Command Palette
Search for a command to run...
KlingAvatar 2.0 技术报告
KlingAvatar 2.0 技术报告
摘要
近年来,Avatar视频生成模型取得了显著进展。然而,现有方法在生成长时长、高分辨率视频时仍存在效率低下问题,随着视频长度增加,容易出现时间漂移、画质下降以及指令跟随能力弱等缺陷。为应对这些挑战,我们提出KlingAvatar 2.0,一种时空级联框架,能够在空间分辨率和时间维度上实现逐步上采样。该框架首先生成低分辨率的蓝图视频关键帧,以捕捉全局语义与运动信息;随后,通过“首尾帧”策略对关键帧进行精细化处理,将其重构为高分辨率、时间连贯的子片段,同时在长视频中保持平滑的时间过渡。为增强长视频中跨模态指令的融合与对齐能力,我们引入了一个协同推理导演(Co-Reasoning Director),该模块由三个模态专用的大语言模型(LLM)专家组成。这些专家分别对不同模态的优先级进行推理,并推断用户潜在意图,通过多轮对话将输入转化为详细的故事线。此外,我们还设计了一个负向导演(Negative Director),用于进一步优化负面提示,提升指令对齐精度。基于上述组件,我们进一步扩展框架以支持特定身份的多角色控制。大量实验表明,我们的模型有效解决了高效、多模态对齐的长时长高分辨率视频生成难题,在视觉清晰度、唇齿渲染的真实性与精确的唇形同步、身份一致性保留以及多模态指令遵循能力等方面均表现出显著优势。
一句话总结
快手科技Kling团队提出KlingAvatar 2.0,该时空级联框架通过首尾帧条件约束优化低分辨率蓝图关键帧,生成长时高清虚拟形象视频以消除时序漂移。其协同推理指挥器采用多模态大语言模型专家实现精准跨模态指令对齐,支持身份保持的多角色合成与精确口型同步,适用于教育、娱乐及个性化服务场景。
核心贡献
- 当前语音驱动虚拟形象生成系统在长时高清视频生成中面临挑战:尽管通用视频扩散模型取得进展,但视频时长增加会导致时序漂移、质量退化及提示遵循能力减弱。
- KlingAvatar 2.0引入时空级联框架:先生成捕捉全局运动与语义的低分辨率蓝图关键帧,再通过首尾帧策略将其精炼为高清子片段,确保长视频中的时序连贯性与细节保真度。
- 协同推理指挥器采用三个模态专用大语言模型专家,通过多轮对话协同推断用户意图,将输入转化为分层叙事结构,同时优化负向提示以增强跨模态指令对齐与长视频保真度。
引言
视频生成技术通过扩散模型与DiT架构结合3D VAE实现时空压缩,虽能生成高保真视频,但仍局限于文本或图像提示而缺乏音频条件控制。现有虚拟形象系统或依赖中间运动表征(如关键点),或缺乏语音驱动数字人的长时连贯性与表情控制能力。本文提出的KlingAvatar 2.0通过多模态大语言模型推理实现分层叙事规划,结合时空级联管线生成具有精细表情与环境交互能力的连贯长时音频驱动虚拟形象视频。
方法
本方法采用时空级联框架生成长时高清虚拟形象视频,实现精准口型同步与多模态指令对齐。管线始于协同推理指挥器:三个模态专用大语言模型专家通过多轮对话处理输入模态(参考图像、音频、文本),联合推断用户意图、解决语义冲突,输出包含正负向提示的结构化全局/局部叙事,指导下游生成。如框架图所示,指挥器输出进入分层扩散级联:首先由低分辨率视频DiT生成捕捉全局运动与布局的蓝图关键帧;再由高分辨率视频DiT提升空间细节,同时保持身份特征与构图。随后,低分辨率扩散模型采用首尾帧条件策略,结合蓝图上下文将高清关键帧扩展为音频同步子片段,精炼运动与表情。音频感知插值模块合成中间帧确保时序平滑与口型-音频对齐。最终高分辨率视频DiT对子片段执行超分辨率处理,输出时序连贯的高保真视频片段。
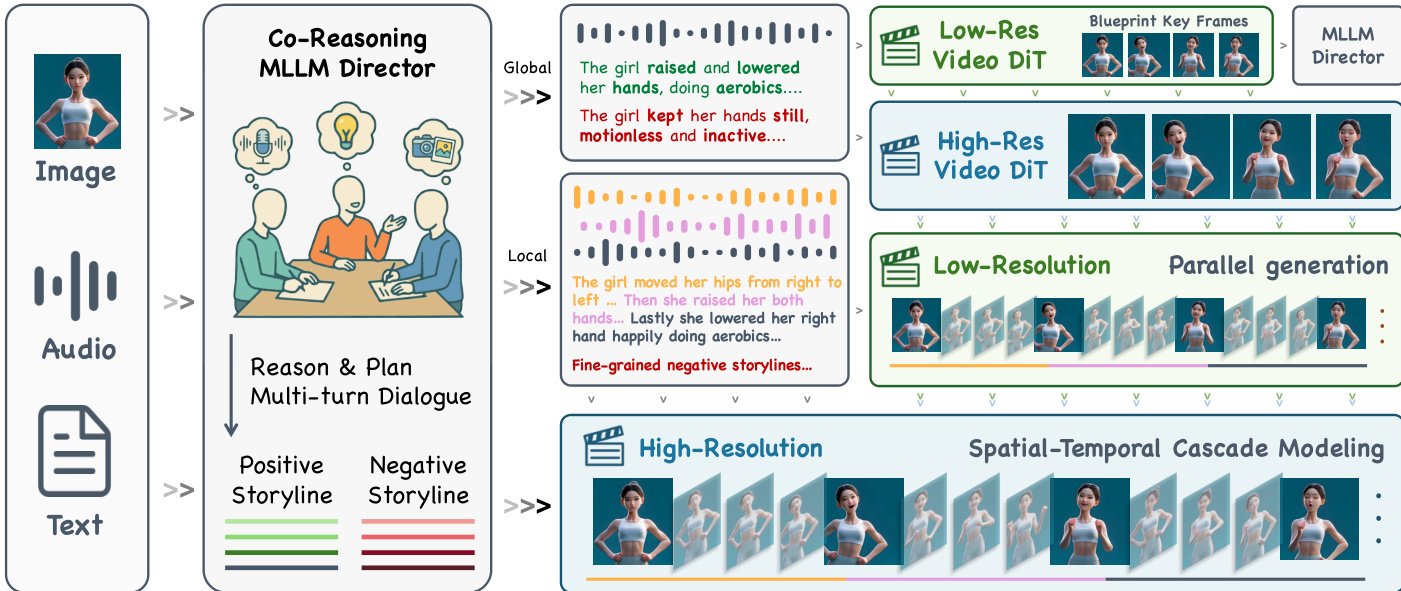
为支持多角色场景的身份专属音频控制,作者在人体视频DiT深层附加掩码预测头。这些深层特征呈现与角色对应的空域连贯区域,实现精准音频注入。推理时,参考身份裁剪图编码后与视频隐变量交叉注意力,回归逐帧角色掩码,将角色专属音频流注入对应空间区域。训练中DiT主干冻结,仅优化掩码预测模块。数据构建采用自动化标注管线:YOLO检测首帧角色,DWPose估计关键点,SAM2以边界框与关键点为提示跨帧分割跟踪人物,最终掩码经逐帧检测与姿态估计验证确保质量。如图所示,该架构在维持时空一致性的同时实现多角色细粒度控制。

实验
- 通过轨迹保持蒸馏与定制时间调度器加速视频生成,在推理效率与生成性能上验证提升,其稳定性与灵活性超越分布匹配方法。
- 基于300个多样化测试案例(中英文语音、歌唱)的人类偏好评估显示,本模型在运动表现力与文本相关性等维度显著优于HeyGen、Kling-Avatar和OmniHuman-1.5。
- 生成视频展现更自然的头发动力学、精准的镜头运动对齐(如按提示正确折叠双手)及情感连贯的表情,逐镜头负向提示相比基线通用伪影控制提升了时序稳定性。
结果表明KlingAvatar 2.0在整体偏好及多数子类别上均优于所有基线模型,尤其在运动表现力与文本相关性方面优势显著。相比Kling-Avatar,本模型在运动表现力(2.47分)与文本相关性(3.73分)取得最高分,印证其更优的多模态指令对齐能力与丰富动态表达。视觉质量与运动质量也持续领先,仅面部-口型同步得分与基线接近。
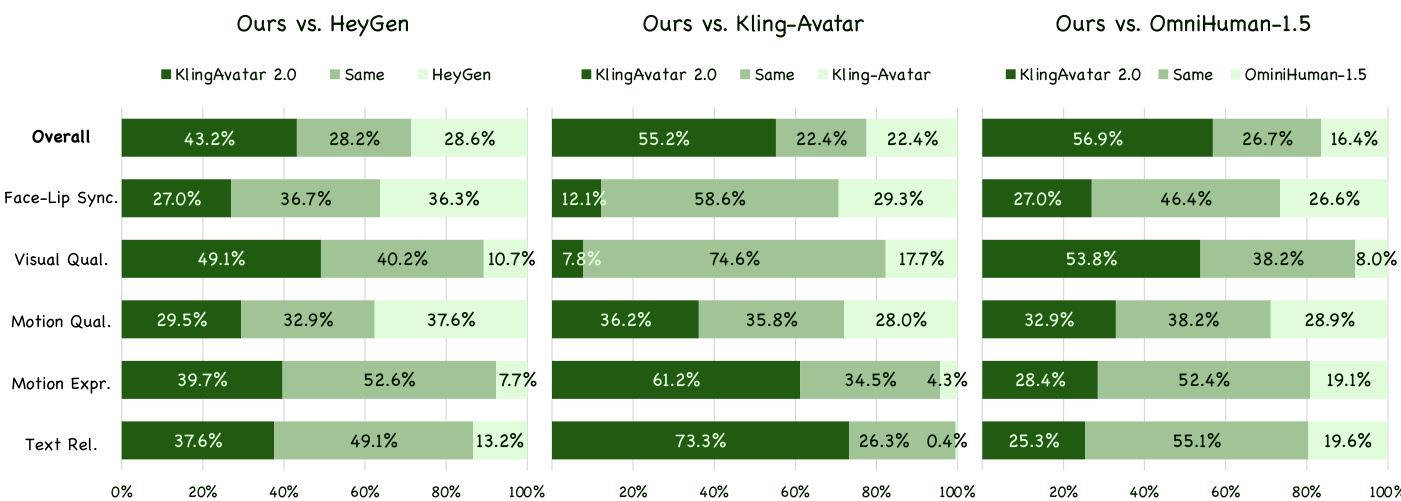
结果表明KlingAvatar 2.0在整体偏好及多数子类别上均优于所有基线模型,尤其在运动表现力与文本相关性方面优势显著。相比Kling-Avatar,本模型在运动表现力(2.47分)与文本相关性(3.73分)取得最高分,印证其更优的多模态指令对齐能力与丰富动态表达。视觉质量与运动质量也持续领先,仅面部-口型同步得分与基线接近。
