LLMCache:面向Transformer推理中加速复用的分层缓存策略
LLMCache:面向Transformer推理中加速复用的分层缓存策略
Harsh Vardhan Bansal
Abstract
基于Transformer的语言模型在众多任务中取得了卓越的性能,但其较高的推理延迟给实时部署和大规模应用带来了显著挑战。尽管现有的缓存机制(如基于token级别的键值缓存)能够在自回归解码过程中提供加速,但其适用范围和场景仍较为有限。本文提出LLMCache,一种新型的分层缓存框架,通过基于输入序列语义相似性复用中间激活值,实现Transformer推理的加速。与以往工作不同,LLMCache具有模型无关性,适用于编码器与解码器架构,并支持在任意Transformer层进行缓存。我们设计了一种轻量级的指纹匹配机制,用于识别语义相似的输入,并提出了自适应淘汰策略以有效管理缓存老化问题。在BERT和GPT-2模型上,针对SQuAD、WikiText-103和OpenBookQA等多个基准任务的实验表明,LLMCache可实现最高达3.1倍的推理加速,且准确率下降低于0.5%。实验结果表明,LLMCache是一种切实可行且通用性强的解决方案,能够有效优化Transformer模型在真实应用场景中的推理效率。
一句话总结
亚马逊云科技的 Harsh Vardhan Bansal 提出 LLMCache——一种与模型无关的层级缓存框架,通过基于语义相似度匹配重用中间激活值来加速 Transformer 推理。与仅适用于解码器架构的 Token 级键值缓存不同,该框架支持编码器和解码器架构,并采用自适应驱逐策略,在聊天系统和文档处理流水线等实际应用中实现最高 3.1 倍加速,同时精度损失极小。
核心贡献
- Transformer 推理因语义相似输入的冗余计算导致高延迟,现有 Token 级缓存(如键值缓存)仅限于纯解码器架构,无法在编码器或编解码器模型中跨输入重用中间激活值。
- LLMCache 提出与模型无关的层级缓存框架,通过匹配基于语义相似度的输入指纹重用中间激活值,支持任意 Transformer 层级并采用自适应驱逐策略管理缓存陈旧性,无需重新训练模型。
- 在 SQuAD、WikiText-103 和 OpenBookQA 数据集上对 BERT 和 GPT-2 的实验表明,该方法在精度损失低于 0.5% 的条件下实现最高 3.1 倍推理加速,验证了其在对话代理和文档流水线等实际应用中的有效性。
引言
Transformer 推理延迟仍是大语言模型实时部署的关键障碍,尤其在对话式 AI 和文档处理等输入常具有语义或结构相似性的场景中。量化、剪枝或键值缓存等现有优化技术存在明显局限:量化和剪枝需重新训练或牺牲精度,而标准键值缓存仅能加速纯解码器模型的自回归解码,无法跨编码器或编解码器架构重用中间激活值。作者提出通过缓存中间激活值的层级缓存机制填补这一空白,LLMCace 作为与模型无关的框架,通过输入语义指纹识别并重用稳定表征,支持编码器和解码器模型,采用自适应驱逐管理缓存陈旧性,在问答和语言建模等任务中实现最高 3.1 倍推理加速且精度损失极小。
方法
作者构建模块化层级缓存框架,通过重用语义相似输入的中间激活值加速 Transformer 推理。该系统无需修改底层模型架构,兼容编码器和解码器模型,核心是语义指纹机制,支持在部分输入漂移下进行自适应匹配。
系统包含五大组件:输入指纹生成器、层级缓存库、缓存匹配查询引擎、层执行管理器和缓存刷新替换控制器。下图展示了这些组件如何在 Transformer 各层交互运作。
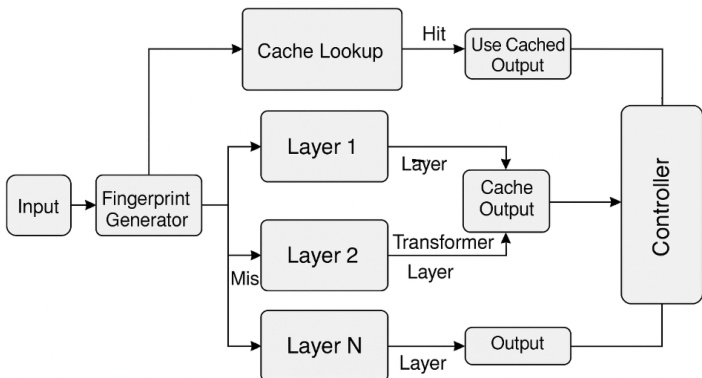
推理流程始于输入指纹生成器,其为输入序列 X={x1,x2,…,xn} 生成固定长度语义指纹 fX。该指纹源自聚合的 Token 嵌入(可选结合注意力统计量),通过 SimHash 或 PCA 压缩以确保高效比对。指纹作为缓存查询键,根据哈希方案采用余弦相似度或 Jaccard 指数进行比对。
每个 Transformer 层 l 维护独立缓存库 Cl,存储 (f,hl) 元组(f 为指纹,hl 为对应隐藏状态输出)。推理时,缓存匹配查询引擎在 Cl 中查找满足 sim(fX,f′)≥τ 的指纹 f′(τ 为可调相似度阈值)。若匹配成功则重用缓存激活值 hl;否则正常计算该层并将结果存入缓存。
层执行管理器作为动态决策门,在 Transformer 前向传播中无缝集成,为每层选择缓存重用或完整计算。该机制通过 PyTorch 模块钩子或子类重写实现,保持与现有模型实现的兼容性。
如下图所示,推理流程逐层推进,每层基于缓存查询结果独立决定重用或重算。这种层级粒度避免了 Token 级键值缓存的开销,并实现重用行为的细粒度控制。
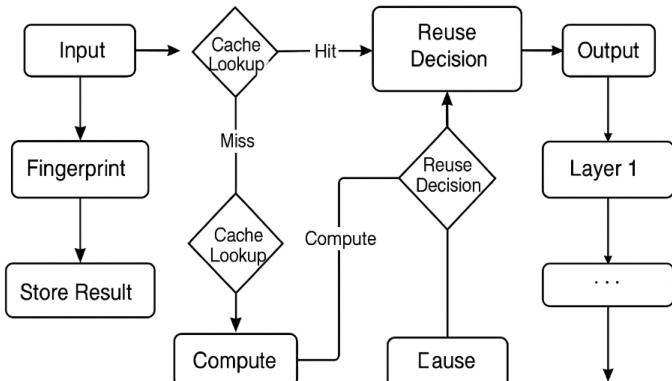
为维持缓存效率并防止内存膨胀,缓存刷新替换控制器采用最近最少使用(LRU)、陈旧感知衰减和发散监控等驱逐策略。通过跟踪单次推理调用中给定指纹的输出漂移测量发散度,当性能下降时触发重新验证。时间衰减因子进一步确保过期条目随时间清除。
整体推理过程形式化为:
hl={Cl[fX]fl(hl−1)if sim(fX,f′)>τotherwise其中 Cl 为第 l 层缓存,f′ 为现有指纹键,τ 控制重用率与语义保真度的权衡。系统允许调节 τ、缓存大小和层选择,以平衡不同应用场景的速度与精度.
实验
- 在 WikiText-103、SQuAD v2 和 OpenBookQA 上,BERT-base 实现 2.4 倍延迟降低,整体最高达 3.1 倍(相比无缓存),且在 GPT-2 上优于键值缓存
- GPT-2 WikiText-103 的低/中层 Transformer 层缓存命中率最高达 92%,上层对语义变化更敏感
- 所有基准测试中任务精度下降控制在 0.5% 以内,得益于更细粒度的层控制,鲁棒性优于 DocCache
- 通过 BERT-base 实验验证的高效指纹机制,实现对数级开销增长的灵活内存-命中率权衡
- 消融实验确定最优相似度阈值(τ)在 0.82 至 0.88 之间,平衡重用频率与输出保真度
作者使用 LLMCache 通过重用中间表征加速 Transformer 推理,在 BERT-base、DistilBERT 和 GPT-2-small 上实现显著延迟降低。结果表明:相比无缓存方案,LLMCace 最高降低 2.4 倍推理时间;在 GPT-2 上优于键值缓存,证明细粒度重用可获得更大加速比。所有模型均保持高效率且精度损失极小,验证了该方法在实时应用中的实用性。

结果显示:LLMCace 在所有评估数据集上维持任务精度与基线差异在 0.5% 以内,同时在保持保真度方面优于 DocCache。作者借此验证了其层级缓存方法的语义稳定性。

Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.