Command Palette
Search for a command to run...
炼金术师:通过元梯度数据选择解锁文本到图像模型训练的效率
炼金术师:通过元梯度数据选择解锁文本到图像模型训练的效率
Kaixin Ding Yang Zhou Xi Chen Miao Yang Jiarong Ou Rui Chen Xin Tao Hengshuang Zhao
摘要
近年来,以Imagen、Stable Diffusion和FLUX为代表的文本到图像(Text-to-Image, T2I)生成模型在视觉质量方面取得了显著进展。然而,其性能在根本上受限于训练数据的质量。网络爬取和合成图像数据集通常包含大量低质量或冗余样本,导致视觉保真度下降、训练过程不稳定以及计算效率低下。因此,有效的数据筛选对于提升数据利用效率至关重要。现有方法主要依赖成本高昂的手动数据整理,或基于文本到图像数据中单一维度特征的启发式评分策略。尽管元学习方法已在大语言模型(LLM)领域得到探索,但尚未有适用于图像模态的适配方案。为此,我们提出Alchemist——一种基于元梯度的框架,用于从大规模文本-图像数据对中自动筛选出合适的子集。该方法通过从数据中心视角迭代优化模型,自动学习评估每个样本对模型性能的影响。Alchemist包含两个核心阶段:数据评分与数据剪枝。我们训练一个轻量级评分器,基于梯度信息并结合多粒度感知能力,估计每个样本的影响力;随后采用Shift-Gsampling策略,高效选取具有信息量的子集以支持模型训练。Alchemist是首个面向文本到图像模型训练的自动、可扩展、基于元梯度的数据选择框架。在合成数据集与网络爬取数据集上的实验结果表明,Alchemist能持续提升生成图像的视觉质量与下游任务性能。在仅使用Alchemist筛选出的50%数据进行训练的情况下,其效果已超越使用完整数据集的训练结果。
一句话总结
香港大学、华南理工大学与快手科技Kling团队的研究人员提出Alchemist,一种基于元梯度的高效文本到图像训练框架,可自动筛选高影响力数据子集。不同于以往的启发式或人工方法,该框架采用具备多粒度感知能力的梯度感知评分器和优化采样策略识别有效样本,使仅使用50%经Alchemist筛选数据训练的模型在视觉保真度和效率上均超越全量数据集训练效果。
核心贡献
- Stable Diffusion等文本到图像模型因网络爬取训练数据中存在低质量或冗余样本,导致视觉保真度下降和训练不稳定;现有数据选择方法依赖高成本人工筛选或单一维度启发式规则,无法优化下游模型性能。
- Alchemist引入基于元梯度的框架,通过梯度感知的多粒度评分机制自动评估数据样本,并采用偏移高斯采样策略优先选择中后段评分样本——此类样本具有更丰富的梯度动态特性,可避免因过度依赖高评分简单样本导致的过拟合。
- 在合成数据集与网络爬取数据集上的验证表明,Alchemist筛选的子集(如50%数据量)在视觉质量和模型性能上持续超越全量数据训练效果,实证显示最优数据分布于中后段评分区间,能有效平衡可学习性与多样性。
引言
作者针对文本到图像(T2I)模型训练中的数据选择问题展开研究,高效识别大规模数据集中高质量文本-图像对对降低计算成本、提升模型性能至关重要。现有方法通常采用Top-K剪枝策略——仅保留最高评分样本——但这往往导致快速过拟合,因顶级样本多为梯度变化微小的无信息样本,而动态价值更高的中后段数据却被常规方法舍弃。作者证明:高评分样本在训练中梯度变化极小,对学习贡献有限;中后段样本虽驱动有效模型更新却被传统方法丢弃。其核心创新在于基于剪枝的偏移高斯采样(Shift-Gsample)策略:首先舍弃前n%样本避免过拟合,再对中后段百分位区间应用高斯采样以平衡数据信息量与多样性。该方法选择性保留细节丰富且可学习的样本,过滤简单或混乱数据,通过契合人类直觉实现鲁棒的T2I训练。
方法
作者提出基于元梯度的Alchemist框架,通过自动筛选大规模文本-图像对中的高价值子集,实现文本到图像(T2I)模型的数据高效训练。整体流程包含两个核心阶段:数据评分与数据剪枝,共同构成可扩展、模型感知的数据筛选系统。工作流概览请参考框架示意图。
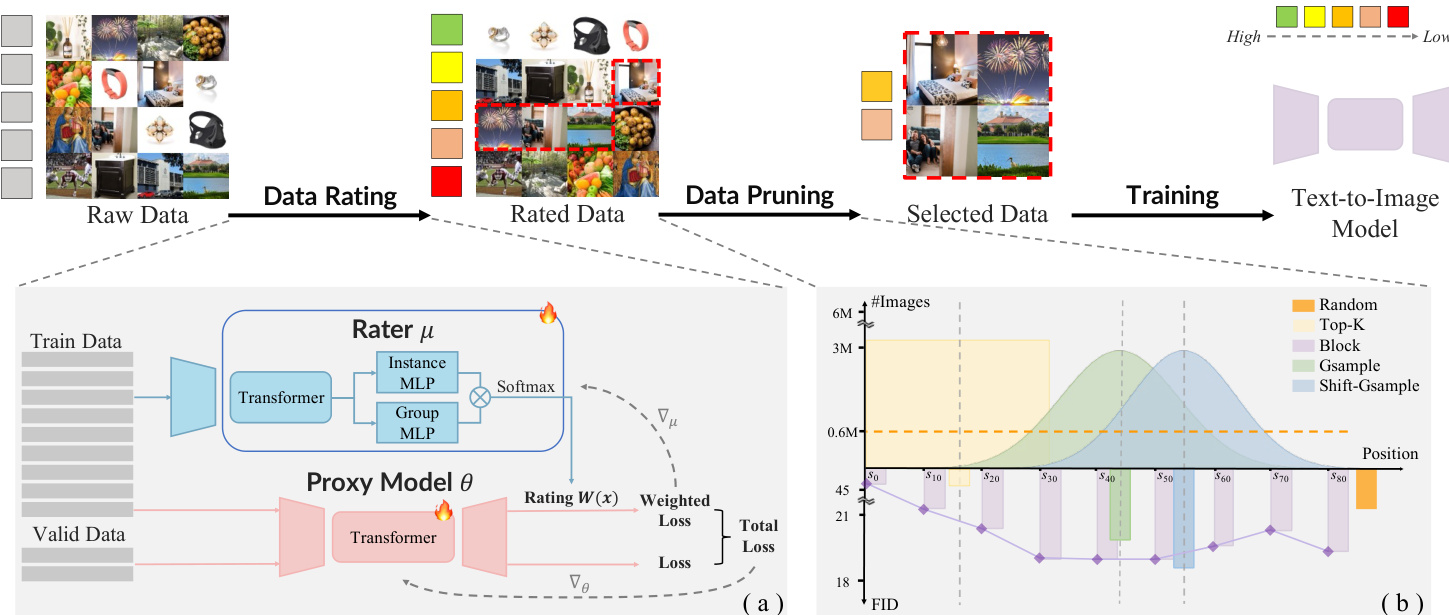
在数据评分阶段,使用轻量级评分网络(参数为μ)为每个训练样本xi分配连续权重Wxi(μ)∈[0,1],该权重反映样本对下游模型验证性能的影响。评分器通过双层优化训练:内层循环使用加权损失更新代理T2I模型θ,外层循环调整μ以最小化验证损失。为避免完整内层优化的计算负担,作者采用元梯度近似。训练时先用标准训练数据预热参考代理模型θ^,再用验证梯度与加权训练梯度联合更新主模型θ:
θk+1=θk−βk(gval(θk)+gtrain(θk,μk))其中gtrain(θk,μk)=∑xi∈DtrainWxi(μk)∇θL(θk;xi)。评分器参数通过主模型与参考模型的损失差异推导近似梯度更新:
μk+1=μk−αkL(θk;xi)∇μWxi(μk)为稳定训练,权重通过批次内softmax归一化:
Wxi=∑jexp(W^xj)exp(W^xi)为应对批次级波动并增强鲁棒性,评分器引入多粒度感知机制:包含两个并行MLP模块——处理单样本特征的实例MLP,以及通过批次统计量(均值与方差)计算批次级权重的组MLP。每个样本的最终权重为实例权重与批次权重的乘积,使评分器同时捕捉局部独特性与全局上下文。
在数据剪枝阶段,作者提出Shift-Gsample策略筛选评分数据子集。该策略优先选择评分分布中后段区域的样本——既非过于简单(梯度影响低)也非过于困难(离群值或噪声),但具有充分信息量且可学习。如下图所示,该方法在样本数量与下游FID性能上均优于随机采样、Top-K选择及分块方法。
筛选后的数据集用于训练目标T2I模型,在显著减少训练样本(通常仅需原始语料50%)的同时实现相当或更优性能,并加速收敛、提升视觉保真度.
实验
- Alchemist数据选择:50%子集在MJHQ-30K和GenEval基准上匹配全量数据性能,超越随机采样
- 20% Alchemist筛选数据匹配50%随机数据性能,证明显著的数据效率提升
- 在20%保留率下训练加速2.33倍,50%保留率下加速5倍,同时匹配随机采样结果
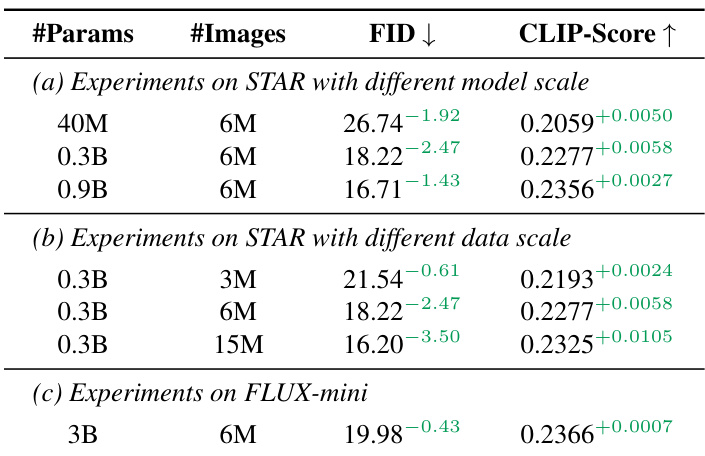
- 在STAR(从头训练)和FLUX-mini(LoRA微调)模型上持续超越基线
- 在HPDv3-2M和Flux-reason-6M数据集上泛化良好,20%和50%保留率下均超越随机选择
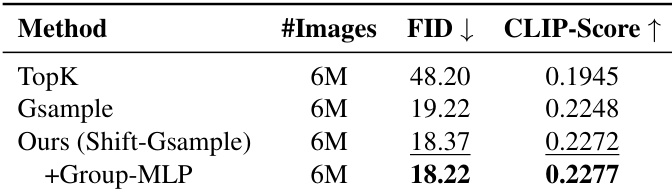
作者采用带组MLP的Shift-Gsample剪枝策略筛选有效数据,在600万图像-文本对上实现最低FID与最高CLIP-Score。结果表明:相比仅样本级选择,引入组级信息进一步提升性能。
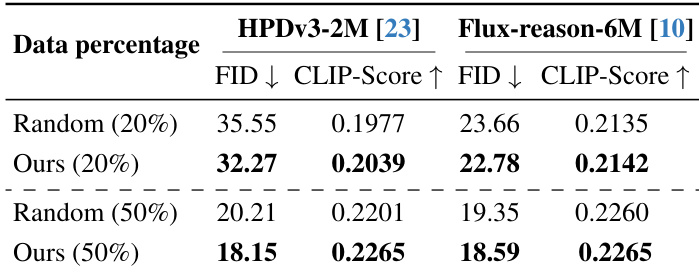
作者使用Alchemist筛选HPDv3-2M和Flux-reason-6M数据集子集,在20%和50%保留率下均获得低于随机采样的FID与更高CLIP-Score。结果证明:即使数据量减半,Alchemist筛选子集仍优于随机选择,确认其在不同数据域的有效性。
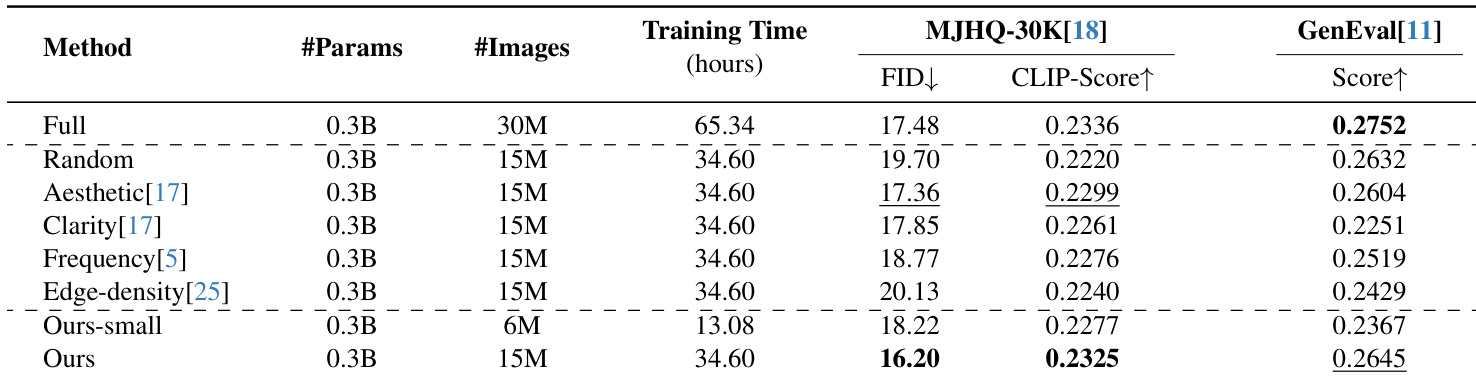
作者使用Alchemist筛选LAION数据集50%子集,在匹配全量训练时间的前提下获得更优FID与CLIP-Score。结果表明:更小的20%子集(Ours-small)在不足半数训练时间内仍超越多种基于启发式的筛选方法。Alchemist筛选数据在效率与性能上持续优于随机采样及其他图像质量指标。
作者使用Alchemist为STAR和FLUX-mini模型筛选训练数据,在不同模型规模与数据量下均展现持续性能增益。结果表明:600万Alchemist筛选图像相比更小或更大的随机子集均改善FID与CLIP-Score,30亿参数的FLUX-mini模型亦呈现类似增益。该方法具有可扩展性——更大规模模型及不同架构无需额外评分器训练即可受益于相同筛选数据。