Command Palette
Search for a command to run...
代码的缩放定律:每种编程语言都至关重要
代码的缩放定律:每种编程语言都至关重要
摘要
代码大语言模型(Code LLMs)虽然功能强大,但其训练成本高昂。现有的缩放定律(scaling laws)能够基于模型规模、数据量和计算资源预测模型性能。然而,在预训练过程中,不同编程语言(Programming Languages, PLs)的影响各不相同,显著影响基础模型的性能表现,导致现有预测方法存在偏差。此外,现有研究大多局限于语言无关(language-agnostic)的设定,忽视了现代软件开发本质上具有多语言特性这一事实。因此,亟需首先系统研究各类编程语言的缩放规律,进而分析它们之间的相互影响,最终构建适用于多语言场景的综合缩放定律。本文首次对多语言代码预训练的缩放规律进行了系统性探索,覆盖超过1000次实验(相当于336,000多个H800 GPU小时),涵盖多种编程语言、模型规模(从0.2B到14B参数)以及数据集规模(达1万亿token)。我们建立了跨多种编程语言的代码大模型完整缩放定律,发现解释型语言(如Python)在模型规模和数据量增加时所获收益,显著高于编译型语言(如Rust)。研究还表明,多语言预训练能带来协同增益,尤其在语法结构相似的编程语言之间(如JavaScript与TypeScript)表现更为突出。此外,采用并行配对策略(即拼接代码片段及其对应翻译版本)进行预训练,显著提升了模型的跨语言能力,且具备良好的缩放特性。最后,本文提出一种依赖比例的多语言缩放定律,通过优先分配高价值编程语言(如Python)、平衡高协同效应的语言对(如JavaScript与TypeScript),并减少对快速饱和语言(如Rust)的资源投入,实现了在相同计算预算下,相较于均匀分配策略,所有编程语言上均取得更优的平均性能表现。
一句话总结
来自北京航空航天大学、优必选和中国人民大学的研究人员提出了一种比例依赖的多语言代码大语言模型(Code LLM)缩放定律,揭示了不同编程语言的特定缩放行为及其在语法相似语言间的协同效应,从而在固定计算资源下实现最优的令牌分配以提升跨语言性能。
主要贡献
- 我们通过1000余次实验首次建立了代码大语言模型的多语言缩放定律,发现如Python等解释型语言在模型规模和数据量上的缩放表现优于Rust等编译型语言,挑战了先前研究中语言无关的假设。
- 我们识别出多语言预训练过程中的跨语言协同增益,尤其在语法相似的语言之间,并证明并行配对(将代码与其翻译串联)可增强跨语言迁移能力,同时保持良好的缩放特性。
- 我们提出了一种比例依赖的缩放定律,通过优先分配高效益语言(如Python)、平衡高协同配对(如JavaScript-TypeScript)、减少快速饱和语言(如Rust)的令牌,实现在固定计算预算下优于均匀分配的平均性能。
引言
作者通过大规模实证分析揭示了编程语言多样性如何影响代码大语言模型的缩放行为,填补了先前研究将代码预训练视为语言无关的关键空白。现有的代码缩放定律忽略了不同语言(如Python与Rust)在模型规模和数据量增加时的不同响应,导致资源分配次优和性能预测不准确。他们的主要贡献是基于1000余次实验推导出的比例依赖多语言缩放定律,揭示了解释型语言随数据和参数增加表现更好、语法相似语言存在跨语言协同效应、代码翻译并行配对可提升跨语言性能。该框架支持在固定计算预算下跨语言的最优令牌分配,通过优先高效益或高协同语言、减少快速饱和语言的资源,提升平均性能。
数据集

作者使用以Python为中心的多语言编程语言数据集,并配对六种目标语言:Java、JavaScript、TypeScript、C#、Go和Rust。数据组成及使用方式如下:
-
数据集组成:
- 9000亿令牌的算法等效代码,覆盖7种语言,仅Python ↔ 各目标语言为并行配对(无非Python ↔ 非Python直接配对)。
- 增补1000亿令牌来自FineWeb-Edu用于自然语言理解,总计1万亿令牌。
- 评估集:从GitHub精选50个Python文件,由工程师手动翻译为6种目标语言,生成2100个翻译实例(全部42个方向),平均每样本464令牌。
-
关键子集细节:
- 训练数据仅包含以Python为中心的并行配对(12个方向:6个输入Python,6个从Python输出)。
- 无任何非Python ↔ 非Python方向的训练数据——这些方向以零样本方式评估。
- 评估集经人工筛选,确保语义等效性及算法任务多样性。
-
数据使用方式:
- 模型在完整1万亿令牌语料(9000亿代码 + 1000亿自然语言)上训练一个epoch。
- 测试三种预训练策略:(1) 单语言预训练,(2) 在已见翻译方向上训练,(3) 在Python为中心配对上训练后在未见方向上零样本评估。
- 使用翻译损失评估:−E[log P(y|x)],其中y为目标代码,x为源代码。
-
处理与缩放:
- 模型参数规模从0.1B到3.1B,训练令牌预算从2B到64B。
- 在两种数据组织范式下测试五种模型规模(0.2B、0.5B、1.5B、3B、7B)。
- 未提及裁剪或元数据构建——数据按原序列长度使用。
方法
作者利用比例依赖的多语言缩放定律建模大语言模型在多语言环境下的性能,解决传统缩放定律将多语言数据视为同质的局限。他们明确将语言比例 p=(p1,…,pK) 引入缩放框架,其中每个 pk 代表语言 k 的训练数据占比。整体缩放定律表达为:
L(N,D;p)=A⋅N−αN(p)+B⋅Dx−αD(p)+L∞(p)其中,N 表示模型参数数量,D 为总训练数据量,L 代表模型损失。指数 αN(p) 和 αD(p),以及渐近损失 L∞(p),均为语言特定参数的加权平均值。具体而言,αN(p)=∑kpkαNk,αD(p)=∑kpkαDk,L∞(p)=∑kpkL∞k,其中 αNk、αDk 和 L∞k 为语言 k 的缩放参数。此公式使模型可根据训练混合中各语言的相对贡献调整其缩放行为。
为考虑跨语言迁移效应,有效数据量 Dx 定义为:
Dx=Dall1+γLi=Lj∑pLipLjτij其中 Dall 为所有语言的总训练数据量,γ 为缩放因子,τij 为语言 Li 与 Lj 之间的迁移系数,由实证观察得出。该术语捕捉一种语言的数据如何提升另一种语言的性能,反映多语言环境下语言间的相互依赖性。该框架因此支持在语言比例变化时更细致地理解模型性能随数据和参数的缩放行为。
实验
- 建立了7种编程语言的特定缩放定律:解释型语言(如Python)的缩放指数高于编译型语言(如Rust),不可约损失排序为 C# < Java ≈ Rust < Go < TypeScript < JavaScript < Python,反映语法严格性和可预测性。
- 展示了多语言协同效应:多数编程语言从混合预训练中受益,尤其是语法相似的配对(如Java-C#验证损失降低20.5%);Python作为目标语言时提升有限,但作为辅助语言可提升其他语言。
- 评估跨语言策略:并行配对(显式代码-翻译对齐)在已见和未见翻译方向上均显著优于打乱基线(如BLEU分数提升,零样本损失降至0.0524),高缩放指数(α=6.404)支持高效利用模型容量。
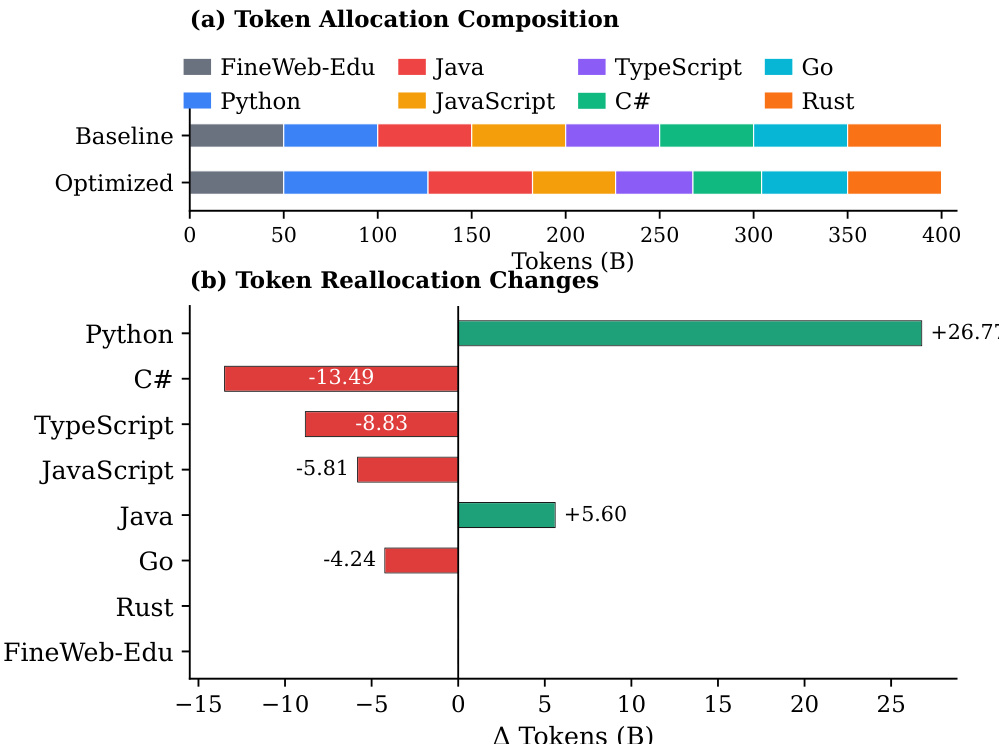
- 提出比例依赖的多语言缩放定律:优化令牌分配(更多分配给高αD语言如Python,平衡高协同配对如JavaScript-TypeScript,减少快速饱和语言如Rust)在固定4000亿令牌预算下实现所有编程语言更高的平均Pass@1和BLEU分数,且无单一语言性能下降。
- 确认数据缩放在所有编程语言中比模型缩放带来更大收益,各语言收敛速度和固有难度不同。
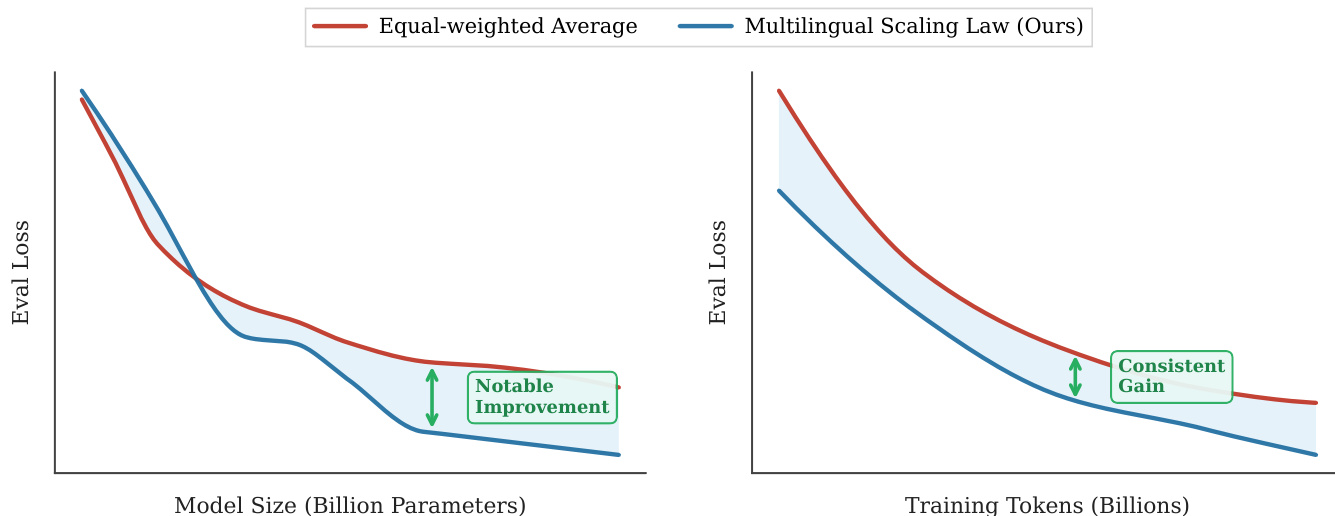
作者使用多语言代码生成基准测试两种训练策略——均匀分配与优化分配——在15亿参数模型上。结果表明,优化分配在所有编程语言上实现更高平均性能,且无任何单一语言显著退化,证明基于缩放定律和语言协同的策略性重分配在相同计算预算下优于均匀分布。
作者使用比例依赖的多语言缩放定律优化编程语言间的令牌分配,根据语言特定缩放指数、协同增益和不可约损失重新分配令牌。结果表明,优化策略增加高效益语言(如Python)和高协同配对(如JavaScript-TypeScript)的令牌,减少快速饱和语言(如Go)的令牌,在所有语言上实现更高平均性能,且无任何单一语言显著退化。
作者使用协同增益矩阵分析预训练期间混合不同编程语言的影响,发现语法或结构相似的语言(如Java和C#)表现出显著的正向迁移,而混合Python与其他语言常导致负干扰。结果表明,多语言预训练对大多数编程语言有益,但收益不对称且取决于具体语言配对,Java-C#和JavaScript-TypeScript组合提升最显著。

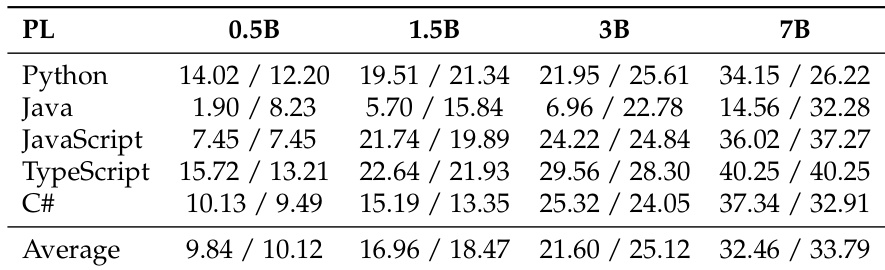
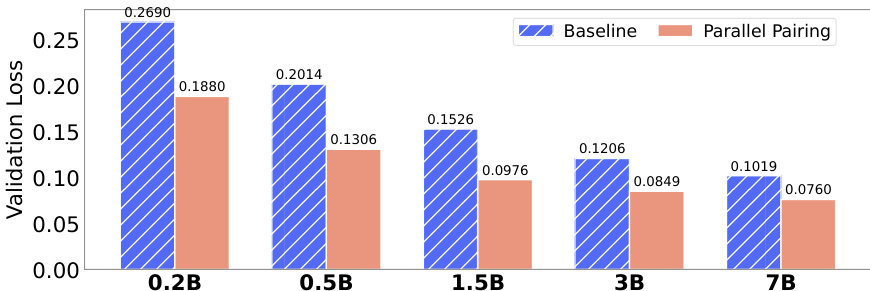
作者比较了两种多语言代码预训练的数据组织策略,表明并行配对在所有模型规模下显著降低验证损失。结果证明,并行配对比随机打乱实现更低验证损失,且差距随模型规模增长而扩大,表明更高效利用模型容量进行跨语言对齐。
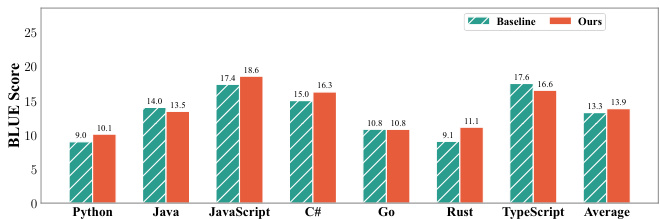
作者比较了两种多语言代码预训练的数据分配策略:基线为均匀令牌分布,优化策略基于缩放定律和协同增益。结果表明,优化策略在所有编程语言上实现更高BLEU分数,尤其在高协同配对和受益于更多数据的语言中提升显著,同时在令牌分配减少的语言中保持强性能。