Command Palette
Search for a command to run...
OPENTOUCH:将全手触觉带入现实世界交互
OPENTOUCH:将全手触觉带入现实世界交互
摘要
人类的手是我们与物理世界交互的主要接口,然而,从第一人称视角出发的感知系统往往无法准确识别接触发生的时间、位置或力度。目前,性能可靠的可穿戴触觉传感器仍十分稀缺,且尚无现有的野外数据集能够实现第一人称视频与全手触觉信息的精准对齐。为弥合视觉感知与物理交互之间的鸿沟,我们提出了 OpenTouch——首个面向野外场景的第一人称全手触觉数据集。该数据集包含5.1小时同步的视频-触觉-姿态数据,以及2,900段经过精心标注的视频片段,配有详尽的文本注释。基于 OpenTouch,我们构建了检索与分类基准任务,用以探究触觉如何赋予感知与行为以现实基础。实验表明,触觉信号虽信息紧凑,却具有强大的表征能力,能够有效提升对抓握行为的理解,增强跨模态对齐效果,并可从野外视频查询中可靠地检索出对应的触觉信息。通过公开这一标注完善的视觉-触觉-姿态数据集及基准评测体系,我们旨在推动多模态第一人称感知、具身学习以及高接触密度的机器人操作技术的发展。
一句话总结
麻省理工学院、哈佛大学、杜克大学等机构的研究人员推出了 OPENTouch——首个野外环境下同步采集第一人称视频、力觉感知全手触觉传感与手部姿态轨迹的数据集。不同于以往实验室数据集,它能捕捉仅凭视觉无法区分的自然接触力,提供 5.1 小时交互数据及基准测试,通过基于触觉的检索与分类推动多模态感知和触觉丰富的机器人操作技术发展。
核心贡献
- OPENTouch 解决了野外第一人称数据集中视频、全手触觉接触与姿态对齐的关键缺失问题,首次提供包含 5.1 小时同步视频-触觉-姿态数据及 2,900 个精细标注片段的资源,标注包含详细文本描述。
- 该研究建立了新型跨感官检索与触觉模式分类基准,特别是手部动作识别和抓握类型识别任务,严格评估触觉信号如何消除交互歧义并增强跨模态对齐以理解抓握。
- 基于柔性印刷电路板(FPCB)技术定制的轻薄低成本开源触觉手套实现了该数据集,通过在压阻薄膜上自动布设电极,为掌面提供均匀的 169 传感器覆盖,实现在日常环境中的稳定高分辨率压力映射。
引言
作者针对机器人操作中触觉与视觉、姿态数据融合的挑战展开研究:当视觉数据无法解析动作和抓握时,触觉能提供关键歧义消除能力。现有触觉编码方法仅聚焦于通过轻量级 CNN 处理压阻传感器信号,或通过预训练 ResNet 处理触觉图像,缺乏标准化多模态基准来评估触觉如何具体提升动作与抓握理解能力。本研究提出两种新型触觉模式分类任务——手部动作识别与抓握类型识别,联合利用第一人称视频、触觉信号和手部姿态,建立明确指标与数据划分方案,量化触觉在消除交互歧义中的作用,为机器人策略学习等应用提供支持。
数据集
作者采用 OPENTouch——首个野外环境下捕获同步全手触觉信号、第一人称视频及手部姿态轨迹的数据集。关键细节如下:
-
组成与来源:
- 来自 14 种日常环境(如车间、厨房)的 5.1 小时录制数据,涵盖 14 类超 8,000 个物体。
- 数据源包括 Meta Aria 眼镜(30 Hz 下 1408×1408 RGB 视频)、Rokoko Smartgloves(30 Hz 下基于 IMU/EMF 传感器的手部姿态)及定制 FPC 触觉手套(力觉感知全手触觉)。
- 包含 2,900 个人工审核片段(≈3 小时)及密集标注,另含头部运动、眼动追踪和音频数据。
-
子集细节:
- 标注片段(2,900 个):筛选触觉丰富的交互,通过 GPT-5 基于每片段压力采样帧(接近、峰值力、释放)生成标注,人工验证准确率达 90%。标注涵盖物体名称/类别、环境、动作、抓握类型(来自 GRASP 分类法的 29 种)及自然语言描述。
- 原始录制(5.1 小时):非脚本化交互;仅主导手配备传感器,左手数据通过镜像泛化。
-
论文中的数据使用:
- 训练聚焦跨感官检索(如视频→触觉)和触觉抓握分类基准。
- 模态以三模态组合(视频、姿态、触觉)混合,消融实验测试时间窗口大小(如 2 秒窗口)和触觉离散化。
- 2,900 个标注片段构成核心基准;原始数据支持从野外视频(如 Ego4D)进行触觉检索。
-
处理细节:
- 同步:通过 ESP-NOW 无线传输和零电位读出电路实现 30 Hz 硬件对齐,延迟 <2 ms。
- 触觉图按抓握类型聚合以验证空间压力模式。
- 元数据基于压力动态帧采样的 LLM 生成标注构建,避免全视频处理。
- 无空间裁剪;时间采样基于力动态聚焦关键交互阶段。
方法
作者采用多模态感知与编码框架捕获并对齐第一人称视觉、触觉和手部姿态数据,用于细粒度人-物交互分析。系统通过集成 Meta Aria 眼镜(第一人称视频)、Rokoko Smartgloves(手部姿态追踪)及嵌入定制 FPC 触觉传感器的手套(全手压力映射)实现硬件配置,同步获取三种互补模态数据,并通过专用编码器处理生成共享潜在空间中的对齐嵌入。
参考框架图了解数据流水线概览。视觉编码器采用冻结的 DINOv3 ViT-B/16 主干网络提取每帧语义特征,通过均值池化进行时间聚合后投影至共享嵌入空间。触觉编码器将 16×16 压力图序列视为单通道视频流,应用带 5×5 卷积核和 2×2 最大池化的三层 CNN 提取空间特征,再通过双向 GRU 建模时间动态;最终触觉表示通过拼接前向与后向隐藏状态并线性投影形成。姿态编码器处理每帧 21 个 3D 手部关键点,应用几何归一化确保平移和尺度不变性,再经四层 MLP 和自适应时间平均池化生成紧凑姿态嵌入。
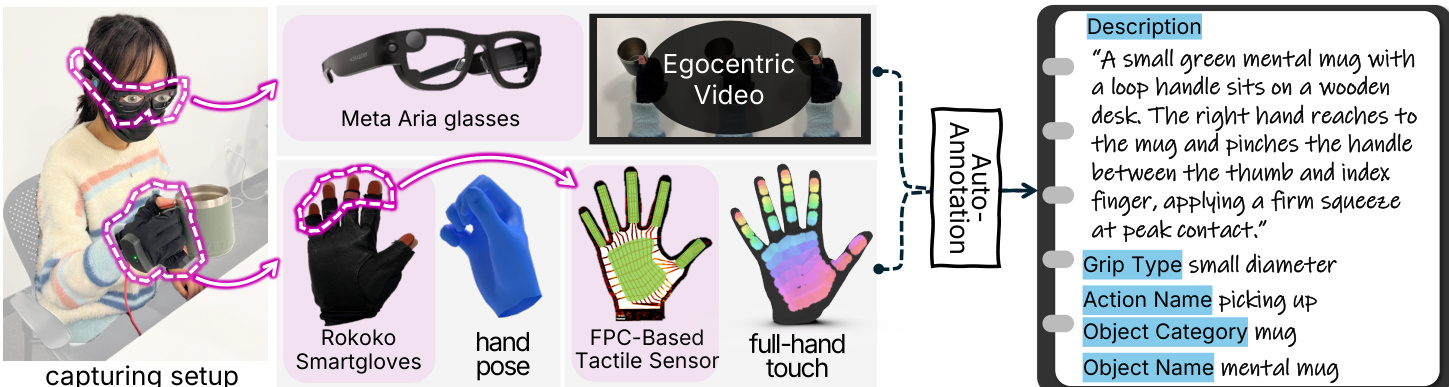
为实现跨模态对齐,作者同时实现线性与深度检索方法。在深度方法中,各模态嵌入经 L2 归一化后投影至 64 维空间。对匹配模态对 (v↔t) 和 (t↔p) 应用对称 InfoNCE 损失(温度 τ=0.07)以最大化一致性。对于 (v+p↔t) 等多模态查询,嵌入通过线性头 ϕ(⋅) 融合后再应用相同对比目标。模型使用 Adam 优化器训练 300 轮,初始学习率 1×10−4 采用余弦退火策略,批次大小为 256。
针对下游分类任务(特别是动作识别与抓握类型预测),作者在融合嵌入上附加轻量级线性分类头。每个分类器处理 10 帧序列,将生成的单一融合嵌入经全连接层和 softmax 输出。训练采用交叉熵损失,Adam 优化器学习率 1×10−4,批次大小 64。整个流水线通过结合密集触觉反馈与视觉及运动学上下文,实现对手-物交互的可扩展细粒度标注。
实验
- 跨感官检索实验验证了视觉、触觉与姿态模态间的共享表征学习。在双模态任务中,对比模型在 Video→Tactile 和 Tactile→Pose 上达到 7.15% Recall@1,显著优于线性基线(CCA/PLSCA ≤0.57% Recall@1),证明其有效对齐动态交互线索。
- 多模态融合持续提升检索性能:Video+Pose→Tactile 达 26.86% mAP,Tactile+Vision→Pose 同样达 26.86% mAP,证实跨模态互补信息可降低歧义。
- 触觉模式分类显示:仅触觉输入抓握准确率达 60.23%,而 Vision+Tactile 融合在抓握(57.45%)和动作识别(40.26%)中表现最优,凸显模态特异性优势。
- 消融实验表明:20 帧时间窗口最大化检索性能(如 Video→Tactile Recall@1 从 5.77% 升至 8.49%),轻量级触觉编码器比 ResNet-18 高 10.49% mAP,原始/5-7 级离散化触觉输入提供最优抗噪表征。
- 迁移到 Ego4D 的零样本泛化实验证明:从视频查询中检索语义一致触觉特征的成功性,验证跨数据集适用性。
作者评估不同时间窗口大小下的跨感官检索性能,发现更长窗口持续提升结果,Window=20 在多数任务中取得最高 Recall@1 和 mAP。多模态设置(如 Video+Pose→Tactile)中性能增益尤为显著,mAP 从 Window=5 的 19.89% 升至 Window=20 的 24.46%,表明建模更长时间动态可增强跨模态对齐。结果证实时间上下文对捕捉触觉与视觉交互信号的演化特性至关重要。
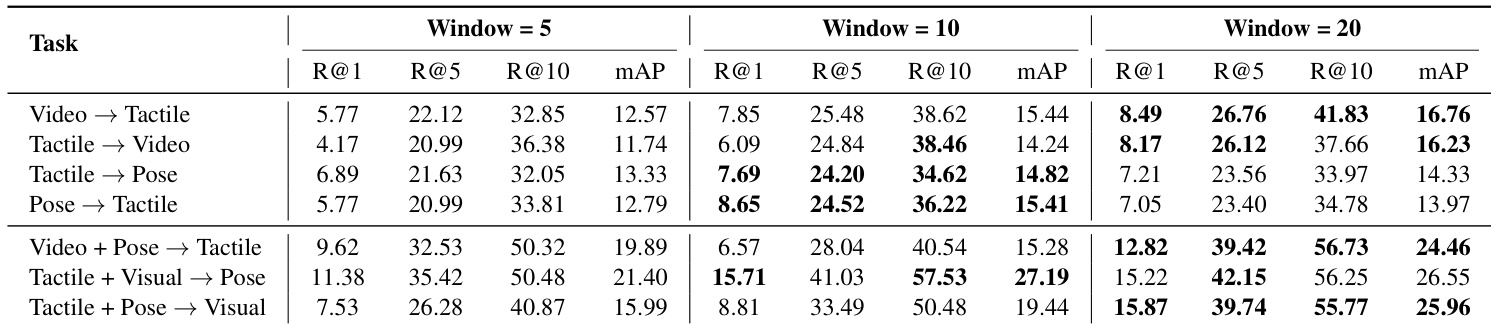
作者评估不同感官模态和编码器下的动作与抓握分类,发现触觉信号对抓握类型预测最具信息量,而融合视觉、姿态与触觉线索可获得最高抓握准确率。视觉单独对两项任务表现尚可,且触觉加入视觉后性能持续提升(尤其使用轻量级 Lite-CNN 编码器时)。T+P+V 三模态组合配合 Lite-CNN 以 68.09% 抓握准确率取得最佳效果。
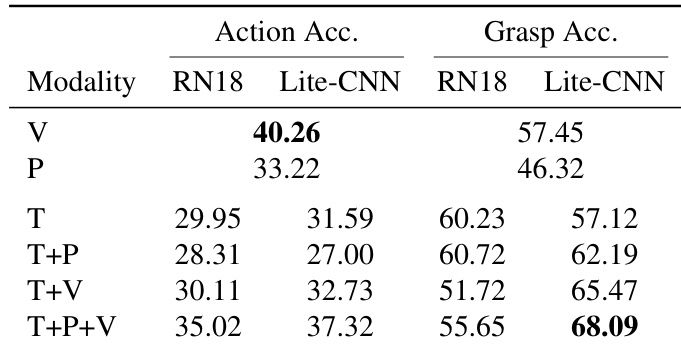
作者采用对比学习框架将视频、姿态与触觉模态对齐至共享嵌入空间,实现跨模态检索。结果显示:该方法在所有多模态检索任务中大幅优于 CCA 和 PLSCA 等线性基线,Recall@1 和 mAP 提升显著——例如 video+pose→tactile 检索达到 14.08% R@1 和 26.86% mAP。所有融合方向的持续增益表明:模态组合提供互补信息,可降低歧义并增强跨模态对齐。

作者评估触觉信号离散化策略在双/三模态检索任务中的表现,对比对数、线性和原始连续表示。结果显示:原始连续触觉输入在多数设置中 consistently 取得最高 mAP,中等范围离散化(5-7 级)表现具有竞争力,表明离散化可作为有效正则化手段而不显著降低对齐性能。性能趋势证实:触觉信号受益于保留原生连续结构,而非强制转换为粗粒度或变换表示。
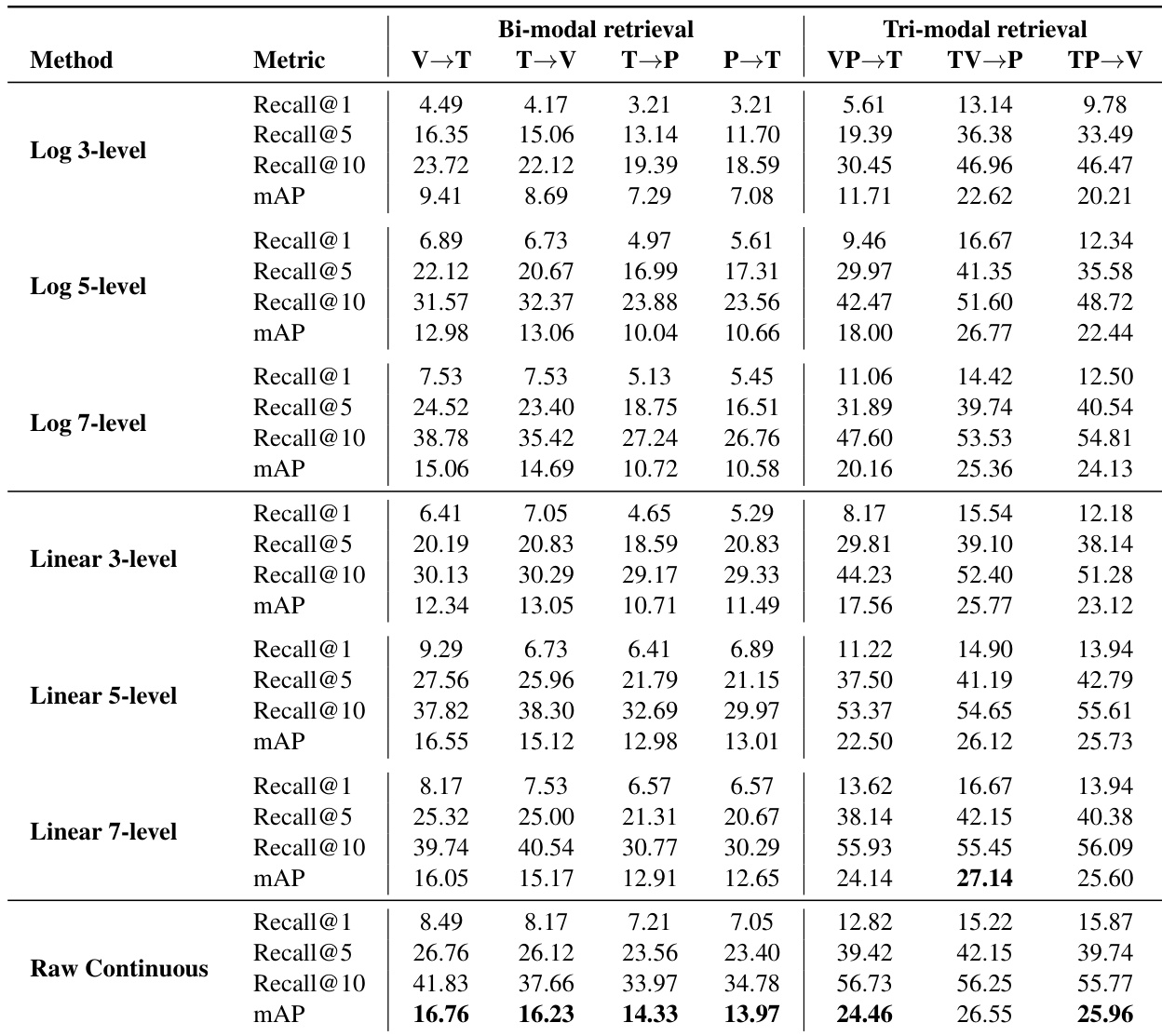
作者采用对比学习框架将视频、触觉与姿态模态对齐至共享嵌入空间,在所有跨模态检索任务中显著优于 CCA 和 PLSCA 等线性基线。Recall@1、Recall@5、Recall@10 和 mAP 指标均持续提升,其中触觉→姿态与姿态→触觉方向改进最大,表明模型有效捕捉手部运动与接触模式间的几何耦合。多模态输入进一步提升性能,证明视频、姿态与触觉线索为鲁棒跨感官对齐提供互补信息。
