Command Palette
Search for a command to run...
Nemotron-Cascade:面向通用推理模型的级联强化学习扩展
Nemotron-Cascade:面向通用推理模型的级联强化学习扩展
摘要
利用强化学习(Reinforcement Learning, RL)构建通用推理模型面临显著的跨领域异质性问题,包括推理阶段响应长度的巨大差异以及验证延迟的波动。这种变异性加剧了强化学习基础设施的复杂性,拖慢训练进程,并使得训练课程设计(如响应长度扩展)和超参数选择变得极为困难。在本研究中,我们提出了一种级联式领域专用强化学习方法(Cascaded Domain-wise Reinforcement Learning, Cascade RL),用于开发通用推理模型Nemotron-Cascade,该模型能够同时支持指令模式(instruct mode)与深度思考模式(deep thinking mode)。与传统方法中混合来自不同领域的异构提示(prompt)的做法不同,Cascade RL采用顺序化的、按领域划分的强化学习策略,显著降低了工程实现复杂度,并在广泛的基准测试中实现了当前最优性能。值得注意的是,若将基于人类反馈的强化学习(RLHF)作为预处理步骤,其对模型推理能力的提升远超单纯的偏好优化效果;后续的领域专用RLVR(Reinforcement Learning with Value Refinement)阶段不仅极少损害前期领域所达到的基准性能,甚至还能进一步提升性能(详见图1示意)。我们训练的140亿参数模型(14B)在经过强化学习优化后,在LiveCodeBench v5/v6/Pro基准上超越了其监督微调(SFT)教师模型DeepSeek-R1-0528,并在2025年国际信息学奥林匹克竞赛(IOI)中取得了银牌水平的表现。我们已公开透明地分享了完整的训练流程与数据配方(training and data recipes)。
一句话总结
作者提出采用级联领域特定强化学习(Cascade RL)的Nemotron-Cascade推理模型,通过顺序处理不同领域任务替代混合异构提示,降低基础设施复杂度。该方法结合显著提升推理能力(超越对齐目标)的RLHF预训练,使其14B模型在LiveCodeBench上超越DeepSeek-R1教师模型,并在2025年国际信息学奥林匹克竞赛(IOI)中获得银牌。
核心贡献
- Cascade RL通过将混合提示训练替换为顺序领域特定强化学习阶段,解决推理模型强化学习中的跨领域异质性问题,降低工程复杂度,并在无领域干扰的情况下实现有效训练课程。
- 该方法将RLHF作为初始步骤,显著提升超越标准对齐的推理能力;后续领域特定强化学习阶段因抵抗灾难性遗忘,能够维持或提升先前领域的性能。
- 14B Nemotron-Cascade模型在LiveCodeBench v5/v6/Pro上超越其SFT教师模型,并在2025年国际信息学奥林匹克竞赛中获得银牌成绩,在多项推理基准测试中实现最先进结果。
引言
强化学习(RL)对提升具备强大推理能力的通用语言模型至关重要,但此类模型训练面临领域异质性的重大挑战:数学任务采用快速符号验证,代码生成需耗时执行检查,而对齐依赖奖励模型。这种多样性使基础设施复杂化、训练变慢、超参数优化困难;先前联合训练方法(如DeepSeek-R1和Qwen3)难以统一"思考"(长链推理)与"指令"(即时响应)模式而不损害推理性能。作者通过扩展级联强化学习(Cascade RL)解决此问题:按顺序执行领域特定RL阶段(如数学先于代码),利用验证速度差异、防止灾难性遗忘,最终实现单一开源权重模型——Nemotron-Cascade。该模型在数学、代码、科学及指令遵循任务上均取得最先进结果,且在思考与非思考模式下均能有效运行。
数据集
作者构建多领域训练数据集,结构如下:
-
通用领域数据:
- 280万样本(32亿token),涵盖对话、问答、创意写作、安全、指令遵循及知识密集型领域(如法律、伦理)。
- 通过DeepSeek-R1-0528(思考模式)和DeepSeek-V3-0324(非思考模式)生成平行响应(最大16K token);经Qwen2.5-32B-Instruct交叉验证过滤低质量输出;通过重写单轮样本或随机拼接增强多轮对话。
-
数学推理数据:
- 阶段1:277万样本来自AceMath、NuminaMath和OpenMathReasoning(35.3万提示,每提示7.8个响应;最大16K token),通过9-gram重叠过滤去污染。
- 阶段2:188万样本来自过滤后的阶段1提示(16.3万提示,每提示11.5个响应;最大32K token),由DeepSeek-R1-0528生成详细推理轨迹。全为思考模式。
-
代码推理数据:
- 阶段1:142万样本来自TACO、APPS和OpenCodeReasoning(17.2万提示,每提示8.3个响应;最大16K token),经去重与去污染处理。
- 阶段2:139万样本来自OpenCodeReasoning(7.9万提示,每提示17.6个响应;最大32K token)。全为思考模式.
-
科学推理数据:
- 28.9万阶段1和34.5万阶段2样本来自S1K和Llama-Nemotron数据集,经科学严谨性过滤并由DeepSeek-R1-0528增强合成问题;通过9-gram重叠去污染。阶段2数据在训练中上采样2倍。
-
工具调用数据:
- 31万对话(141万轮次)来自Llama-Nemotron,覆盖单/多轮交互(每对话最多4.4个工具);由Qwen3-235B-A22B在思考模式下生成响应。
-
软件工程数据:
- 代码修复:12.7万高质量样本(1.7万SWE-Bench-Train、1.7万SWE-reBench、1.8万SWE-Smith、7.7万SWE-Fixer-Train),通过Unidiff相似度≥0.5过滤。
- 定位:9.2万样本(召回率=1.0);测试生成:3.1万样本(无语法错误)。阶段2训练中全上采样3倍。
数据集用于两阶段监督微调:
- 阶段1 混合通用领域数据与阶段1数学/代码/科学子集。
- 阶段2 结合阶段2数学/代码/科学数据(科学上采样2倍,软件工程上采样3倍)、工具调用数据及通用领域数据(最大32K token)。所有推理聚焦数据采用思考模式格式以鼓励逐步输出。
方法
作者采用级联强化学习(Cascade RL)框架训练Nemotron-Cascade——一种能在指令与深度思考模式下运行的通用推理模型。训练流程始于多阶段监督微调(SFT),使基础模型具备数学、编码、科学、工具使用及软件工程等多领域基础能力。随后按顺序执行领域特定RL阶段——RLHF、指令遵循RL、数学RL、代码RL和SWE RL——以提升推理性能同时最小化灾难性遗忘。
参考框架示意图,该图展示了从基础模型经SFT和级联RL阶段到最终Nemotron-Cascade模型的顺序流程。SFT课程分为两阶段:阶段1(16K token)引入通用领域数据及数学、科学、代码推理数据(后三者采用思考模式响应);阶段2(32K token)扩展响应长度并整合工具使用与软件工程数据集,进一步优化模型推理能力。
如下图所示,模型交互模式由自定义聊天模板控制,支持显式生成模式切换。/think和/no_think标志附加于用户提示(而非系统提示),以实现会话内全局与局部模式切换。工具调用时,可用函数在系统提示的标签内声明,模型被要求将工具调用封装在 <tool_call> 和 <tool_call> 标签中。此设计简化了模式控制,相比先前方法确保可靠切换且无性能下降。

RL训练采用严格在线策略更新的组相对策略优化(GRPO)算法,确保稳定性并缓解熵崩溃。通过移除KL散度项简化GRPO目标,简化为带组归一化奖励和token级损失的标准REINFORCE目标:
IGRPO(θ)=E(q,a)∼D,{oi}i=1G∼πθ(⋅∣q)∑i=1G∣oi∣1i=1∑Gt=1∑∣oi∣A^i,t,whereA^i,t=std({ri}i=1G)ri−mean({ri}i=1G)forallt,其中 {ri}i=1G 表示对给定问题 q 的采样响应组分配的奖励,经RLVR阶段与真实答案验证或RLHF中奖励模型评分。
RLHF阶段启动级联流程,通过减少冗余和重复提升响应质量,从而增强后续阶段的推理效率。RLHF的奖励模型基于Bradley-Terry目标在成对人类偏好上训练,初始化自Qwen2.5-72B-Instruct。对于统一模型,RLHF在思考与非思考模式下以相等批次分配执行。
指令遵循RL(IF-RL)紧随其后,对统一模型与专用思考模型采用不同策略。统一模型仅在非思考模式下执行IF-RL以避免损害人类对齐;思考模型则采用集成指令遵循验证与归一化人类偏好分数的组合奖励函数:
ri={RIF(oi)+sigmoid(R^RM(oi)),0,ifRIF(oi)=1otherwise,thereinR^RM(oi)=std({RRM(oi)}i=1G)RRM(oi)−mean({RRM(oi)}i=1G)数学RL随后执行,采用分阶段响应长度扩展课程(24K → 32K → 40K)逐步深化推理链。每轮动态过滤仅保留提供有意义梯度信号的问题,确保训练稳定。代码RL在数学RL检查点上执行,使用固定44K–48K响应长度且无超长过滤。
最终阶段SWE RL针对软件工程任务,使用无执行验证器基于生成与真实补丁的词法及语义相似度计算奖励:
r(p^,p∗)=⎩⎨⎧1,0,−1,ssem(p^,p∗),ifslex(p^,p∗)=1,p^ 与原始代码片段相同p^ 无法解析,otherwise,其中语义相似度通过72B LLM对是非问题提示评估。训练采用两阶段上下文扩展课程(16K → 24K输入token)稳定长上下文学习。整个流程最终生成Nemotron-Cascade模型,在包括IOI 2025银牌在内的多项基准测试中展现最先进性能.
实验
- Cascade RL框架在人类反馈对齐、指令遵循、数学、竞赛编程及软件工程领域得到验证,领域特定RL阶段极少损害先前性能,并支持定制化超参数.
- Nemotron-Cascade-14B-Thinking在LiveCodeBench v5/v6分别取得78.0/74.8分,超越DeepSeek-R1-0528(74.8/73.3)和Gemini-2.5-Pro-06-05,同时在IOI 2025获得银牌.
- 统一版Nemotron-Cascade-8B缩小了与专用8B-Thinking模型的推理性能差距,在LiveCodeBench v5取得75.3分,与671B规模的DeepSeek-R1-0528持平.
- Nemotron-Cascade-14B-Thinking在SWE-bench Verified上达到43.1% pass@1,超越专用模型DeepSWE-32B(42.2%)和SWE-agent-LM-32B(40.2%).
- 采用72B奖励模型的RLHF最大化ArenaHard性能,在数学/代码基准上比小型奖励模型提升3%,同时保持响应简洁性.
- 温度1.0的代码RL通过降低冗余和提升token效率提升LiveCodeBench分数,8B/14B模型训练后增益3-4分.
- SWE RL结合生成-检索定位与无执行奖励,使14B模型实现43.1%解决率,并通过测试时扩展达到53.8% best@32.
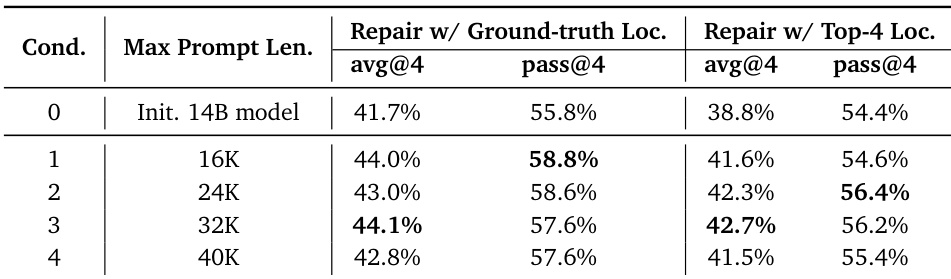
作者使用14B模型评估最大提示长度对代码修复性能的影响,发现性能在24K–32K提示长度达到峰值,40K时下降.使用真实文件定位时,模型在32K下取得44.1% avg@4和57.6% pass@4;前4检索定位在相同条件下达到42.7% avg@4和56.2% pass@4.结果表明更长提示在一定范围内提升修复能力,超出后噪声与上下文限制降低效果.
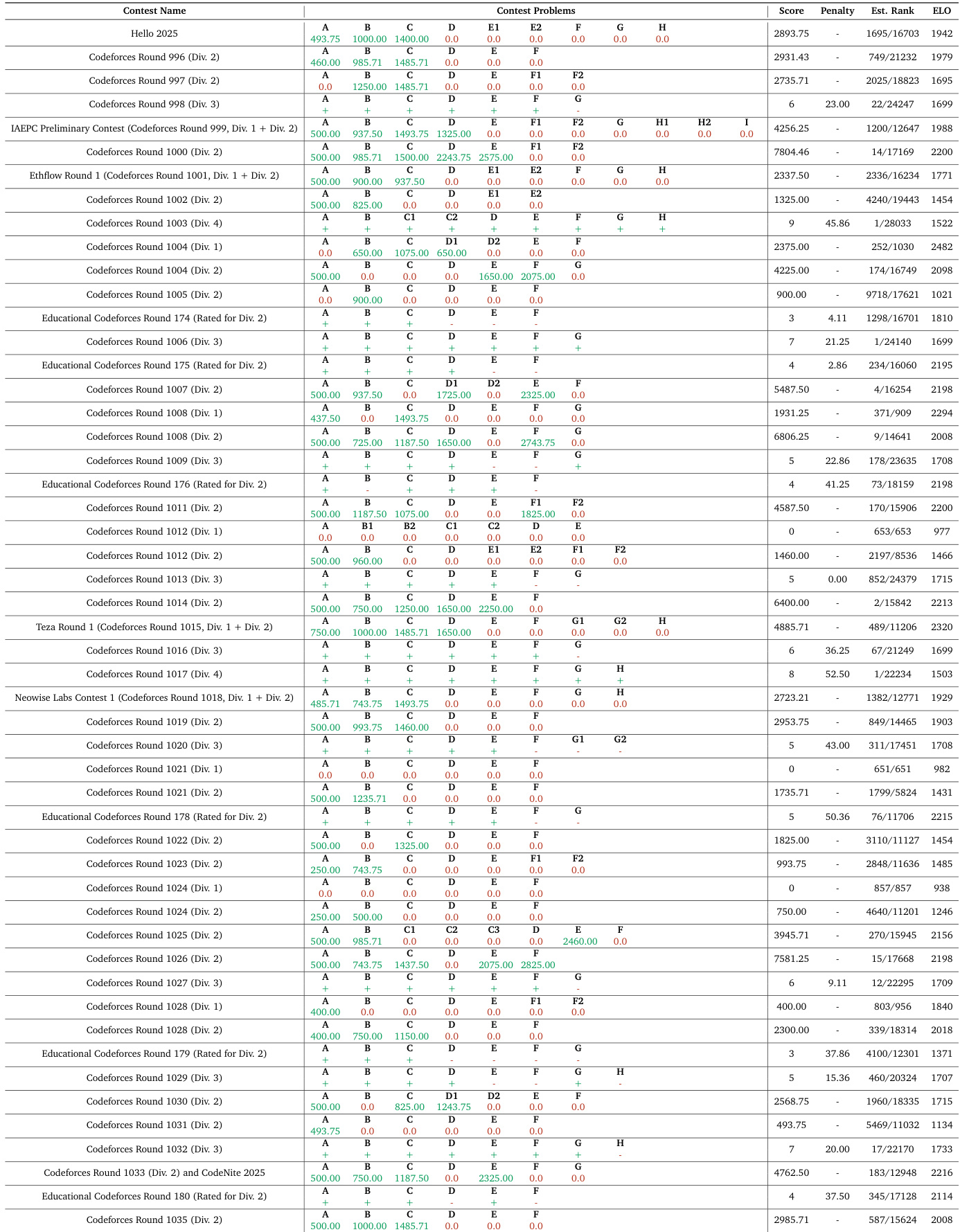
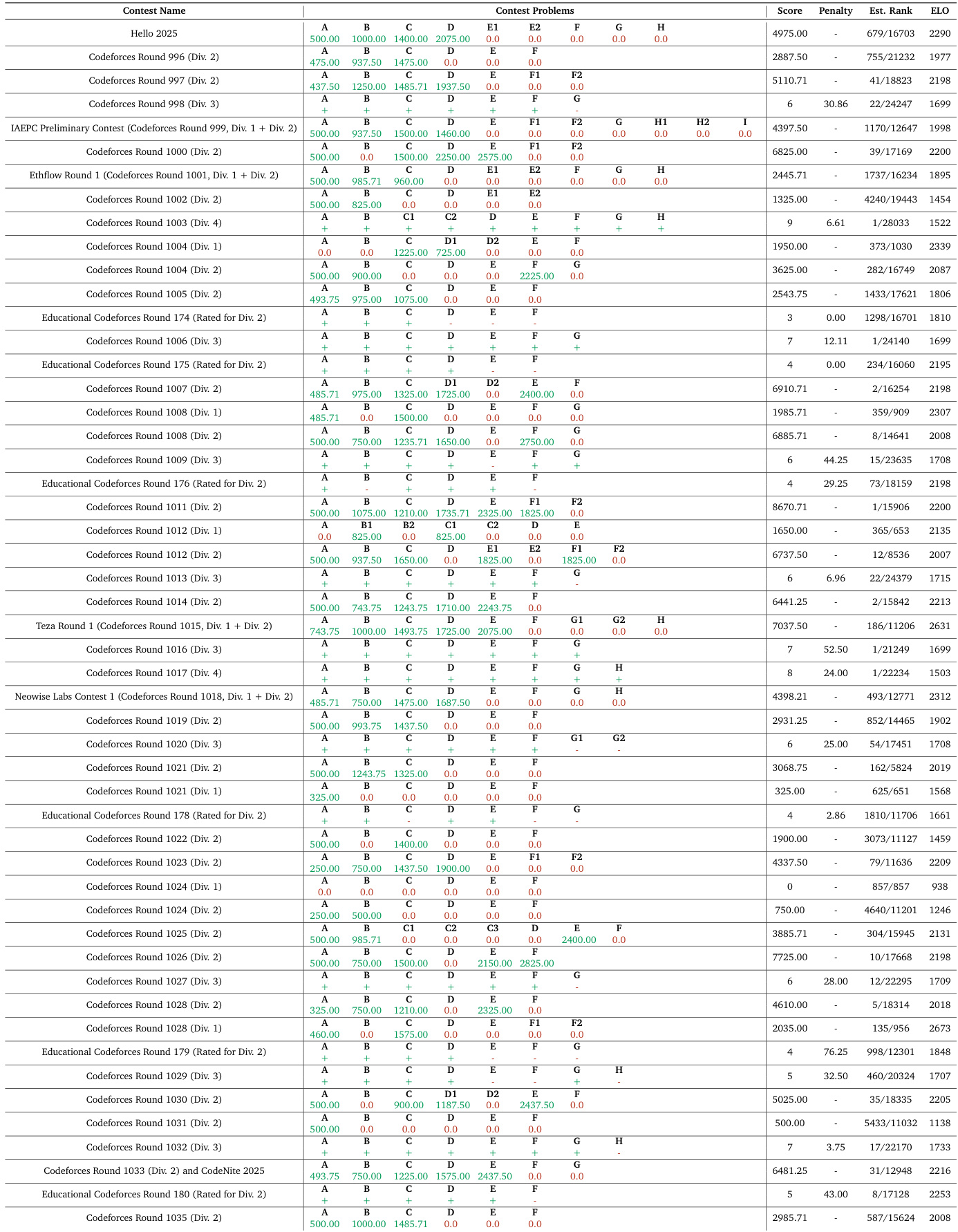
作者在系列竞赛编程比赛中评估Nemotron-Cascade模型,报告Codeforces及教育轮次中的分数、罚时和估计ELO评级.结果显示跨分区稳定表现,估计排名常位于参与者前20%–30%,ELO分数普遍在1500–2300区间,表明具备中级至高级竞争力.数据反映模型在竞赛条件下解决算法问题的能力,性能随轮次难度与问题集构成波动.
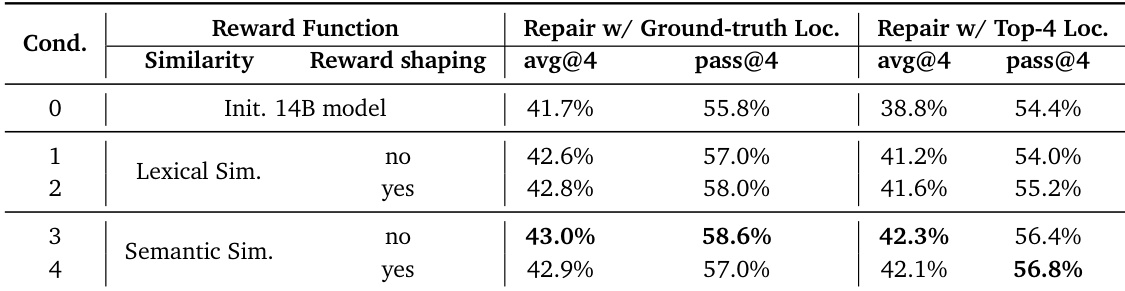
作者评估SWE RL的不同奖励函数,发现语义相似度比词法相似度产生更高修复准确率,尤其在提供真实文件定位时.奖励塑形在词法相似度下提升性能,但对语义相似度无额外增益,表明后者在低相似度分数下仍提供更可靠训练信号.
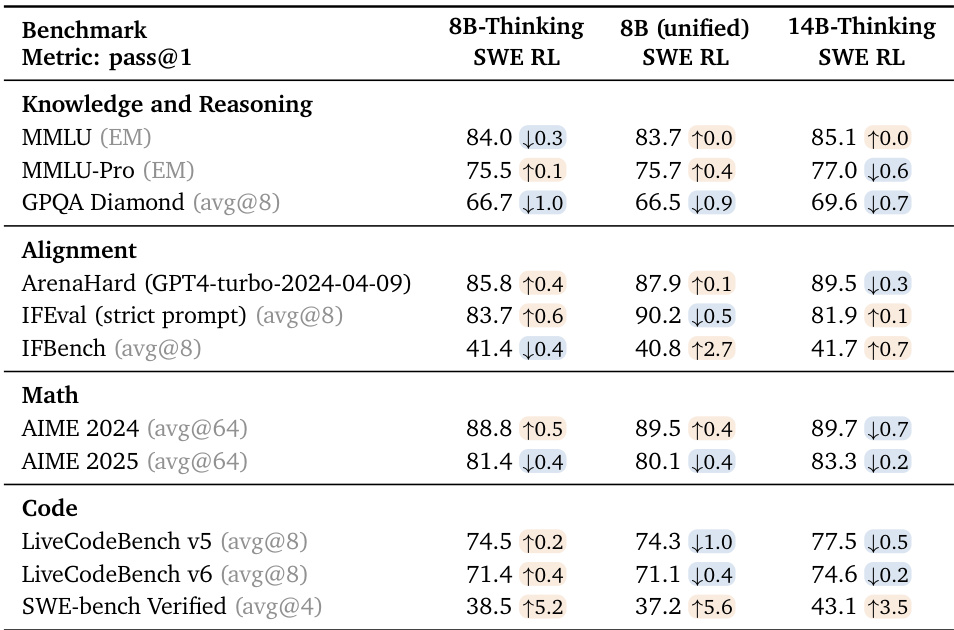
作者将SWE RL应用于8B和14B模型,在SWE-bench Verified上观察到显著提升,14B-Thinking模型达到43.1% pass@1,超越专用32B模型.代码和数学基准测试显示小幅波动(多在评估方差内),而对齐与知识基准保持稳定或略有提升.统一8B模型经SWE RL后在SWE任务上缩小了与专用8B-Thinking模型的性能差距,证明有效的跨领域迁移.
作者在系列Codeforces比赛中评估Nemotron-Cascade模型,报告多分区中的分数、罚时及估计排名.结果显示跨比赛稳定表现,分数范围0至7000+,估计排名常位于全球前2000.基于51场Codeforces比赛得出的1942 ELO分数,反映其在算法问题解决中与其他模型的竞争地位.