Command Palette
Search for a command to run...
下一代嵌入预测助力强大视觉学习器的构建
下一代嵌入预测助力强大视觉学习器的构建
Sihan Xu Ziqiao Ma Wenhao Chai Xuweiyi Chen Weiyang Jin Joyce Chai Saining Xie Stella X. Yu
摘要
受自然语言处理中生成式预训练成功的启发,我们探讨一个核心问题:同样的原理是否也能催生强大的自监督视觉学习模型?与传统方法中训练模型输出用于下游任务的特征不同,我们转而训练模型直接生成嵌入(embeddings),以执行预测任务。本研究探索了从“学习表示”向“学习模型”这一范式转变的可能性。具体而言,模型通过因果掩码(causal masking)与停止梯度(stop gradient)机制,学习基于历史图像块嵌入来预测未来的图像块嵌入,这一方法我们称之为下一嵌入预测自回归(Next-Embedding Predictive Autoregression, NEPA)。我们证明,仅以“下一嵌入预测”作为唯一学习目标,对ImageNet-1k数据集进行预训练的简单Transformer模型即可取得显著效果——无需像素级重建、无需离散token、无需对比损失(contrastive loss),也无需为特定任务设计的头部结构(task-specific heads)。该方法在保持模型架构简洁性与可扩展性的同时,避免了额外的设计复杂度。在微调后,NEPA在ImageNet-1K上分别实现了83.8%(ViT-B)和85.3%(ViT-L)的top-1准确率,并在ADE20K数据集的语义分割任务中展现出优异的迁移能力。我们认为,基于嵌入的生成式预训练为视觉自监督学习提供了一种简洁、可扩展且具有潜在跨模态通用性的替代方案。
一句话总结
密歇根大学、纽约大学等机构的研究人员提出NEPA,一种生成式预训练框架。该框架通过因果掩码和停止梯度自回归预测未来图像块嵌入,将视觉学习从表征学习转向直接预测建模。该方法摒弃了像素重建、离散标记和对比损失,在ViT-L上实现85.3%的ImageNet-1K准确率,并有效迁移至ADE20K语义分割任务。
核心贡献
- 当前视觉自监督学习方法通常将表征学习与任务执行分离,尽管语言生成预训练取得进展,但仍需对比损失、像素重建或任务特定头等额外组件。
- 作者提出Next-Embedding Predictive Autoregression (NEPA),该方法训练Transformer仅通过因果掩码和停止梯度,以前序图像块嵌入直接预测后续嵌入作为唯一预训练目标,无需离散标记、解码器或辅助损失。
- NEPA在ViT-B和ViT-L骨干网络上微调后,分别在ImageNet-1K上达到83.8%和85.3%的top-1准确率,并有效迁移至ADE20K语义分割任务,仅依赖ImageNet-1k预训练且无需像素级重建。
引言
作者探索语言建模中的生成预训练原则能否构建强大的视觉自监督学习器,解决视觉模型在自回归预测应用上落后于语言模型的问题。现有视觉自监督方法面临权衡:对比学习需大批次或内存库,像素重建难以扩展且语义薄弱,甚至JEPA等表征预测框架仍以表征为中心,需独立下游头而非直接利用预测执行任务。作者提出Next-Embedding Predictive Autoregression (NEPA),该方法训练简易Transformer,通过因果掩码和停止梯度从前序图像块嵌入预测后续嵌入,全程在嵌入空间操作,无需像素重建、离散标记器或辅助组件。该方法在ImageNet-1K上取得竞争性准确率(ViT-B达83.8%),有效迁移至分割任务,同时具备架构简洁性和潜在的模态无关适用性。
数据集
作者在实验中使用两个主要数据集:
- ImageNet-1k (ILSVRC):通过Hugging Face
datasets获取;作为ImageNet分类实验的核心数据集。 - ADE20K:使用
mmsegmentation的标准流程处理分割任务。
关键细节:
- 实现部分未提供任一数据集的子集规模、过滤规则或组成细节。
- ImageNet-1k明确通过Hugging Face获取,ADE20K遵循
mmsegmentation的标准预处理流程。
数据使用与处理:
- 提供文本中未详述训练分割比例及混合比率。
- 数据增强采用
timm工具,特别是Mixup和create_transform,适用于所有ImageNet实验。 - 未描述裁剪策略或自定义元数据构建;ADE20K遵循
mmsegmentation默认配方。
论文聚焦实现基础设施(如Hugging Face transformers、timm),数据集处理依赖这些库的原生流程。
方法
作者采用极简自回归框架进行视觉预训练,称为Next-Embedding Predictive Autoregression (NEPA),其模仿语言模型的因果预测范式,但全程在连续嵌入空间操作。核心思想是训练模型根据前序嵌入预测后续图像块嵌入,无需像素重建、离散标记化或对比机制。
流程始于将输入图像 x 分解为 T 个非重叠图像块,通过共享编码器 f 映射为连续嵌入,生成序列 z={z1,z2,…,zT}。自回归预测器 hθ 随后训练建模后续嵌入的条件分布:
zt+1=hθ(z<t).该设计避免了独立解码器或动量编码器的需求,在保持预测因果结构的同时降低架构复杂度。
为稳定训练并防止坍缩,作者采用受SimSiam启发的基于相似度的损失。预测嵌入 zt+1 与目标 zt+1(从梯度图分离)进行比较。两向量经L2归一化后,损失计算为负余弦相似度:
\mathcal{D}(z, \widehat{z}) = -\frac{1}{T-1} \sum_{t=1}^{T-1} \left( \frac{z_{t+1}}{\|z_{t+1}\|_2} \cdot \frac{\widehat{z}_{t+1}}{\|\widehat{z}_{t+1}\|_2} \right) $$ ,最终损失定义为 $\mathcal{L} = \mathcal{D}(\mathrm{stopgrad}(z), \widehat{z})$。该目标在无需显式重建的情况下促进语义对齐。 参考框架示意图,该图展示了自回归预测机制:给定嵌入图像块序列,模型基于所有先前上下文预测后续嵌入,目标图像块高亮显示以明确示意。 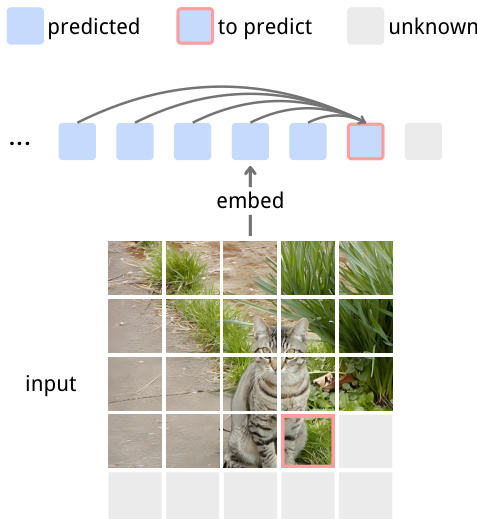 模型架构基于标准Vision Transformer骨干网络,采用因果注意力掩码,实现从前序嵌入直接预测后续嵌入。图像通过Conv2d图像块嵌入器分词,添加可学习位置嵌入后输入Transformer。作者整合现代稳定化技术以提升训练动态和可扩展性,包括用于相对位置编码的RoPE、用于残差分支稳定化的LayerScale、作为前馈层激活函数的SwiGLU,以及缓解注意力不稳定的QK-Norm。如架构图所示,这些组件均匀应用于所有层。 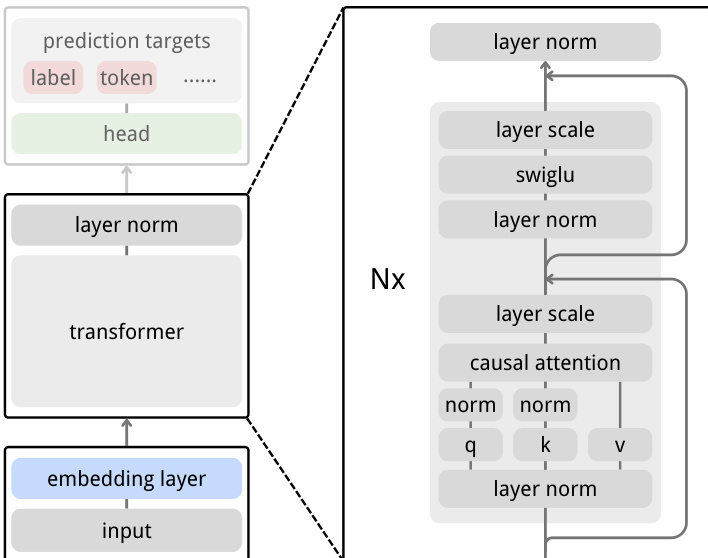 与采用非对称编码器和专用评分头的JEPA相比,NEPA将设计简化为单个嵌入层和自回归Transformer预测器。如对比图所示,该架构精简保留了潜在预测目标,同时消除了辅助分支和头。  # 实验 - 核心算法组件消融:因果掩码在50k预训练步后于ImageNet-1K达到76.8% top-1准确率,优于双向注意力(73.6%);停止梯度防止表征坍缩;自回归移位对收敛至关重要。 - 架构组件评估:RoPE显著提升top-1准确率;LayerScale稳定预训练但需在微调期间冻结图像块嵌入以缓解轻微准确率下降;QK-Norm使SwiGLU训练稳定。 - ViT-B和ViT-L基础模型在ImageNet-1K分类中分别达到83.8%和85.3% top-1准确率,与MAE和BEiT相当,且无需任务特定头或重建目标。 - 使用UPerNet头在ADE20K语义分割中,基础模型和大模型分别达到48.3%和54.0% mIoU,证明从嵌入级预训练有效迁移至密集预测任务。 - 注意力分析揭示长距离、以对象为中心的模式:查询关注语义相关区域;嵌入相似度图显示对象部件内高度相关,证实无显式监督下的语义组织。 作者采用无解码器或辅助损失的自回归下嵌入预测框架,在基础模型和大模型上分别于ImageNet-1K实现83.8%和85.3% top-1准确率。结果表明,尽管仅使用单次前向传播且无重建目标,NEPA仍匹配或超越MAE和BEiT等先前方法。模型性能随RoPE和QK-Norm等架构增强而提升,且无需任务特定头即可有效迁移至下游任务。 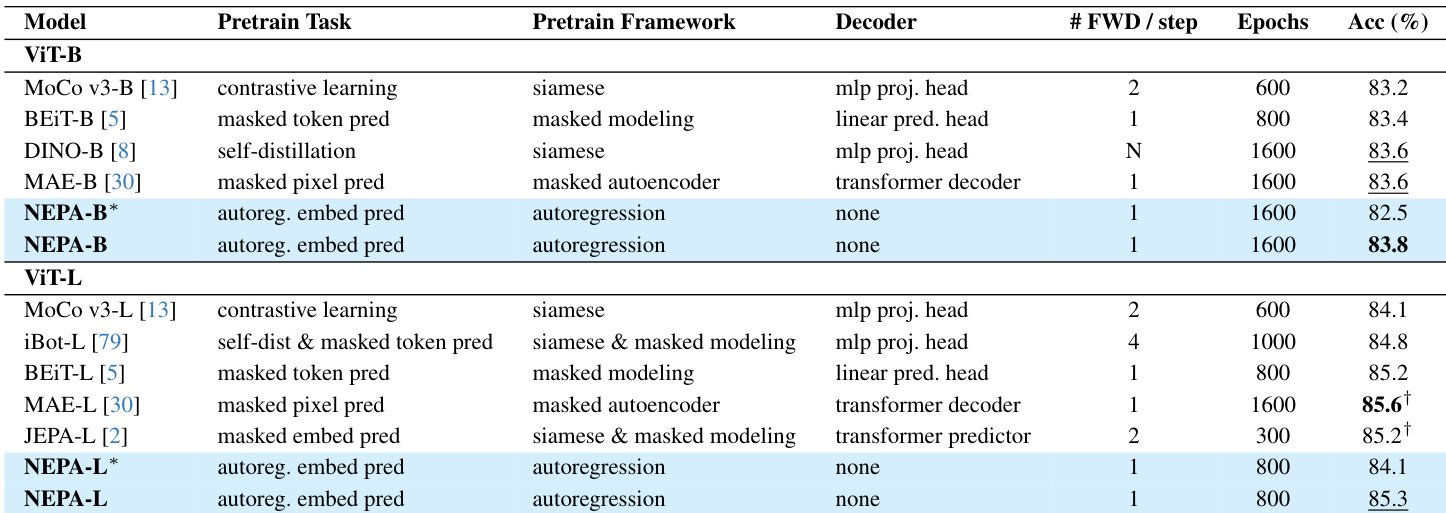 作者评估微调期间分层学习率衰减策略的影响,发现将衰减率从0.35线性增至1.00可使top-1准确率从83.0%提升至83.8%,优于固定衰减率0.65。该自适应策略通过逐步解冻深层网络减少过拟合,实现更稳定收敛。  作者评估随机输入嵌入掩码对预训练性能的影响,发现增加掩码比例会降低100k步后的top-1准确率:0%掩码得78.2%,40%得76.4%,60%得75.7%。这表明与像素级掩码建模不同,嵌入级随机掩码会破坏自回归预测信号,对该框架无益。  作者使用ADE20K和UPerNet解码器评估NEPA在语义分割上的表现,报告ViT-B和ViT-L在ImageNet-1K预训练后mIoU分别为48.3和54.0。结果表明NEPA优于MoCo v3和BEiT等监督与对比基线,且匹配或超越MAE,尽管未使用像素重建或辅助损失。优异性能证实仅靠下嵌入预测即可有效迁移至密集预测任务。 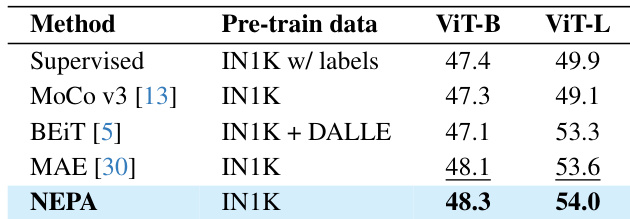 作者评估向MAE基线添加LayerScale、RoPE和QK-Norm的影响,发现在此设置下这些组件对top-1准确率无显著提升。结果表明MAE的掩码重建目标对这些架构增强不敏感,而这些组件在NEPA等自回归框架中更有效。 