Command Palette
Search for a command to run...
大型视频规划器实现可泛化的机器人控制
大型视频规划器实现可泛化的机器人控制
摘要
通用型机器人需要具备在多样化任务与环境间实现泛化的决策模型。近期研究通过将多模态大语言模型(MLLM)扩展至动作输出,构建机器人基础模型,形成视觉-语言-动作(VLA)系统。这一思路的动因在于,人们普遍认为MLLM在大规模语言与图像预训练中所积累的知识,能够有效迁移至动作输出模态。在本工作中,我们探索了一种替代范式:以大规模视频预训练作为构建机器人基础模型的核心模态。与静态图像和语言不同,视频能够捕捉物理世界中状态与动作的时空序列,这种特性天然契合机器人行为的动态特征。我们构建了一个互联网规模的人类活动与任务演示视频数据集,并首次在基础模型规模上训练了一个面向生成式机器人规划的开源视频模型。该模型可为全新场景与任务生成零样本视频规划,我们随后通过后处理提取出可执行的机器人动作。通过第三方选定的真实场景任务与真实机器人实验,我们评估了模型在任务层面的泛化能力,结果表明其能够成功实现物理世界的执行。综合来看,这些成果展示了模型在指令遵循、强泛化能力以及现实可行性方面的优异表现。我们已公开发布该模型与数据集,以支持开放、可复现的基于视频的机器人学习研究。
一句话总结
麻省理工学院、加州大学伯克利分校和哈佛大学的研究人员提出了一种基于大规模视频的机器人规划基础模型,利用互联网规模的视频预训练生成零样本视频计划,实现稳健的指令遵循和真实世界任务执行,标志着从视觉-语言-动作模型向以时空视频序列作为生成式机器人规划主要模态的转变。
主要贡献
- 本工作通过利用大规模视频预训练作为主要模态,提出了一种机器人基础模型的新范式,直接捕捉与机器人行为天然对齐的状态与动作的时空序列,区别于以往依赖静态图像和语言的视觉-语言-动作模型。
- 研究人员开发了大型视频规划器(LVP),一种增强历史引导和扩散强制机制的视频生成模型,确保生成运动计划的物理一致性和因果连贯性,从而实现从单张图像和自然语言指令出发的零样本视频规划。
- 他们发布了一个开放的、互联网规模的人类与机器人任务演示视频数据集,并通过第三方评估和多样、非结构化环境中的真实机器人实验,展示了强大的任务级泛化能力,实现了成功的端到端物理执行。
引言
研究人员将大规模视频预训练作为机器人规划的基础,解决了现有视觉-语言-动作(VLA)模型依赖稀缺机器人数据以及语言和视觉模型不对称迁移的局限性。与静态图像-文本对不同,视频天然编码了时空状态-动作序列,提供了更直接且物理基础的机器人行为表示。先前工作的关键挑战在于缺乏足够、多样且时间连贯的动作数据,难以训练出鲁棒且可泛化的策略。为克服这一问题,研究人员提出了大型视频规划器(LVP),一种在新构建的、开放的互联网规模人类与机器人任务演示数据集上训练的视频生成模型。该模型能够从单张图像和自然语言指令生成零样本视频计划,随后通过三维场景重建和手部动作重定向进行后处理,提取可执行的机器人动作。该方法在多样、未见过的环境和任务中实现了强大的任务级泛化,通过独立评估和真实机器人实验(包括平行夹爪和灵巧手)得到验证。
数据集

-
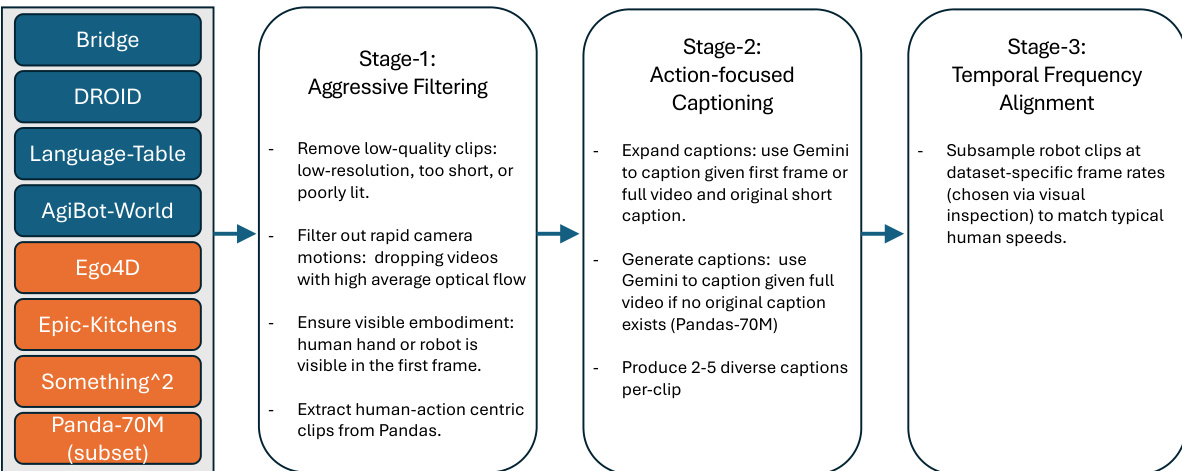
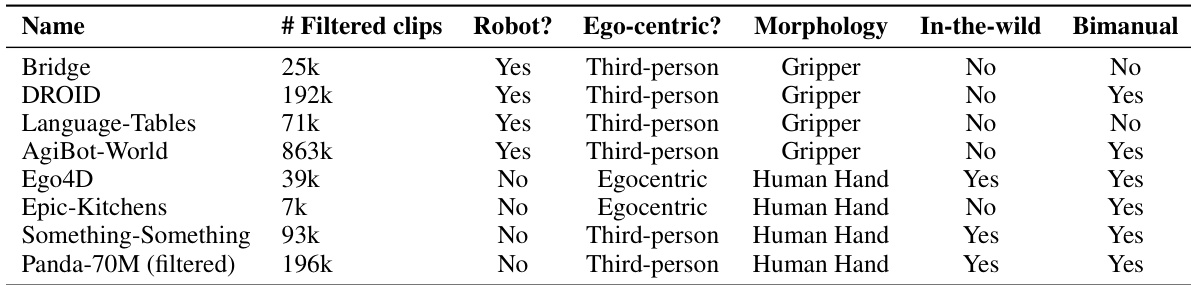
LVP-1M 数据集包含 140 万段人类与机器人与物体交互的短视频片段,每段视频均配有多个以动作为中心的文本描述。该数据集由三大来源构建:网络爬取视频(Pandas-70M)、第一人称人类活动数据集(Ego4D、Epic Kitchens、Something-Something)以及机器人遥操作数据集(Bridge、Droid、Language Table、AgiBot-World),确保了在本体、视角、场景类型和任务复杂度上的多样性。
-
Pandas-70M 子集经过三阶段筛选后贡献了 19.6 万段视频:基于关键词的筛选(使用白名单,如“抓取”、“拉”;黑名单,如“卡通”、“电子游戏”)、人体姿态检测以保留包含 1–3 个可见人类的片段,以及使用 Gemini-2.0 Flash 在四个标准上的评估:丰富手部运动、有意义的动作、正常播放速度、无场景变化。
-
第一人称数据集(Ego4D、Epic Kitchens、Something-Something)提供中等规模的片段,具有中等多样性但背景运动较强。通过光流过滤去除具有快速相机运动的片段(去除时空平均光流最高的前 30%),并优化动作边界以匹配原子动作。
-
机器人数据集(Bridge、Droid、Language Table、AgiBot-World)提供机器人特有交互,但存在视觉质量低、帧率不一致、描述模糊或缺失等问题。这些数据通过 Gemini Flash 进行大量重标注,使用初始帧或完整片段作为提示,生成详细、以动作为中心的描述。
-
所有视频均被时间对齐至 3 秒长度,帧率为每秒 16 帧,以标准化动作持续时间并确保人类速度一致性,无论原始录制速度如何。长时程任务被拆分为原子动作,帧率通过上采样或加速调整以匹配人类运动节奏。
-
质量过滤移除了低分辨率、照明差或过短/过长的片段。额外过滤确保第一帧中可见本体(手或夹爪)通过目标检测,排除机器人数据中的失败轨迹,并移除具有快速相机运动的视频。
-
每段视频配以 2–5 个不同描述——从简洁到高度详细——使用 Gemini Flash 生成,提示包括任务描述(如“拿起一个杯子”)以提升动作准确性。这增强了语言多样性并提高指令遵循的鲁棒性。
-
数据集在训练中采用基于加权采样的混合比例:AgiBot-World(0.05)、Droid(0.5)、Ego4D(0.75)、Pandas(过滤后)(1.5)、SomethingSomething(0.5)、Bridge(1.0)、Epic-Kitchens(2.0)、Language Table(0.375),以平衡因数据规模差异带来的贡献不均。
-
训练中每个样本为 49 帧视频,分辨率为 832×480,编码为形状为 104×60×13 的 VAE 潜在表示。模型预训练 60,000 次迭代,采用预热和恒定学习率 1×10⁻⁵,随后在 2.5×10⁻⁶ 学习率下微调 10,000 次迭代。
-
评估阶段,从第三方参与者处众包获取 100 个高质量、分布外的任务,要求提供场景照片、3–5 秒任务描述,以及具有创造性和非例行性的操作任务。低质量提交被过滤,最终指令通过 Gemini 进行优化。
方法
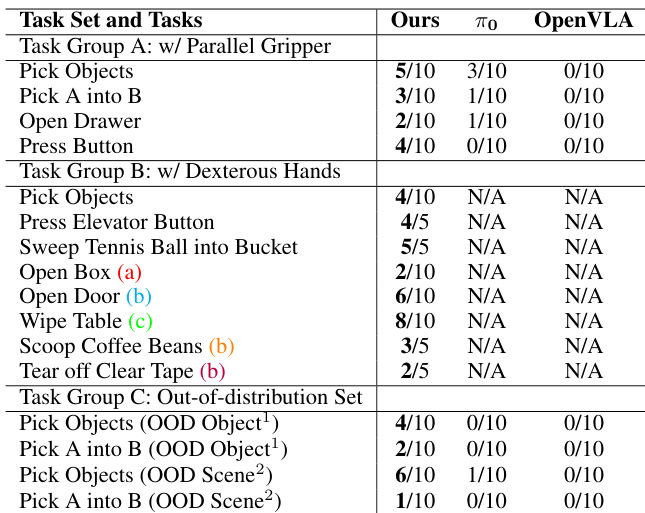
研究人员采用两阶段框架进行机器人基础建模:首先由大型视频规划器生成基于观测和目标的运动计划,随后通过动作提取流程将这些计划转化为可执行的机器人动作。系统核心是大型视频规划器(LVP),一个基于潜在扩散框架构建的 140 亿参数视频基础模型。整体架构始于一个时间因果的三维变分自编码器(VAE),将输入视频片段压缩为紧凑的低维潜在表示。该 VAE 编码时空块,将形状为 [1+T,3,H,W] 的输入视频转换为形状为 [1+⌈T/4⌉,16,⌈H/4⌉,⌈W/4⌉] 的潜在表示,其中第一帧重复四次,以支持与单帧图像数据的联合训练。VAE 冻结,扩散 Transformer 在此潜在空间中训练以生成视频。模型使用流匹配目标进行训练,将高斯噪声添加到干净视频潜在 z0 生成噪声潜在 zk=(1−k)z0+kϵ,模型学习在噪声潜在、文本指令和噪声水平条件下预测流 ϵ−z0。
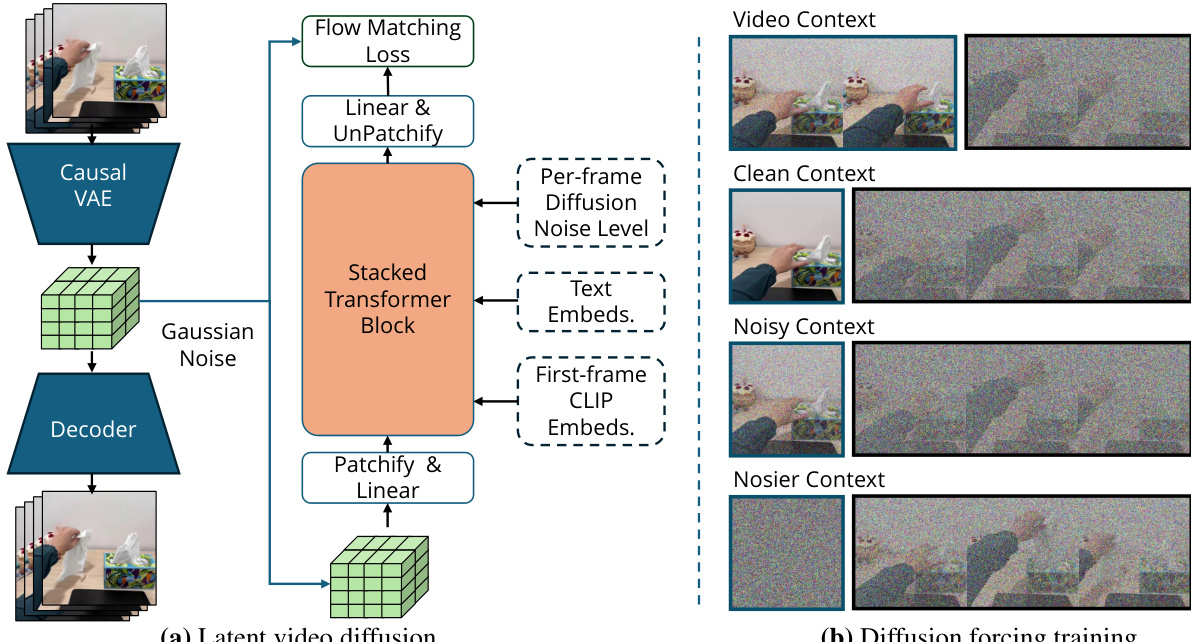
参考框架图,展示完整流程。扩散 Transformer 为 DiT 变体,采用改进的扩散强制策略,实现对图像和视频上下文的灵活条件化。该方法允许模型在干净第一帧(图像到视频)或多个历史帧(视频到视频)条件下进行条件化,通过为上下文和未来部分应用不同噪声水平实现。训练时,随机选择 0 到 6 帧之间的上下文长度,并为历史和未来部分独立应用噪声水平。历史部分以 50% 概率设为零噪声,使模型能够学习在干净或噪声上下文帧上进行条件化。该方法无需额外的交叉注意力机制,且与预训练模型权重兼容。模型进一步通过历史引导增强,这是一种无分类器引导的变体,结合条件采样与无条件采样的得分,以提升对文本指令和上下文帧的遵循程度,生成更连贯且物理可行的视频计划。
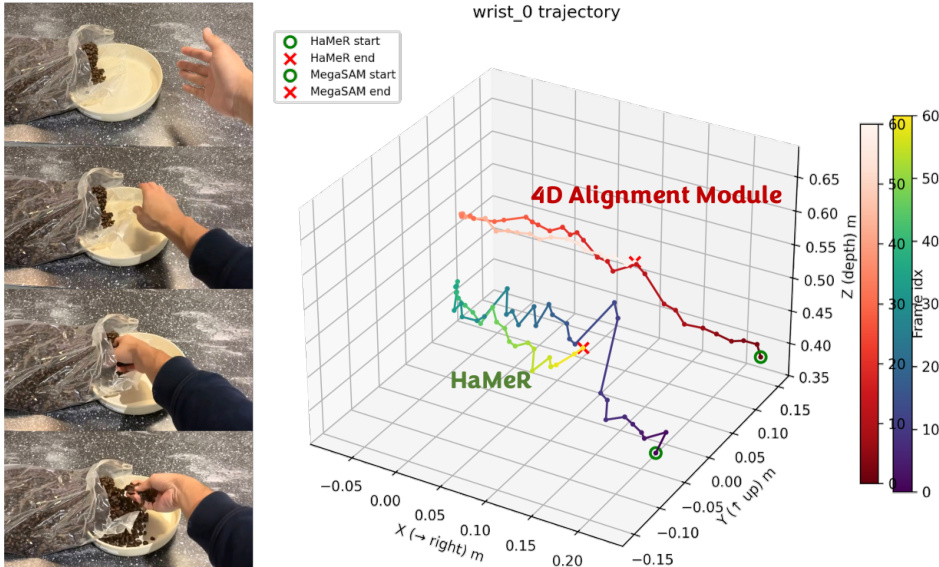
动作提取流程将生成的人类手部视频计划转换为可执行的机器人动作。过程始于人类手部运动估计,使用 HaMeR 模型逐帧预测手部姿态,该模型回归 MANO 手部顶点和腕部方向。然而,由于单目尺度模糊性和缺乏时间一致性,预测的平移会随时间漂移。为解决此问题,采用 4D 重建模型 MegaSAM 估计逐帧深度图和相机位姿。腕部位置随后通过深度和相机内参从图像平面反投影至 3D,生成的点云用于估计时间平滑的平移,同时保留 HaMeR 的方向。该 4D 对齐模块显著提升了腕部定位的鲁棒性和时间一致性。
估计的手部姿态随后用于机器人手指动作重定向。对于灵巧手,研究人员使用 Dex-Retargeting,通过求解优化目标将人类手部关键点映射到机器人关节配置,生成机器人手指关节角度。生成的腕部轨迹和手指关节序列以第一视频帧的相机坐标系表示。为在物理机器人上执行,腕部姿态通过固定旋转对齐至机器人控制坐标系,统一相机与机器人坐标系的轴向。腕部轨迹用于求解机器人臂的逆运动学,而手指关节序列直接驱动机器人手控制器。最后一步为真实机器人执行,同步的臂与手轨迹发送至机器人控制 API 以完成任务。该流程还支持向平行夹爪重定向,通过 GraspNet 预测抓取姿态,并使用启发式方法从人类动作中检测抓取意图。
实验
- 在 100 个野外测试样本上评估视频运动规划,采用四级指标:正确接触(第 1 级)、正确终态(第 2 级)、任务完成(第 3 级)、完美任务完成(第 4 级)。本方法在第 3 级达到 59.3% 的成功率,显著优于基线模型 Wan 2.1 I2V 14B、Cosmos-Predict 2 14B 和 Hunyuan I2V 13B,尤其在通过迭代视频扩展生成连贯、物理一致的长时程运动计划方面表现突出。
- 在两个平台实现零样本真实世界机器人操作:Franka 机械臂配平行夹爪,Unitree G1 人形机器人配 Inspire 灵巧手。本方法在挑战性任务(如舀咖啡豆、撕胶带)中表现出强泛化能力,优于基线 π0 和 OpenVLA,后者在分布外和复杂灵巧操作任务中表现不佳。
- 在多样任务中成功实现动作重定向与执行,定性结果显示视频计划生成准确,真实机器人表现良好,包括物体在手中旋转、工具使用和精确放置,验证了端到端流程的鲁棒性。
研究人员使用表格比较不同数据集的特征,包括过滤后片段数量、是否涉及机器人、视角、形态、野外条件和双手任务。表格显示,Bridge、DROID 和 Language-Tables 为机器人数据,第三人称视角,使用夹爪;而 Ego4D 和 Epic-Kitchens 为非机器人数据,第一人称视角,涉及人类手部。
结果表明,所提方法在所有评估层级上均显著优于基线,尤其在第 3 级(任务完成)和第 4 级(完美)提升最大,表明其在生成连贯、任务完整且物理真实的视频计划方面具有卓越能力。研究人员采用四级评估指标衡量指令遵循、运动可行性与物理真实性,其模型在第 3 级达到 59.3% 的成功率,展示了在野外场景中强大的零样本泛化能力。

研究人员在真实机器人操作任务上评估其视频规划器,使用两个平台:配备平行夹爪的 Franka 机械臂和配备灵巧手的 G1 人形机器人。结果表明,其方法在两个平台上均优于基线,尤其在复杂灵巧操作任务和分布外场景中表现突出。