Command Palette
Search for a command to run...
向量棱镜:通过分层语义结构实现向量图形的动画化
向量棱镜:通过分层语义结构实现向量图形的动画化
Jooyeol Yun Jaegul Choo
摘要
可缩放矢量图形(Scalable Vector Graphics, SVG)在现代网页设计中占据核心地位,随着网络环境日益动态化,对SVG动画的需求持续增长。然而,尽管在代码生成与运动规划方面取得了进展,视觉语言模型(Vision-Language Models, VLMs)在自动化矢量图形动画方面仍面临重大挑战。VLMs 常常无法正确处理SVG,其原因在于,视觉上连贯的组成部分往往被分解为低层级的几何形状,这些形状难以提供足够的语义线索,以判断哪些元素应协同运动。本文提出一种新框架,旨在恢复实现可靠SVG动画所必需的语义结构,并揭示当前VLM系统所忽视的关键缺失环节。该框架通过统计聚合多个弱化部件预测结果,使系统能够从噪声较大的预测中稳定推断出语义信息。通过对SVG进行语义分组重构,我们的方法显著提升了VLM生成动画的一致性与连贯性。实验结果表明,相较于现有方法,本方法取得了显著性能提升,证实语义恢复是实现稳健SVG动画的关键步骤,也为VLM与矢量图形之间的可解释性交互提供了有力支持。
一句话总结
Jooyeol Yun 和 Jaegul Choo(KAIST AI)提出 Vector Prism 框架,通过统计聚合弱部件预测来恢复可缩放矢量图形(SVG)中的语义结构,使视觉语言模型能够通过整合碎片化图形生成连贯动画——解决了先前系统无法将 SVG 元素解释为统一语义单元的问题,显著提升了网页动画可靠性。
核心贡献
- 视觉语言模型难以实现 SVG 动画自动化,因为连贯的视觉元素被分割为低级图形,导致运动规划时无法确定哪些部件应协同移动。
- 该框架通过统计聚合多个弱部件预测来恢复缺失的语义结构,使 SVG 能可靠重组为有意义的语义组,从而指导连贯动画生成。
- 实验证明,该语义恢复步骤无需模型微调即可解锁强大的动画能力,在各项指标上显著超越现有方法。
引言
SVG 动画对动态网页体验至关重要,但视觉语言模型(VLM)难以实现其自动化,因为真实 SVG 将连贯视觉元素分割为低级图形,模糊了动画时应协同移动的部件。现有方法要么通过扩散模型优化矢量参数(因关注外观的栅格化而难以实现有效运动),要么直接微调大语言模型(需海量数据弥补几何理解缺陷,且在复杂非结构化 SVG 上失效)。本文提出框架通过统计聚合噪声部件预测来恢复 SVG 语义结构,使 VLM 能可靠分组元素并生成连贯动画,且无需模型微调。该语义恢复步骤弥合了原始矢量数据与运动规划间的鸿沟,显著提升动画质量与可解释性。
数据集
作者使用 114 组手工制作的动画指令-SVG 配对数据集进行评估,关键细节如下:
-
构成与来源:
基于 SVGRepo 的 57 个独特 SVG 文件构建,每个文件配对两种不同动画场景。SVG 主题涵盖动物、标志、建筑及自然元素(火焰、云、水)。 -
子集详情:
- 主题覆盖:31.6% 自然/环境类,26.3% 物体/杂项类,含科技标志与 UI 元素。
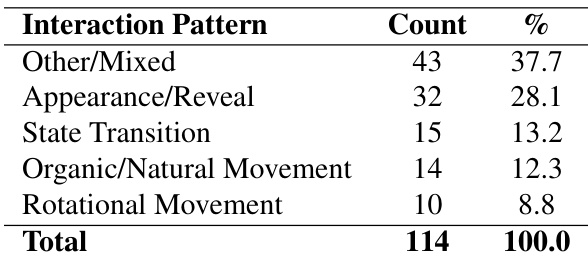
- 交互模式:28.1% 外观/显现动画,13.2% 状态转换,12.3% 有机/自然运动,8.8% 旋转运动。
所有示例模拟真实网页动画需求,从加载指示器到交互式叙事。
-
使用与处理:
该数据集仅用于测试而非训练,未应用混合比例。指令经人工筛选以确保技术多样性(从简单移动到 3D 旋转)及与现代网页用例的相关性。未进行额外预处理、裁剪或元数据构建。
方法
作者采用三阶段流程弥合 VLM 动画 SVG 时固有的语义-语法鸿沟:动画规划 → 创新重构模块 Vector Prism → 动画生成。核心创新在于 Vector Prism,它将 VLM 的噪声弱语义预测转化为可靠的结构化 SVG 代码,实现精确的指令跟随动画。
如下图所示,整体流程以 SVG 文件和自然语言指令为输入,输出动画 SVG 文件。第一阶段语义理解利用 VLM 解析渲染后 SVG 的视觉内容,生成高层动画规划(例如将"让太阳升起"解读为黄色圆形区域上移及背景渐亮)。由于 VLM 不具备 SVG 语法知识,无法直接实施规划。此时 Vector Prism 介入,将非结构化 SVG 转化为语义连贯的表示,在保留视觉外观的同时支持语法操作。
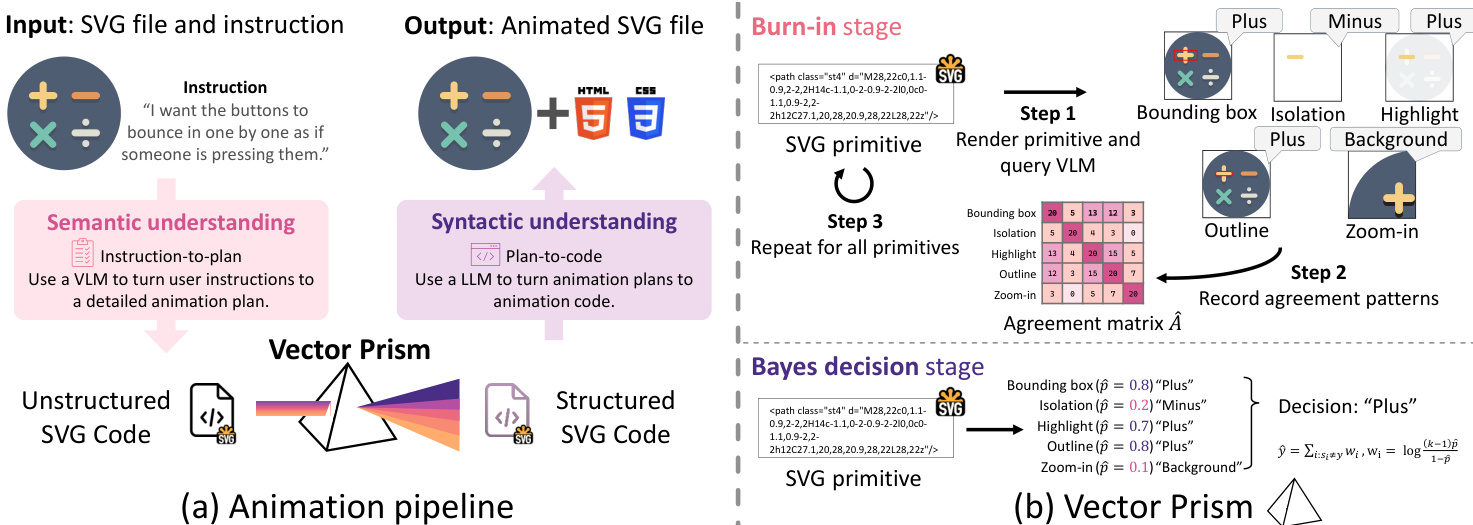
Vector Prism 通过多渲染视角统计推断每个 SVG 基元(如 <path>, <rect>, <circle>)的语义标签。每个基元用 M 种方法渲染(如边界框叠加、白底隔离、放大、高亮或描边),VLM 为每种视角分配标签。这些视角提供互补信号,使系统能为每个基元收集多个噪声预测。作者将每种渲染方法建模为 Dawid-Skene 分类器(准确率未知 pi),其中正确标签概率为 pi,错误标签均匀选自其余 k−1 类别。
为估计各渲染方法可靠性 pi,系统对所有基元执行预热阶段以构建经验一致矩阵 A^ij(记录方法 i 与 j 一致的基元比例)。在 Dawid-Skene 模型下,方法间预期一致率为 Aij=pipj+k−1(1−pi)(1−pj)。通过减去随机一致项 1/k 中心化该矩阵,作者推导出秩一矩阵 E[B]=k−1kδδ⊤(其中 δi=pi−k1)。经验中心矩阵 B^ 的主特征向量用于恢复 δ^ 及 p^i,从而量化各渲染方法可靠性。
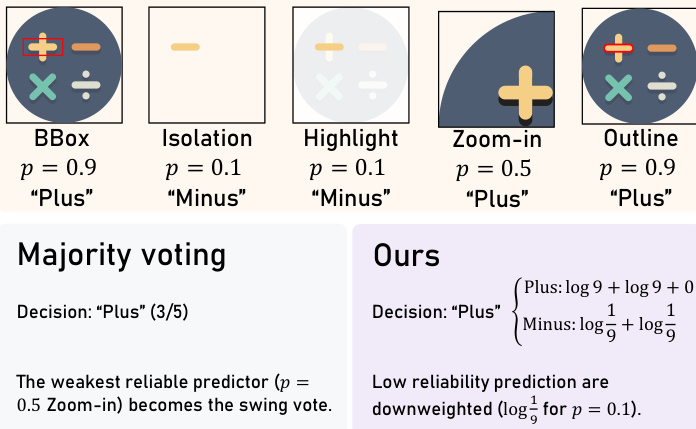
获得估计可靠性后,Vector Prism 采用均匀先验的贝叶斯决策规则为每个基元分配最终语义标签。候选标签 y 的对数似然为 logP(y∣s)=const+∑i:si=ylogp^i+∑i:si=ylogk−11−p^i。这等价于加权投票,方法 i 的权重为 wi=log1−p^i(k−1)p^i。如下图所示,该方法降低不可靠预测权重(如 p=0.1 时贡献负权重 log91),而多数投票会平等对待所有预测,可能使低可靠性方法主导结果。
标签分配后,SVG 被重构以反映语义而不改变视觉外观。作者展平原有层次结构,将继承属性固化到基元中,并按标签重组基元同时保留原始绘制顺序。障碍测试确保合并同标签基元不会与不同标签的中间元素产生渲染冲突。结果 SVG 与输入视觉一致但语义结构化,每组均标注边界框和几何中心等元数据,后续用于驱动动画。
最后在动画生成阶段,LLM 根据第一阶段生成的规划为每个语义组生成 CSS 动画代码。为处理长输出,系统按组迭代生成动画,保留上下文中已生成的 CSS 以确保一致性并避免冲突. LLM 采用"轨道"规范,通过类型化 CSS 自定义属性表达各运动分量(平移、旋转等),再组合为最终关键帧。这种模块化方法确保不同语义组的动画可独立生成并可靠组合。

实验
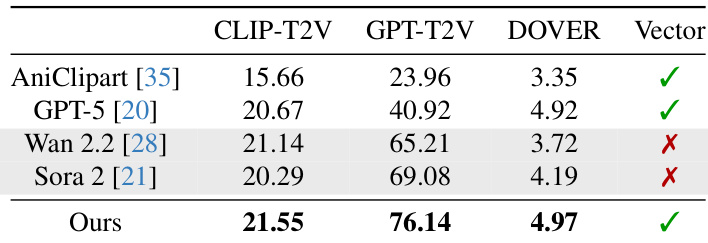
- Vector Prism 在 SVG 动画任务中验证成功,在 CLIP-T2V、GPT-T2V 和 DOVER 指标上全面领先,超越 AniClipart、GPT-5、Wan 2.2 及 Sora 2,指令跟随与感知质量显著提升
- 760 组配对比较的用户研究表明,83.4% 人类偏好与 GPT-T2V 评分一致,证实 Vector Prism 对所有基线(含 Sora 2)的持续优势
- 实现比 Sora 2 小 ×54 的文件尺寸,同时保持动画保真度,证明其在网页矢量图形中的卓越编码效率
- Vector Prism 语义聚类达 Davies-Bouldin 指数 0.82,大幅优于原始 SVG 分组(33.8)和多数投票(12.6)
- GPT-T2V 评估显示 83.4% 与人类偏好一致,显著超过 CLIP-T2V 在指令跟随评估中的 53.4% 一致性
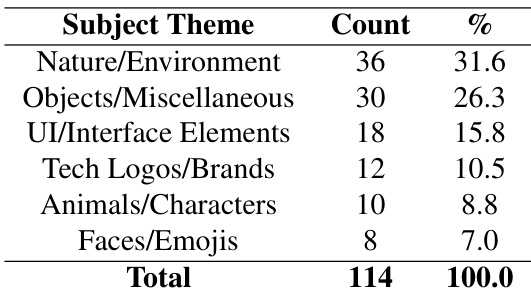
作者分析 114 条按主题分类的动画指令,发现自然/环境类占比最高(31.6%),其次为物体/杂项类(26.3%)。UI/界面元素、科技标志/品牌、动物/角色及面部/表情符号占剩余 36.3%,反映主题分布多样但偏向自然与通用物体。
作者分析生成动画中的交互模式,发现"其他/混合"行为占比最高(37.7%),其次为"外观/显现"(28.1%)。状态转换、有机运动和旋转运动占比较低(分别为 13.2%、12.3%、8.8%),表明评估数据集偏好复合或非特定运动类型。
作者使用 CLIP-T2V、GPT-T2V 和 DOVER 指标评估方法,结果显示所提方案在三项指标上均获最高分,证明其指令跟随与感知质量优势。Wan 2.2 和 Sora 2 等视频生成模型在 GPT-T2V 上得分较高,但无法输出矢量格式(标红叉),而所提方法成功生成有效矢量动画。结果证实该方法在保持矢量格式兼容性的同时,优于基于优化和 LLM 的基线方案。