Command Palette
Search for a command to run...
DataFlow:一种面向以数据为中心的人工智能时代的统一数据准备与工作流自动化框架
DataFlow:一种面向以数据为中心的人工智能时代的统一数据准备与工作流自动化框架
摘要
大型语言模型(LLMs)对高质量数据日益增长的需求,加剧了对可扩展、可靠且语义丰富的数据准备流程的迫切需求。然而,当前实践仍主要依赖于临时编写的脚本和缺乏明确定义的工作流,这些方法缺乏系统性的抽象,阻碍了结果的可复现性,并在“模型驱动的数据生成”方面支持有限。为应对这些挑战,我们提出 DataFlow——一个统一且可扩展的、由大语言模型驱动的数据准备框架。DataFlow 采用系统级抽象设计,支持模块化、可复用且可组合的数据转换操作,并提供类似 PyTorch 风格的流水线构建 API,便于构建可调试、可优化的数据处理流程。该框架包含近 200 个可复用的操作符,以及覆盖文本、数学推理、代码生成、文本到 SQL、智能体式 RAG(检索增强生成)和大规模知识提取六个通用领域的端到端数据流水线。为进一步提升易用性,我们引入 DataFlow-Agent,该组件能够通过操作符合成、流水线规划与迭代验证,自动将自然语言描述转化为可执行的数据流水线。在六个代表性应用场景中,DataFlow 均显著提升了下游大语言模型的性能。其数学、代码和文本处理流水线的表现超越了人工精心构建的数据集及专用的合成基准数据集,在 Text-to-SQL 任务上相较 SynSQL 提升最高达 +3% 的执行准确率;在代码基准测试中平均提升达 +7%;在 MATH、GSM8K 和 AIME 等评测集上分别取得 1–3 个百分点的性能增益。此外,由 DataFlow 生成的统一 10K 样本数据集,已使基础模型性能超越在 100 万条 Infinity-Instruct 数据上训练的同类模型。这些结果表明,DataFlow 为可靠、可复现且可扩展的大语言模型数据准备提供了高效实用的底层支撑,并为未来以数据为中心的人工智能发展奠定了系统级基础。
一句话总结
北京大学、上海人工智能实验室与LLaMA-Factory团队提出DataFlow——一个统一的LLM驱动数据准备框架,具备系统级抽象、PyTorch风格API及跨六大领域的近200个可复用操作符。其DataFlow-Agent能将自然语言规范转化为可执行流水线,在提升LLM性能的同时,通过语义丰富的合成与精炼,使小数据集训练效果超越百万样本模型。
核心贡献
- 当前LLM数据准备依赖缺乏可复现性且不支持模型在环的临时脚本,而Apache Spark等大数据框架难以高效处理非结构化数据的语义文本操作。DataFlow通过模块化可复用操作符、支持调试的PyTorch风格API,以及基于操作符合成的自然语言到流水线转换(DataFlow-Agent)解决此问题。
- 框架集成近200个操作符及六大通用领域流水线(文本、数学、代码、Text-to-SQL、代理RAG、知识提取),支持模型在环处理与GPU高效批处理,克服传统ETL系统在词元级操作和语义清洗方面的局限。
- 在六类用例评估中,DataFlow流水线性能超越人工构建数据集与专用基线:Text-to-SQL准确率较SynSQL提升+3%,代码基准平均增益+7%,MATH/GSM8K/AIME提升1–3分。其生成的统一10K样本数据集使基础模型性能超越百万样本Infinity-Instruct训练结果。
引言
大语言模型规模的持续扩大对高质量多样化训练数据提出更高要求,低质数据或有限多样性会直接损害模型泛化能力并放大分布偏差。现有数据准备依赖临时脚本或Spark等大数据框架,缺乏对语义操作、模型在环处理及非结构化文本转换的原生支持,迫使关键步骤(如去重、安全过滤)手动实现且可复现性差。作者提出DataFlow统一框架,包含模块化数据转换的系统级抽象、PyTorch风格API及跨六大领域的近200个可复用操作符,并开发DataFlow-Agent实现自然语言规范到流水线的自动生成。六类任务评估表明,DataFlow持续提升LLM性能——在代码基准上以+7%增益超越人工数据集,且其10K样本输出训练的基础模型性能超越百万样本的前沿方法,为数据驱动AI建立可复现的规模化基础。
数据集
作者基于DATAFLOW框架构建多任务推理的领域合成数据集,关键子集详情如下:
-
数学推理 (DATAFLOW-REASONING-10K)
- 规模/来源:基于NuminaMath种子数据集生成10K样本
- 过滤:通过MathQ-Verify验证候选问题排除错误/模糊条目;使用DeepSeek-R1生成思维链轨迹
- 用途:微调Qwen2.5-32B-Instruct(1–2轮),对比Open-R1/Synthetic-1基线;在8项数学基准(如GSM8K、MATH)评估
- 处理:AIME问题使用temperature=0.6/top-k=20,其余temperature=0;省略种子预验证(NuminaMath预筛选)
-
代码生成 (DATAFLOW-CODE-1K/5K/10K)
- 规模/来源:从20K Ling-Coder-SFT种子生成1K–10K样本
- 过滤:流水线精炼高质量代码指令;对比Code Alpaca/SC2-Exec-Filter基线
- 用途:全参数SFT训练Qwen2.5-7B/14B-Instruct;在4项代码基准(如HumanEval、LiveCodeBench)评估
-
Text-to-SQL (DATAFLOW-TEXT2SQL-90K)
- 规模/来源:整合Spider-train (37.5K)、BIRD-train (37.5K)、EHRSQ-train (14.5K)共89.5K实例
- 过滤:确保SQL语法/语义多样性;含自然语言问题、SQL查询及思维链轨迹
- 用途:仅在合成数据上微调模型;通过贪婪解码或8样本多数投票在6项基准评估
-
代理RAG (DATAFLOW-AGENTICRAG-10K)
- 规模/来源:从Wikipedia生成10K多跳问题(排除测试基准文档)
- 过滤:验证模块剔除含逻辑错误、信息泄露或难度不当的样本
- 用途:使用GRPO RL训练Qwen2.5-7B-Instruct;E5-base-v2检索器(top-k=5);对比2WikiMultiHopQA/Musique评估
-
医学知识 (DATAFLOW-KNOWLEDGE)
- 规模/来源:医学教材(MedQA Books)、StatPearls文章(9.3K)及临床指南(45.7K)共140M词元
- 过滤:文本归一化(MinerU)、噪声过滤、事实感知QA合成
- 用途:微调Qwen2.5-7B-Instruct(37.5K步/5轮);在PubMedQA/Covert/PubHealth评估
-
多模态指令 (DATAFLOW-INSTRUCT-10K)
- 构成:混合10K语料库(3K数学、2K代码、5K通用指令)
- 来源:数学(MATH种子)、代码(LingoCoder SFT)、文本(Condor Generator + Refiner)
- 用途:全参数SFT训练Qwen2-7B/2.5-7B;对比Infinity-Instruct基线;在数学、代码及知识基准(MMLU/C-Eval)评估
方法
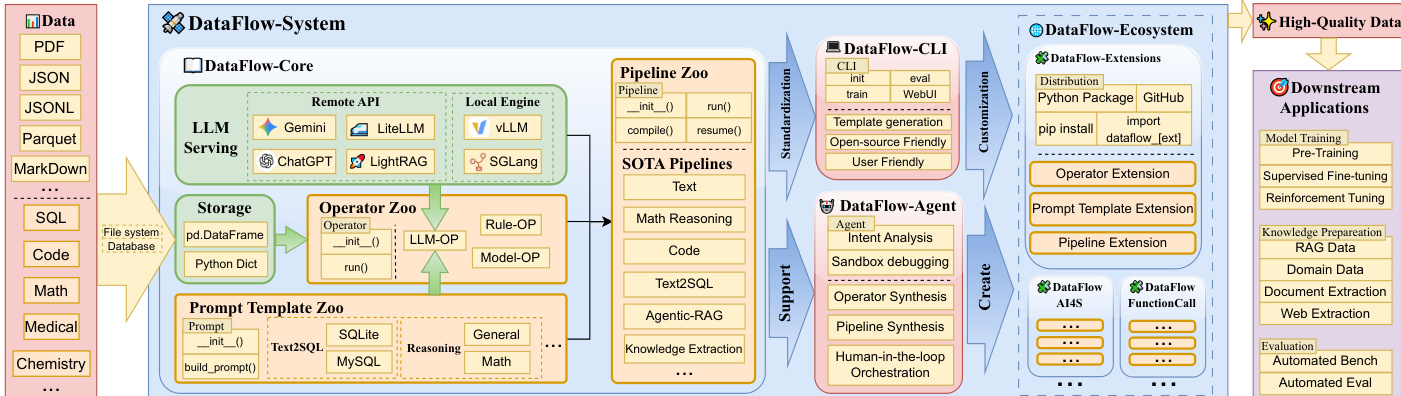
作者采用统一模块化架构标准化LLM驱动数据准备,以核心执行引擎和智能代理层为中心实现自动化流水线构建。系统设计强调可编程性、可扩展性及后端无关性,使用户能以最少样板代码编排、调试和优化数据工作流。
基础层DataFlow-Core提供存储、LLM服务、操作符及提示模板的抽象。存储层维护数据集的标准表格表示,解耦数据管理与转换逻辑。操作符通过最小化后端无关API(暴露read()/write()操作)与该层交互,确保中间产物立即可用。如操作符交互图所示,这种读-转换-写范式支持灵活组合与重排序而不修改操作符内部。默认存储实现使用Pandas,支持JSONL、Parquet、CSV等常见格式。
LLM驱动操作符依赖统一服务API抽象异构后端,包括vLLM/SGLang等本地推理引擎及ChatGPT/Gemini等在线API。服务接口提供单一入口generate_from_input(),接受提示词及system_prompt/json_schema等可选参数,支持结构化提示与解码。该抽象屏蔽了批处理、重试逻辑及速率限制等后端细节,便于灵活替换LLM引擎评估数据质量影响。
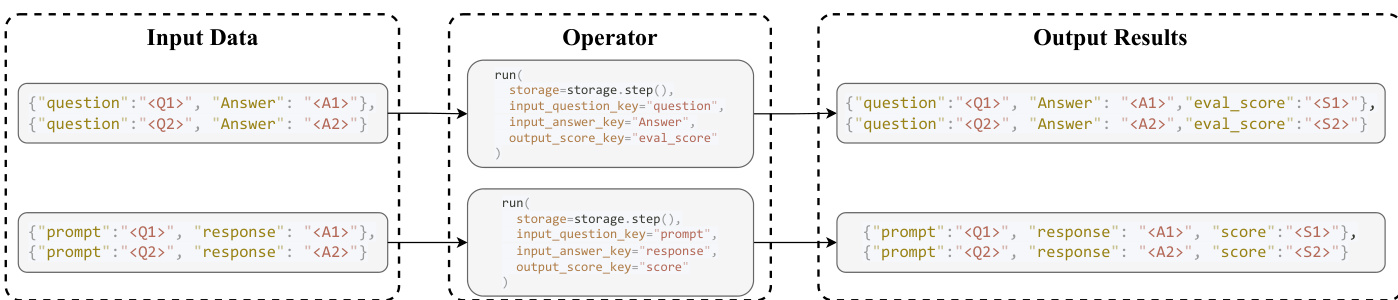
操作符作为基础转换单元,遵循两阶段接口:初始化(init())配置静态参数并绑定服务或提示模板对象,执行(run())完成转换。run()方法接收DataFlowStorage对象及基于键的绑定(input_和output_),使操作符适配多样化上游数据集。该设计形成操作符间的有向依赖图,支持拓扑调度与下游优化。框架沿三个正交维度分类操作符:模态(文本、视觉、文档)、核心/领域专用、功能(生成、评估、过滤、精炼)。此分类在概念紧凑性与领域扩展性间取得平衡,支持180+操作符按四类功能组织,支撑生成-评估-过滤-精炼范式。
流水线将操作符组合为多阶段工作流,表示为有序序列或轻量级DAG。流水线API采用PyTorch风格设计,init()处理资源分配,forward()编码执行逻辑。内置compile()过程在执行前进行静态分析,提取依赖、验证键级一致性并构建延迟执行计划。这支持检查点、分步恢复等高级运行时特性,提升迭代开发与大规模构建效率。
为自动化流水线构建,DataFlow-Agent层基于LangGraph编排多代理工作流。该代理将用户查询分解为子意图,检索或合成操作符,组装为DAG并在沙盒环境验证流水线。采用"检索-复用-合成"策略:优先通过提示模板复用现有操作符;检测功能缺口时使用基于RAG的少样本学习合成新代码;最终调试代码确保稳定执行。这使系统能无手动干预构建适应性流水线处理意外需求。

DataFlow-Ecosystem进一步支持框架扩展,允许用户将领域专用操作符、模板及流水线打包为Python模块分发。DataFlow-CLI为新扩展生成操作符/流水线模板,代理可按需合成调试新组件。该生态促进社区驱动增长,使实践者共享、复现并改进数据准备方案。
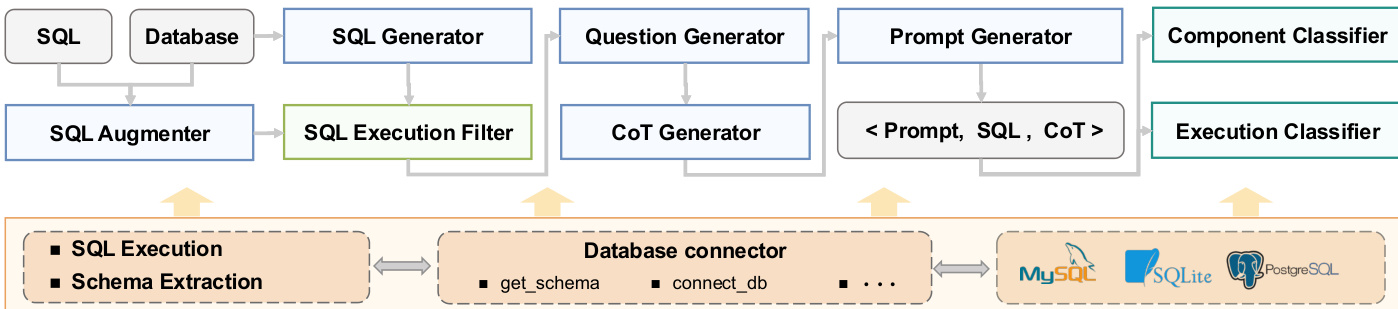
针对Text-to-SQL生成等特定任务,框架提供专用操作符及抽象底层数据库交互的数据库管理器模块。例如Text-to-SQL流水线包含SQL生成、增强、问题生成及思维链推理操作符,均通过统一提示模板接口编排,支持MySQL/SQLite/PostgreSQL等数据库复用。
生成的高质量任务对齐数据集无缝集成至下游LLM应用(模型训练、微调、评估)。框架设计确保数据准备不再是事后清洗步骤,而是通过迭代合成与精炼构建高语义密度语料库的一等公民可编程工作流。
实验
- 文本数据准备:DataFlow-30B预训练过滤在六项基准平均得分35.69,超越Random (35.26)、FineWeb-Edu (35.57)、Kurating (35.02);DataFlow-CHAT-15K将通用基准均值提升至28.21,AlpacaEval达10.11,优于ShareGPT和UltraChat。
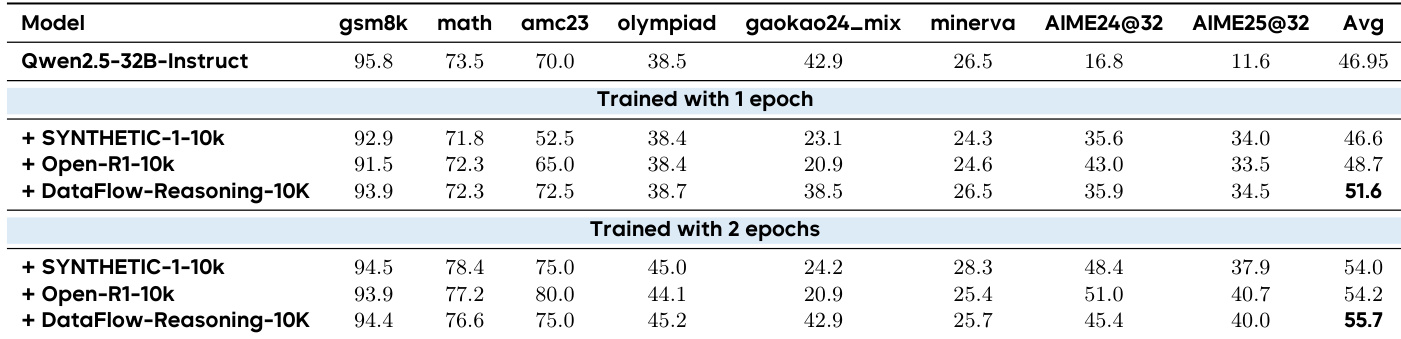
- 数学推理:DataFlow合成10k样本平均得分55.7,超越Open-R1 (54.2)和Synthetic-1 (54.0),证实数学推理中数据质量优于规模。
- 代码生成:DataFlow-CODE-10K在Qwen2.5-7B上代码基准平均得分46.2,超越Code Alpaca-1K与SC2-Exec-Filter,LiveCodeBench可执行正确率达33.2。
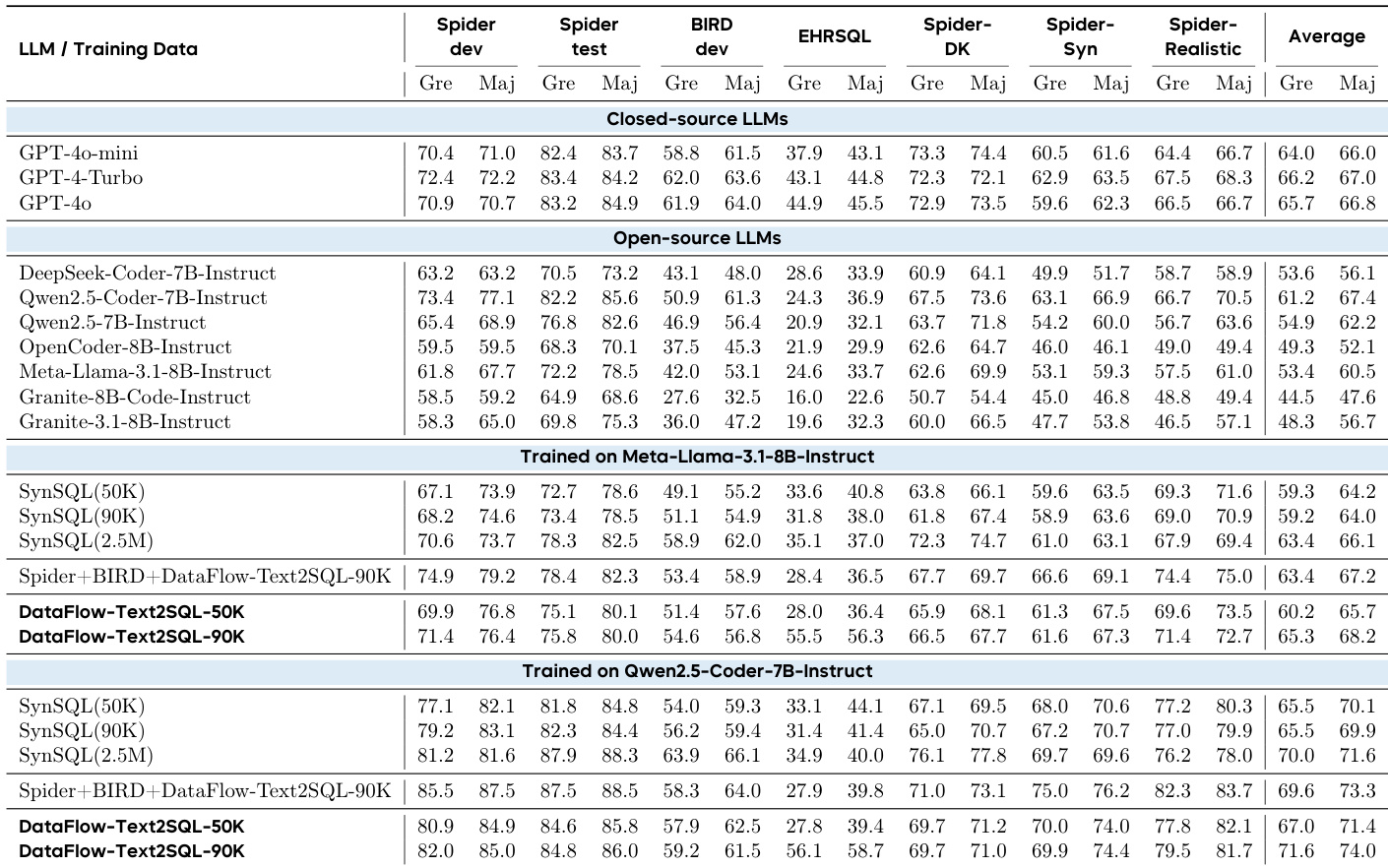
- Text-to-SQL:DataFlow-TEXT2SQL-50K在Spider-dev/BIRD-dev执行准确率达84.6/57.9,优于SynSQL(50K) (81.8/54.0),以1/50数据规模匹配SynSQL-2.5M性能。
- 代理RAG:DF-AgenticRAG-10k在多跳推理分布外平均得分超越Musique-20k (+1.2)和2Wiki-30k (+2.6)。
- 知识提取:DataFlow-KNOWLEDGE在PubMedQA/Covert准确率较思维链/RAG基线提升15–20点,证实领域QA增强效果。
- 统一多领域:DataFlow-INSTRUCT-10K使Qwen2.5-base数学得分达46.7,超越Inf-1M (33.3)并接近Qwen-Instruct (49.8),数据量减少100倍。
- 代理编排:文本规范对齐LLM-Judge得分0.80,但代码实现一致性仅0.49,复杂任务性能下降。
作者使用DATAFLOW从SlimPajama-627B过滤30B词元子集,并从头训练Qwen2.5-0.5B模型。结果显示DATAFLOW-30B在六项基准平均得分最高(35.69),优于Random-30B (35.26)、Kurating-30B (35.02)、FineWeb-Edu-30B (35.57),表明其多过滤器方法生成更干净、语义更一致的预训练数据。

作者使用DATAFLOW-KNOWLEDGE合成数据微调医学问答模型,在PubMedQA/Covert/PubHealth上均超越零样本思维链与RAG基线。结果显示SFT模型在PubMedQA/Covert上较思维链提升15–20点,PubHealth提升11点,证实结构化合成QA对的监督强度优于推理时方法。

作者使用DATAFLOW过滤并合成15K SFT样本,对比Alpaca/WizardLM的随机及过滤子集。结果显示DATAFLOW-SFT-15K在数学、代码、知识基准上持续优于基线,过滤版本仅带来微弱增益,表明合成数据本质质量更高。

作者使用DATAFLOW生成Text-to-SQL训练数据,评估其对Meta-Llama-3.1-8B-Instruct与Qwen2.5-Coder-7B-Instruct的影响。结果显示DATAFLOW-Text2SQL训练的模型在同等规模下持续优于SynSQL基线,部分基准性能接近更大规模SynSQL训练的模型。DATAFLOW生成数据在Spider/BIRD/EHRSQ基准显著提升执行准确率,证实其高质量与训练价值。
作者使用32B Qwen2.5模型评估三类10k合成数据集的数学推理性能,发现DataFlow-Reasoning-10K持续优于Synthetic-1-10k与Open-R1-10k。经两轮训练,DataFlow-Reasoning-10K平均得分最高(55.7),超越Open-R1-10k (54.2)与Synthetic-1-10k (54.0),表明其验证种子与思维链生成流水线的数据质量优势。结果证实数学推理任务中数据质量而非规模驱动性能提升。