Command Palette
Search for a command to run...
LongVie 2:多模态可控超长视频世界模型
LongVie 2:多模态可控超长视频世界模型
Jianxiong Gao Zhaoxi Chen Xian Liu Junhao Zhuang Chengming Xu Jianfeng Feng Yu Qiao Yanwei Fu Chenyang Si Ziwei Liu
摘要
基于预训练视频生成系统构建视频世界模型,是迈向通用时空智能的重要 yet 挑战性步骤。一个理想的世界模型应具备三个核心特性:可控性、长期视觉质量以及时间一致性。为此,我们采用渐进式方法——首先提升模型的可控性,随后逐步拓展至长期、高质量的视频生成。本文提出 LongVie 2,一种端到端的自回归框架,通过三个阶段进行训练:(1)多模态引导阶段,融合密集与稀疏控制信号,提供隐式的全局世界级监督,显著增强模型的可控性;(2)基于输入帧的退化感知训练,缩小训练阶段与长期推理之间的差距,有效维持高质量的视觉表现;(3)历史上下文引导机制,通过对相邻视频片段之间的上下文信息进行对齐,确保生成内容的时间一致性。此外,我们还构建了 LongVGenBench,一个全面的基准测试集,包含100段高分辨率、时长为一分钟的视频,涵盖多样化的现实场景与合成环境。大量实验表明,LongVie 2 在长程可控性、时间连贯性与视觉保真度方面均达到当前最优水平,并支持长达五分钟的连续视频生成,标志着在统一视频世界建模方向上迈出了关键一步。
一句话总结
复旦大学、南洋理工大学与上海人工智能实验室的研究人员提出 LongVie 2,一种可生成可控 3–5 分钟视频的自回归视频世界模型。该模型引入多模态引导实现密集/稀疏控制,采用退化感知训练策略弥合训练-推理差距,并通过历史上下文建模确保时序一致性,在长程视频生成的保真度与可控性方面显著超越先前方法。
核心贡献
- LongVie 2 解决了当前视频世界模型的关键局限:在生成超过一分钟的视频时,语义级可控性受限且存在时序退化问题。它提出渐进式框架,将细粒度控制与长时稳定性统一,实现可扩展的世界建模。
- 该方法采用三阶段训练:融合密集与稀疏控制信号增强可控性,应用退化感知训练维持长时推理的视觉质量,利用历史上下文引导确保长序列时序一致性。这种端到端自回归框架系统性地弥合了短片段生成与分钟级连贯输出之间的鸿沟。
- 在 LongVGenBench(包含 100 个多样化高清一分钟视频的严格基准)上评估,LongVie 2 在可控性、时序连贯性与视觉保真度方面均达到最优结果,同时支持长达五分钟的连续生成,显著推动了统一视频世界模型的发展。
引言
近期如 Sora 和 Kling 等视频扩散模型实现了逼真的文本到视频生成,但研究重点已转向可模拟可控物理环境的视频世界模型,以应用于虚拟训练和交互式媒体。然而,现有世界模型存在语义级可控性不足(无法连贯操控整个场景)的问题,且因漂移和退化导致超过一分钟时难以维持视觉质量与时序一致性。作者通过将预训练扩散主干网络扩展为 LongVie 2 来解决此问题,该框架通过三个渐进阶段训练:多模态引导实现结构控制,退化感知训练弥合短片段与长时推理差距,历史上下文引导确保长程连贯性。该方法实现了分钟级可控视频生成,同时提出 LongVGenBench(包含 100 个一分钟视频的基准),用于严格评估长时保真度。
数据集
作者采用多阶段训练方法,使用不同数据集与处理流程:
-
组成与来源:
第 1–2 阶段在三个来源的约 6 万视频上训练:ACID/ACID-Large(海岸线/景观航拍)、Vchitect_T2V_DataVerse(1400 万+带文本标注的互联网视频)和 MovieNet(1,100 部完整电影)。第 3 阶段使用 OmniWorld 和 SpatialVID 的长视频进行时序建模。评估基准 LongVGenBench 包含多样化的 1+ 分钟、1080p+ 视频。 -
子集详情:
- 第 1–2 阶段数据:统一为 16 fps 的 81 帧片段。ACID 确保 RealEstate10K 兼容的元数据;MovieNet 提供复杂场景。
- 第 3 阶段数据:将长视频处理为从第 20 帧开始的 81 帧目标片段,使用所有前置帧作为历史上下文。训练集包含 4 万个随机选择的片段。
- LongVGenBench:分割为单帧重叠的 81 帧片段用于评估,每段均配对字幕与控制信号。
-
数据使用:
第 1–2 阶段在完整的 6 万视频语料库上训练。第 3 阶段 exclusively 使用带历史上下文的 4 万片段分割集。LongVGenBench 评估时,短片段字幕与控制信号指导推理。 -
处理细节:
所有训练视频经过严格预处理:通过 PySceneDetect 移除场景转换,得到无转换片段。每段以 16 fps 采样,截断至 81 帧,并增强深度图(Video Depth Anything)、点轨迹(SpatialTracker)和字幕(Qwen-2.5-VL-7B)。最终构建约 10 万视频-控制对的精选训练集。
方法
作者采用三阶段训练框架构建 LongVie 2,这是一种可生成可控、时序一致视频的自回归视频世界模型,支持长达 3–5 分钟的生成。该架构整合多模态控制信号、退化感知训练与历史上下文建模,弥合短片段训练与长时推理之间的差距。
如图所示,整体框架以输入图像及对应的密集(深度)和稀疏(点轨迹)控制信号为起点,提供世界级引导。这些模态通过改进的 DiT 主干网络处理,通过零初始化线性层将控制特征相加注入生成流,在保留预训练基础模型稳定性的同时实现细粒度条件控制。
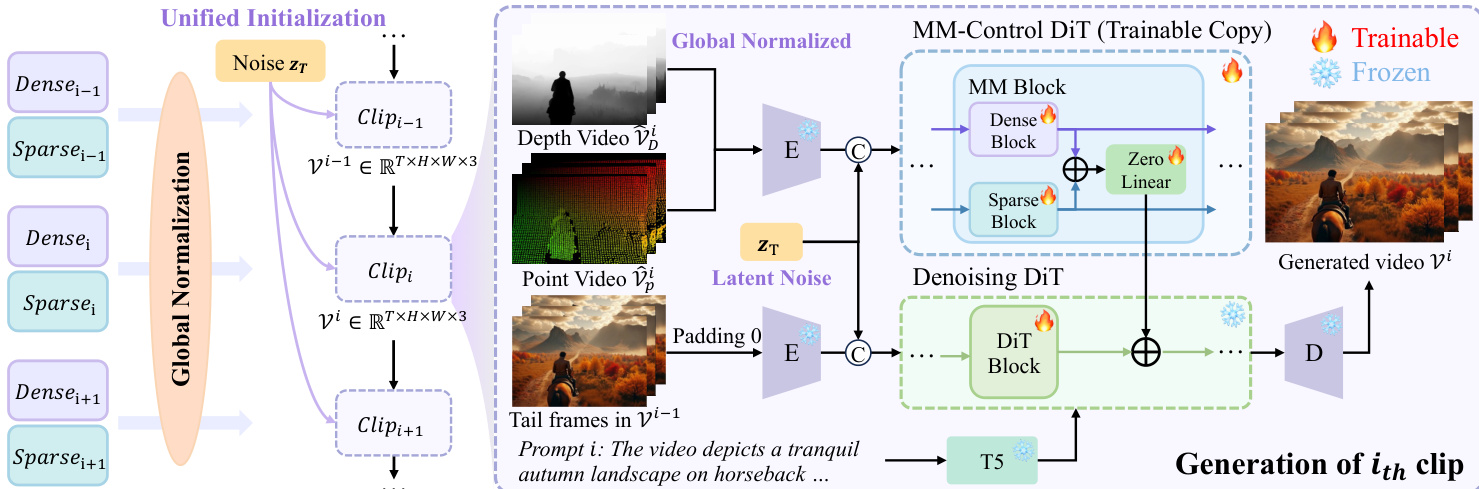
在阶段 I,模型通过标准 ControlNet 风格条件进行干净预训练初始化。作者通过复制预训练 Wan DiT 的前 12 层并拆分为两个可训练分支(分别处理密集控制 FD 和稀疏控制 FP)构建多模态控制 DiT。这些分支处理各自编码的控制信号 cD 和 cP,其输出通过零初始化线性层 ϕl 融入冻结的基础 DiT 流,确保不干扰预训练权重。第 l 层的计算定义为:
zl=Fl(zl−1)+ϕl(FDl(cDl−1)+FPl(cPl−1)), 其中 Fl 表示冻结的基础块。为防止密集信号主导,作者在训练中引入特征级和数据级退化。特征级退化以概率 α 将密集潜在表示按随机因子 λ∈[0.05,1] 缩放,将上述方程重写为:
zl=Fl(zl−1)+ϕl(λ⋅FDl(cDl−1)+FPl(cPl−1)). 为防止密集信号主导,作者在训练中引入特征级和数据级退化。特征级退化以概率 α 将密集潜在表示按随机因子 λ∈[0.05,1] 缩放,将上述方程重写为:
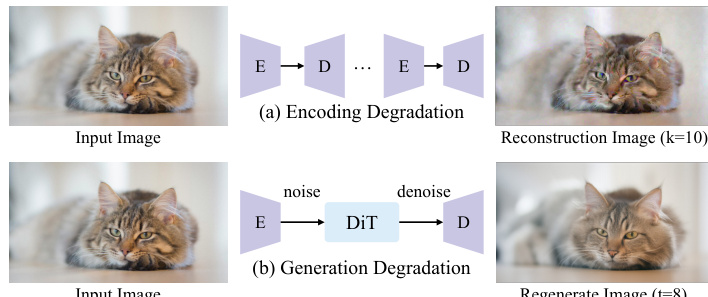
在阶段 II,作者通过引入首帧退化策略解决干净训练输入与退化推理输入之间的域差距。如图所示,应用两种退化机制:编码退化(通过 K 次重复编解码模拟 VAE 诱导的失真)和生成退化(在随机时间步 t<15 向潜在表示添加高斯噪声后去噪)。退化算子 T(I) 定义为:
T(I)={(D∘E)K(I)D(Φ0(αtE(I)+1−αtϵ))w.p. 0.2w.p. 0.8, 其中 ϵ∼N(0,I)。该退化在训练中以概率 α 应用,较温和的退化更频繁出现,以模拟长时生成中观察到的渐进质量衰减。
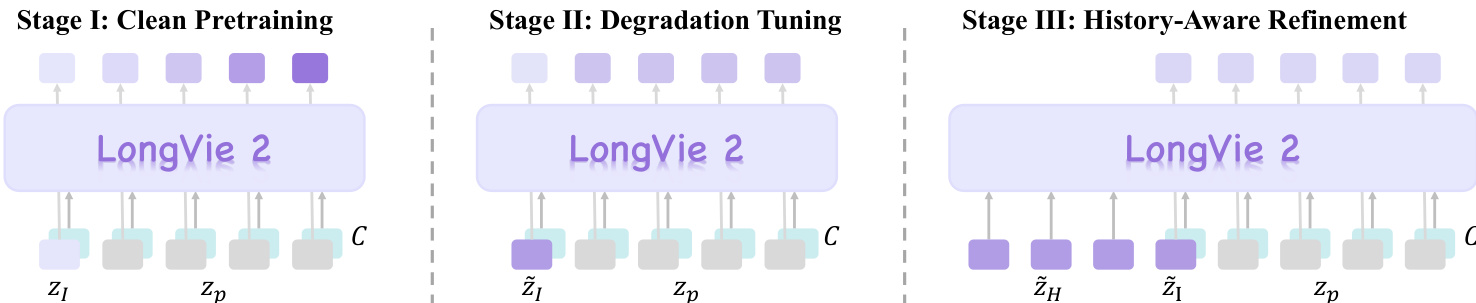
在阶段 III,模型通过历史上下文引导进行优化,以确保片段间的时序一致性。作者使用 VAE 编码器 E(⋅) 将前一片段最后 NH 帧编码至潜在空间,对这些帧应用相同退化算子 T(⋅),再编码退化版本得到 z~H. 模型训练目标为在初始帧潜在 zI、历史潜在 z~H 及控制信号 cD 和 cP 条件下生成下一片段,公式化为:
zt=F(zt+1∣zI,zH,cD,cP). 为稳定片段边界,作者对前三生成帧分配指数递增权重,并引入三个正则化损失:历史上下文一致性 Lcons=∥zH−1−z^0∥2、退化一致性 Ldeg=∥Flp(z~I0)−Flp(z^0)∥2 和真实高频频对齐 Lgt=∥Fhp(zgt0)−Fhp(z^0)∥2。最终时序正则化目标为:
Ltemp=λdegLdeg+λgtLgt+λconsLcons, 其中 λdeg=0.2,λgt=0.15,λcons=0.5。此外,基础模型的自注意力层更新以捕获因果依赖,NH 从 [0, 16] 均匀采样以支持灵活推理。
如图所示,训练流程从干净预训练逐步过渡到退化调优,最终实现历史感知优化,每个阶段在前一阶段基础上增强可控性、视觉保真度与时序连贯性。
推理阶段,作者采用两种无需训练的策略进一步提升片段间一致性:统一噪声初始化(跨所有片段维护单一共享噪声潜在变量)和深度图全局归一化(计算整个视频的全局 5% 和 95% 百分位确保深度缩放一致)。点轨迹使用全局归一化深度按片段重新计算,以保持运动引导稳定性。字幕通过 Qwen-2.5-VL-7B 优化,与生成帧的视觉内容对齐,确保序列语义一致性。
实验
- LongVie 2 在 LongVGenBench(100 个高清视频)上验证,所有 VBench 指标(可控性、时序连贯性、视觉保真度)均达到最优,超越预训练模型(Wan2.1)、可控模型(VideoComposer, Go-with-the-Flow)和世界模型(Hunyuan-GameCraft)。
- 60 名参与者的主观评估证实,LongVie 2 在所有维度(视觉质量、提示一致性、条件一致性、色彩一致性、时序一致性)上均持续优于基线。
- 扩展生成测试证明其可合成连贯的 5 分钟视频,同时在多样化真实与合成场景中保持结构稳定性、运动一致性和风格适应性。
- 消融研究证实三个训练阶段的必要性:控制学习增强可控性,退化感知训练提升视觉质量,历史上下文引导确保长期时序一致性。
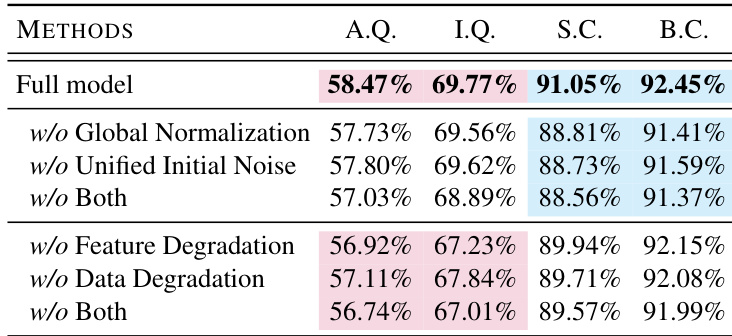
作者通过移除全局归一化、统一初始噪声和退化策略等关键组件进行 LongVie 2 消融评估,表明每项均对视觉质量与时序一致性有贡献。结果表明移除任一组件均会导致美学质量、成像质量、主体一致性和背景一致性的可测量下降。完整模型在所有指标上得分最高,证实集成设计的必要性。
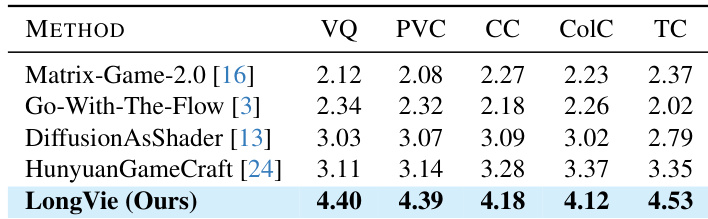
作者在五项感知维度(包括视觉质量与时序一致性)上对 LongVie 2 与多个基线进行主观评估。结果显示 LongVie 2 在所有类别中得分最高,优于 Matrix-Game-2.0、Go-With-The-Flow、DiffusionAsShader 和 HunyuanGameCraft。这证明其在长视频生成中具有卓越的感知质量与可控性。
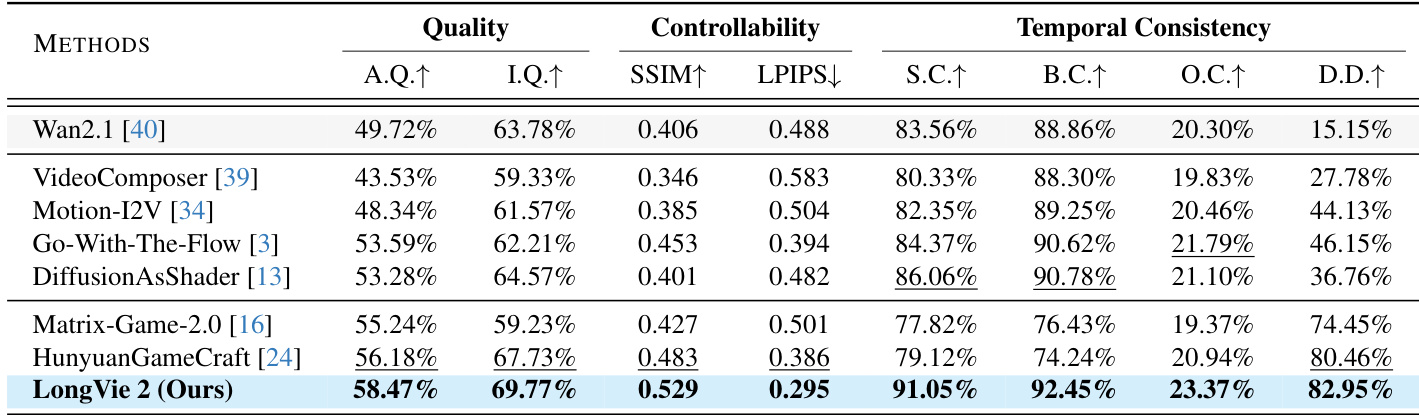
作者在 LongVGenBench 上对 LongVie 2 与多个基线进行评估,测量视觉质量、可控性和时序一致性。结果显示 LongVie 2 在美学质量、成像质量、SSIM 和主体一致性方面得分最高,同时在背景一致性和动态程度方面领先。这些指标证实 LongVie 2 在生成长时、可控且时序连贯视频方面的卓越性能。
作者采用分阶段训练策略逐步增强 LongVie 2,每个阶段均提升视觉质量、可控性和时序一致性。结果显示添加历史上下文在所有指标上带来最高增益,尤其在美学质量、成像质量和时序连贯性方面。最终模型通过整合多模态引导、退化感知训练和历史上下文对齐实现最优性能。

作者评估退化策略对 LongVie 2 性能的影响,表明同时添加编码和生成退化可提升所有指标:视觉质量、可控性和时序一致性。结果显示组合两种退化类型在美学质量、成像质量、SSIM、LPIPS 及所有时序一致性度量上均获得最高分。这证实退化感知训练增强了模型在长视频生成中维持保真度与连贯性的能力。
