Command Palette
Search for a command to run...
Qwen-Image-Layered:通过层分解实现固有可编辑性
Qwen-Image-Layered:通过层分解实现固有可编辑性
摘要
近期的视觉生成模型在图像编辑过程中常因位图图像固有的内容耦合特性而难以保持一致性,其中所有视觉元素均融合于单一画布之中。相比之下,专业设计工具采用分层表示方法,能够在保持整体一致性的前提下实现局部独立编辑。受此启发,我们提出 Qwen-Image-Layered——一种端到端的扩散模型,可将单张RGB图像分解为多个语义上解耦的RGBA图层,从而实现内在可编辑性:每个RGBA图层均可独立操作,且不会影响其他内容。为支持可变长度的图像分解,我们引入三个关键组件:(1)一种RGBA-VAE(变分自编码器),用于统一RGB与RGBA图像的潜在表示;(2)一种VLD-MMDiT(可变图层数分解MMDiT)架构,能够处理任意数量的图像图层分解;(3)一种多阶段训练策略,用于将预训练的图像生成模型适配为多图层图像分解器。此外,针对高质量多图层训练数据稀缺的问题,我们构建了一套自动化流水线,从Photoshop文档(PSD)中提取并标注多图层图像。实验结果表明,我们的方法在分解质量上显著优于现有技术,并为一致性的图像编辑树立了新的范式。
一句话总结
阿里巴巴与香港科技大学的研究人员提出Qwen-Image-Layered,这是一种端到端扩散模型,通过创新的RGBA-VAE和VLD-MMDiT组件将RGB图像分解为语义解耦的RGBA图层,支持可变长度分解。该方法实现了不影响其他内容的精准独立编辑,在基于PSD构建的专业设计训练数据集上,其分层图像质量显著优于现有方法。
主要贡献
- 现有视觉生成模型在图像编辑时面临一致性问题,因为栅格图像将所有内容融合在单一纠缠画布中,而专业分层设计工具支持独立编辑;Qwen-Image-Layered通过将单张RGB图像分解为多个语义解耦的RGBA图层解决此问题,实现固有可编辑性。
- 该方法引入三个核心组件:统一RGB与RGBA潜在表示的RGBA-VAE、支持可变长度图层分解的VLD-MMDiT架构、以及将预训练模型适配为多层分解器的多阶段训练策略,实现无需递归推理的端到端分解。
- 为解决多层训练数据稀缺问题,作者构建了从Photoshop文档(PSD)提取标注图像的流程;实验表明该方法在包含文字等多样化图像的分解质量上显著超越现有技术。
引言
图像编辑要求在修改区域时保持未修改区域的一致性,这对数字内容创作等专业应用至关重要,意外伪影会严重损害可用性。现有全局编辑方法受生成模型固有随机性影响,无法维持未触区域的保真度;而基于掩码的局部方法在遮挡和软边界处理上存在困难,导致区域识别不精确及持续的一致性问题。现有分解技术依赖易出错的分割或递归推理(尤其在复杂布局或半透明图层时错误会累积),产生低保真输出,难以满足精准编辑需求。作者提出Qwen-Image-Layered,这是一种端到端扩散模型,可直接将RGB图像分解为语义解耦的RGBA图层,支持独立图层操作而不影响其他内容,从根本上解决一致性问题.
数据集
作者通过解析真实PSD文件构建数据集以解决多层图像稀缺问题,关键细节如下:
- 组成与来源:使用psd-tools Python库解析真实PSD文件,避免合成或简化设计数据集。
- 子集处理:
- 过滤含异常元素(如模糊人脸)及不影响最终合成的非贡献图层。
- 合并空间不重叠图层以降低复杂度,显著减少图层数量(如图5a所示)。
- 采用Qwen2.5-VL为合成图像生成文本描述,支持文本到多图层生成。
- 模型应用:
- 专用于文本到多RGBA和图像到多RGBA任务训练,单图最多20层。
- 采用三阶段训练(500K、400K和400K优化步数),使用Adam优化器。
- 附加处理:未采用显式裁剪策略;元数据为Qwen2.5-VL生成的文本描述;图层合并是管理输入复杂度的主要结构调整。
方法
作者采用新型端到端扩散框架Qwen-Image-Layered,将单张RGB输入图像 I∈RH×W×3 分解为 N 个语义解耦的RGBA图层 L∈RN×H×W×4,其中每层 Li=[RGBi;αi] 包含颜色分量和alpha通道。原始图像通过序列alpha混合重建:
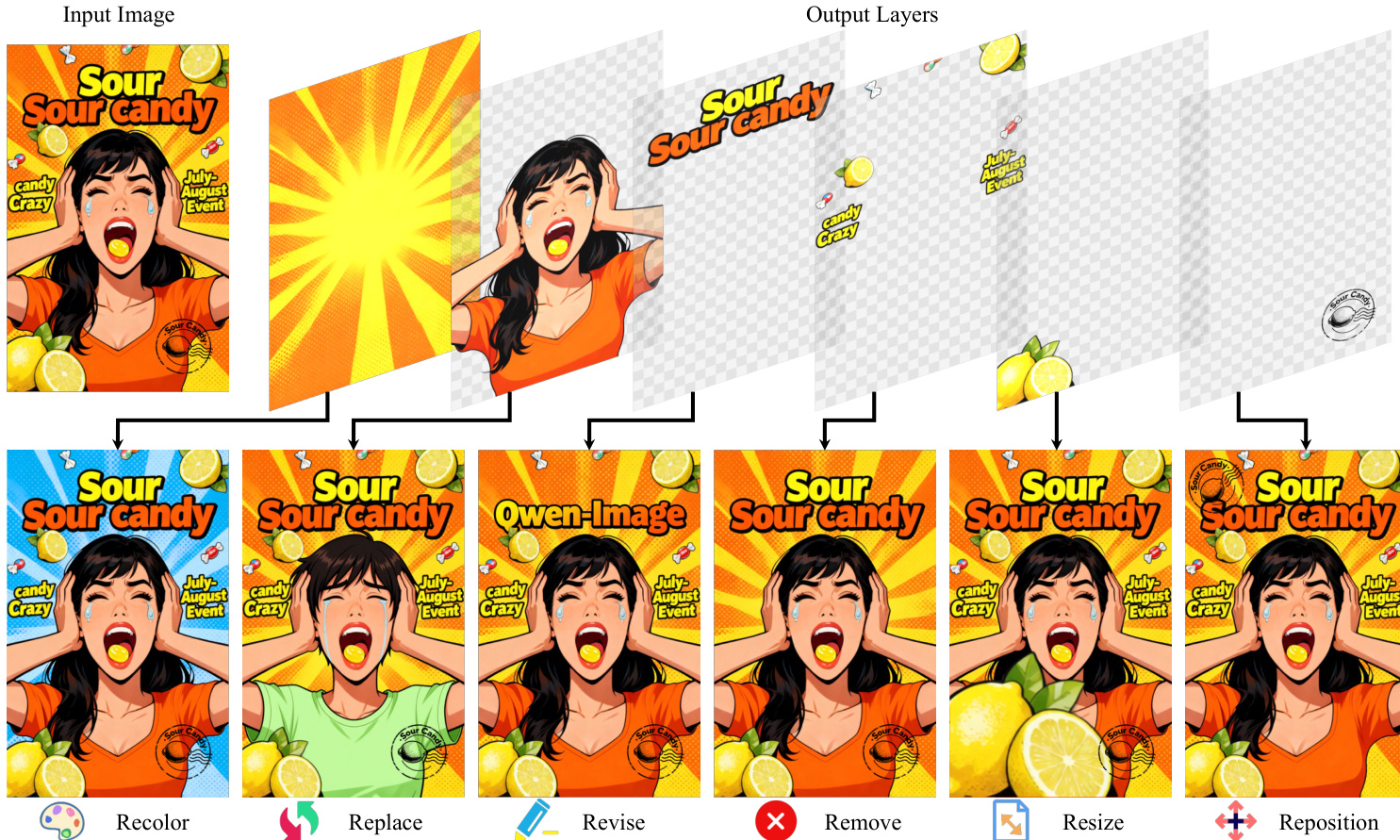
C0=0Ci=αi⋅RGBi+(1−αi)⋅Ci−1i=1,…,N其中 CN=I. 该分解实现固有可编辑性:每层可独立修改(重着色、缩放、重定位或移除)而不影响其他内容,图层操作视觉示例已验证此能力.
为支持该能力,架构集成三大创新. 首先,作者提出RGBA-VAE,将RGB输入与RGBA图层输出编码至共享潜在空间,消除先前使用独立VAE导致的分布差异. 编码器与解码器扩展至四通道,通过将预训练权重复制到前三通道、alpha通道参数置零(解码器偏置除外,初始化为1)保持RGB重建保真度. VAE采用包含重建、感知和正则化项的复合损失训练.
其次,模型采用VLD-MMDiT(可变图层分解MMDiT)架构,支持可变图层数分解及多任务训练. 输入RGB图像与目标RGBA图层均通过RGBA-VAE编码. 注意力计算时,其潜在序列沿序列维度拼接以建模层内与层间交互. 为处理可变图层数,作者引入Layer3D RoPE,通过显式图层维度扩展位置编码. 输入图像图层索引设为-1,目标图层索引从0开始递增,确保注意力计算时清晰分离.
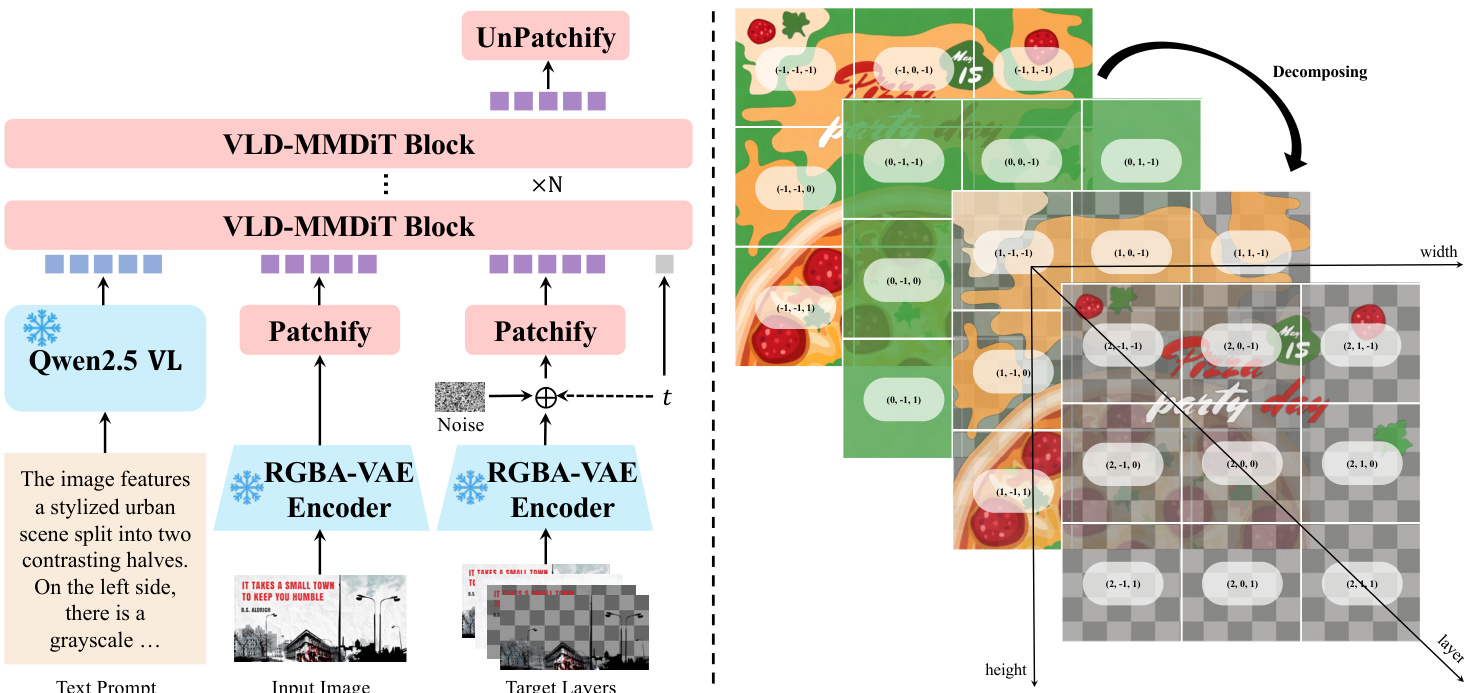
训练采用多阶段多任务策略逐步适配预训练图像生成模型. 阶段1通过联合训练文本到RGB和文本到RGBA生成,将MMDiT适配至RGBA-VAE潜在空间. 阶段2引入文本到多RGBA生成,模型同时预测最终合成图及其组成透明图层,实现信息流动. 阶段3通过条件输入RGB图像和文本提示,将模型扩展至图像到多RGBA分解,采用Flow Matching目标. 模型预测中间状态 xt=tx0+(1−t)x1 的速度 vθ(xt,t,zI,h),其中 x0 为潜在目标,x1 为噪声,zI 为编码输入图像,最小化与真实速度 vt=x0−x1 的均方误差.
实验
- Crello数据集图像分解在Alpha soft IoU和RGB L1指标上均获最高分,以更优alpha通道保真度和无伪影图层生成超越LayerD[36].
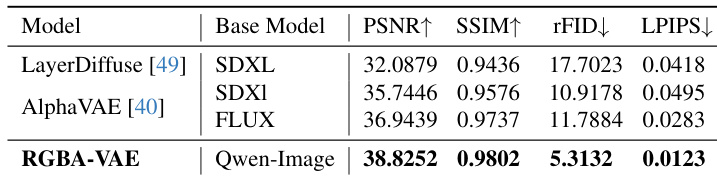
- AIM-500数据集RGBA图像重建在所有指标(PSNR、SSIM、rFID、LPIPS)上优于LayerDiffuse和AlphaVAE,展现最先进重建能力.
- 定性图像编辑实现一致的高保真缩放和重定位,无像素级偏移,不同于Qwen-Image-Edit-2509,因其支持精准的逐层修改.
- 多图层图像合成产生语义连贯的分层构图,文本到图像与分解联合管线增强视觉美感和语义对齐.
作者在Crello数据集上使用RGB L1和Alpha soft IoU指标评估图像分解,允许最多五层相邻合并以应对分解歧义. 结果表明Qwen-Image-Layered-I2L在所有合并设置下均一致超越LayerD及其他基线,取得最低RGB L1和最高Alpha soft IoU,表明其图层保真度和alpha通道精度更优.

作者在不同图层合并约束下评估图像分解模型,结果表明包含所有组件(Layer3D RoPE、RGBA-VAE和多阶段训练)的完整模型性能最优,在所有合并设置下均取得最低RGB L1和最高Alpha soft IoU,证明其分解精度和alpha通道保真度优于消融版本.

作者在AIM-500数据集上使用PSNR、SSIM、rFID和LPIPS指标评估RGBA图像重建. 结果表明RGBA-VAE在所有指标上均优于LayerDiffuse和AlphaVAE,取得最高PSNR和SSIM,同时报告最低rFID和LPIPS,表明其重建保真度和感知质量更优.