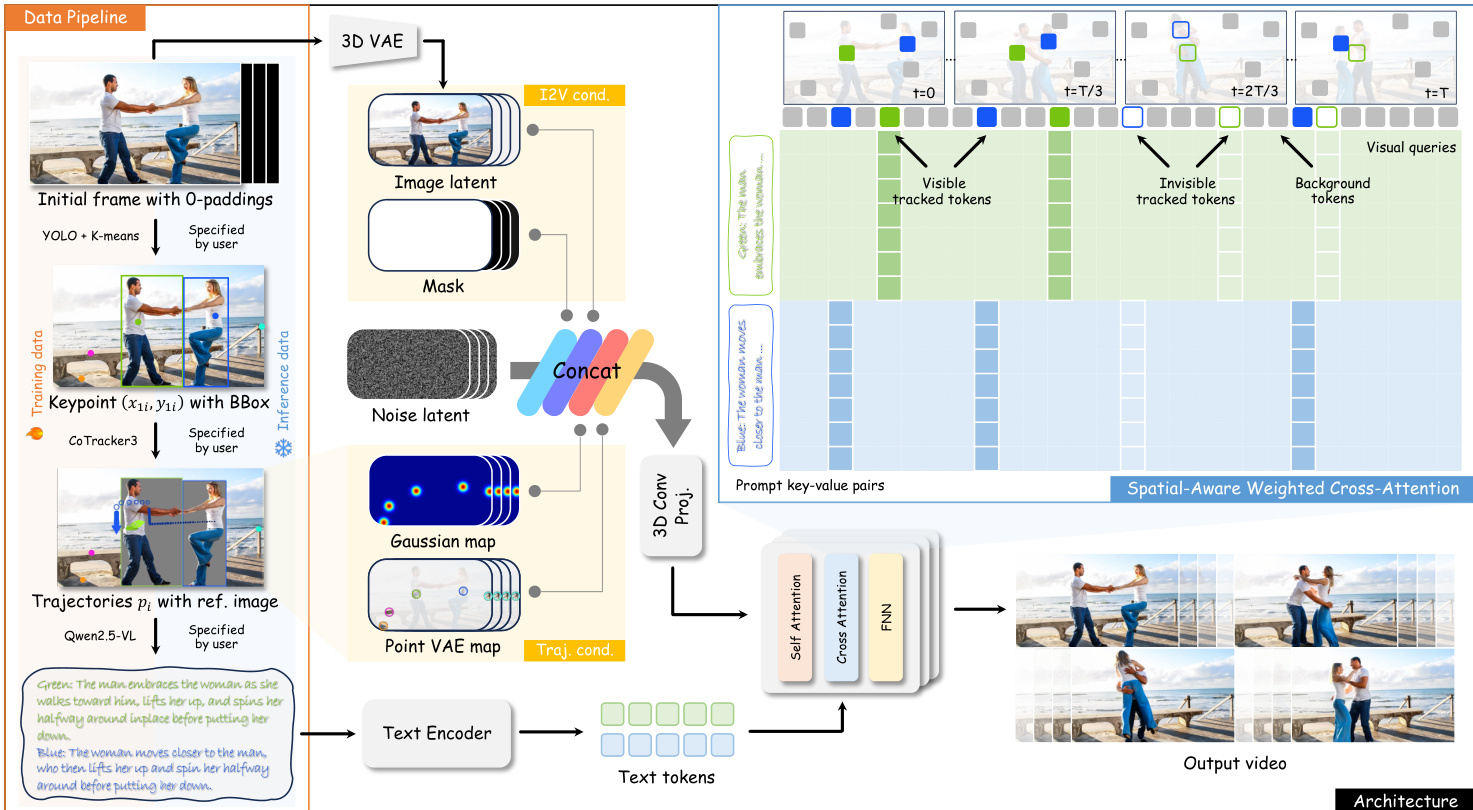
作者基于 Wan2.2 I2V 14B 模型构建多模态条件框架,实现细粒度轨迹引导视频生成。核心创新在于将轨迹、参考图像和运动聚焦文本三种模态结构化整合至扩散过程,使用户可指定场景中每个智能体的"何时、何地、何人、何事"。整体架构旨在将文本语义绑定至空间运动线索,同时通过参考条件保持视觉身份。
参考框架图,该图展示了从数据准备到视频合成的端到端流水线。系统始于数据整理阶段:使用 CoTracker3 从视频帧提取轨迹,结合 YOLO + K-means 的边界框,并通过 Qwen2.5-VL 标注动作中心描述。这些三元组 (pi,bboxi,capi) 构成训练信号,其中 pi={(xti,yti,vti)}t=1T 编码每帧 2D 位置与可见性,bboxi 锚定物体初始外观,capi 描述运动语义。
训练期间,轨迹信息通过两种互补表示注入 DiT 主干:高斯热力图编码空间占用,点 VAE 图将首帧 VAE 潜变量沿轨迹时间路径传播。这些表示与标准 DiT 输入(噪声潜变量、图像潜变量、掩码)拼接,经 3D 卷积投影层对齐维度。此注入机制使模型能基于用户指定路径生成运动,同时保持时间连贯性。
为解决多智能体场景的歧义,作者提出空间感知加权交叉注意力。对每条轨迹-描述对,模型计算以 (xti,yti) 为中心、尺寸匹配 bboxi 的空间覆盖区域。落在此区域的视觉查询标记 Qq 在关注由 capi 导出的键值对 Ki 时被赋予更高注意力权重。权重偏置 Wqk 定义为:
Wqk={logw,0,if vti=1 and Qq∈Qi and Kk∈Kiotherwise其中 w=30 为经验设定值。最终注意力输出计算为:
Attention(Q,K,V)=Softmax(DQKT+W)V该机制确保每条运动描述仅影响与其轨迹空间对齐的视觉标记,在保留全局上下文的同时实现局部语义控制。
训练采用流匹配目标与 L1 重建损失。给定噪声 x0∼N(0,I)、时间步 t∈[0,1] 及真实视频潜变量 x1,模型从插值输入 xt=tx1+(1−t)x0 预测速度 vt=x1−x0. 损失函数为:
L=Ex0,x1,t,C[∥u(xt,t,C;θ)−vt∥2]其中 C 聚合所有条件信号,θ 表示模型参数。
推理时,用户通过直观界面交互:以点序列形式输入轨迹,配置时间、间距(控制速度)及可见性标志(处理遮挡或进出)。每条轨迹绑定运动描述,参考图像插入首帧定义物体外观。模型随后合成符合指定时空、语义及视觉约束的视频。
实验
- 在 100 组图像-轨迹对的自定义基准上超越 Wan2.2 I2V、ATI 和 Frame In-N-Out,实现 ObjMC 1.82(基线 2.15–2.38)、外观匹配率 94.3%(基线 89.7%–92.1%)及 CLIP-T 0.31(基线 0.26–0.28),证明轨迹跟踪与语义对齐的优越性.
- 在复杂场景中实现精确的多主体轨迹-文本对齐(如图 4 正确绑定不同运动至文本描述,而基线失败),并在引导生成中保持参考图像一致性.
- 验证遮挡或屏幕外间隔期间物体与场景的一致性维护能力,跨帧保持视觉身份(图 5).
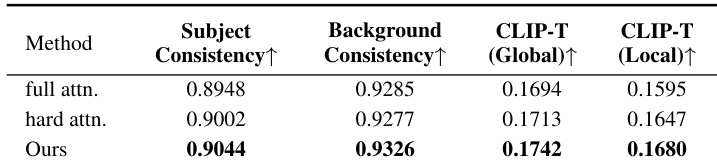
- 消融实验证实空间感知加权交叉注意力的必要性:移除后 ObjMC 升至 2.38 且 CLIP-T 评分下降,导致语义-动作错位.
- 人工评估显示 78.3% 偏好轨迹跟踪,76.0% 偏好提示遵循,所有指标显著超越基线.
作者基于五项标准(含轨迹跟踪、提示遵循及参考保真度)通过人工评估对比 WorldCanvas 与三种基线. 结果显示 WorldCanvas 在所有类别均显著领先,尤其在文本-轨迹对齐与参考保真度方面,证明其生成可控、语义准确且视觉一致世界事件的卓越能力.

作者通过一致性与语义对齐指标,对比空间感知加权交叉注意力与全注意力、硬注意力变体. 结果显示该方法在主体与背景一致性及全局/局部 CLIP-T 评分上均达最高分,证实其对齐文本与轨迹的有效性. 这证明空间加权通过保持语义与视觉保真度,提升了多智能体事件生成能力.
作者通过轨迹跟踪、时间一致性及语义对齐的定量指标对比 WorldCanvas 与三种基线. 结果显示 WorldCanvas 在所有指标上表现最佳,包括最低 ObjMC 分数及最高外观匹配率、主体一致性与背景一致性,证明其在生成可提示世界事件中卓越的控制力与保真度.
