Command Palette
Search for a command to run...
QwenLong-L1.5:长上下文推理与记忆管理的后训练方案
QwenLong-L1.5:长上下文推理与记忆管理的后训练方案
摘要
我们推出了QwenLong-L1.5,该模型通过系统性的后训练创新,实现了卓越的长上下文推理能力。QwenLong-L1.5的核心技术突破如下:(1)长上下文数据合成流水线:我们构建了一套系统化的数据合成框架,能够生成需要在全局分布证据上进行多跳推理的高挑战性任务。通过将文档解构为原子事实及其内在关联,并程序化地组合可验证的推理问题,该方法可大规模生成高质量训练数据,显著超越了传统检索类任务的范畴,真正实现了长距离推理能力的构建。(2)面向长上下文训练的稳定强化学习机制:为解决长上下文强化学习中的关键不稳定性问题,我们引入了任务均衡采样策略,并结合任务特定的优势估计方法,有效缓解了奖励偏差问题;同时提出自适应熵控制策略优化(Adaptive Entropy-Controlled Policy Optimization, AEPO),动态调节探索与利用之间的权衡,显著提升了训练稳定性与模型性能。(3)面向超长上下文的记忆增强架构:鉴于即使扩展上下文窗口也无法容纳任意长度序列的局限性,我们设计了一种多阶段融合强化学习训练的记忆管理框架,实现了单次遍历推理与迭代式基于记忆处理的无缝集成,从而支持超过400万token的超长任务处理。基于Qwen3-30B-A3B-Thinking架构,QwenLong-L1.5在长上下文推理基准测试中表现媲美GPT-5与Gemini-2.5-Pro,相较其基线模型平均提升9.90分。在超长任务(100万至400万token)场景下,其记忆代理框架相较基线代理模型实现9.48分的显著提升。此外,该模型所具备的长上下文推理能力也有效迁移至通用领域,显著提升了科学推理、记忆工具使用以及长对话等任务的表现。
一句话总结
阿里巴巴通义实验室推出QwenLong-L1.5,该模型采用创新的长上下文数据合成流程实现多跳推理,通过自适应熵控制策略优化(AEPO)的任务平衡强化学习确保训练稳定性,并采用支持高达400万token上下文的记忆增强架构。在长上下文基准测试中,其平均性能超越基线模型9.9分,同时显著提升科学推理与长对话能力。
核心贡献
- 针对先前长上下文模型依赖简单检索任务而非真实多跳推理的局限,作者提出系统化数据合成流程:将文档解构为原子事实,并程序化生成需全局分布证据支持的可验证推理问题,从而实现复杂长距离推理的可扩展训练。该方法突破基础检索范畴,生成直接针对高难度推理场景的高质量合成数据。
- 为解决长上下文强化学习中的关键不稳定性问题,该方法提出任务平衡采样(结合任务特定优势估计)与自适应熵控制策略优化(AEPO),动态调节探索-利用权衡并缓解奖励偏差。这些技术使模型能在渐进增长长度的序列上稳定训练,攻克了扩展长上下文能力的核心障碍。
- 针对固有上下文窗口限制,本研究开发了记忆增强架构,通过多阶段融合强化学习训练整合单次推理与迭代式基于记忆的处理流程,支持超过400万token的超长上下文。基准测试表明,该框架在100万–400万token任务上比智能体基线平均提升9.48分,同时在标准长上下文推理任务中达到与GPT-5和Gemini-2.5-Pro相当的性能。
引言
在法律文档分析或科学研究等真实应用场景中,处理长上下文推理至关重要——模型需在保持连贯推理和内存效率的同时处理海量输入。先前方法存在数据多样性不足(过度依赖纯文本输入和短输出)及强化学习不稳定性问题(因对整个推理步骤进行粗粒度奖励分配导致训练动态脆弱)。作者推出QwenLong-L1.5,其自动化数据合成流程专为复杂长输入任务设计,配合AEPO这一改进型强化学习算法:通过梯度裁剪实现更细粒度的推理轨迹内奖励分配,从而稳定训练过程。
数据集
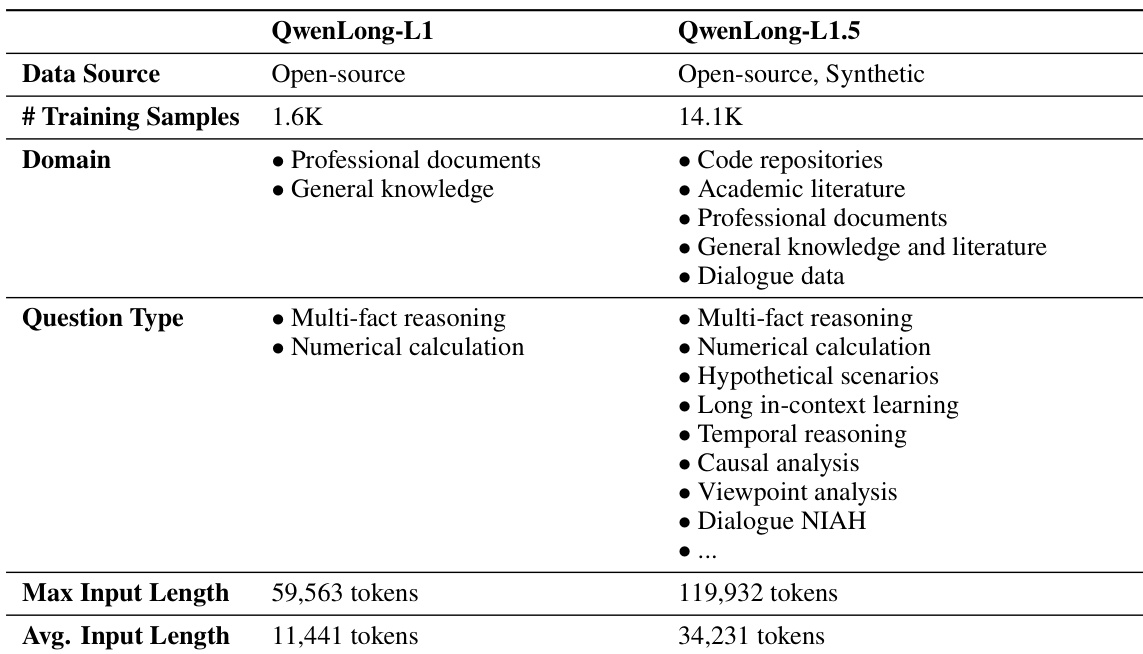
作者为QwenLong-L1.5构建了合成式长上下文强化学习数据集,采用三阶段流程开发:
-
构成与来源:
基于五类共82,175份高质量长文档(92亿token)构建:
• 代码仓库(高星标Python项目)
• 学术文献(STEM、医学、法律、arXiv论文)
• 专业文档(财务报告、手册、政府出版物)
• 通用知识(小说、维基百科)
• 模拟多轮对话 -
关键子集细节:
• 初始池:42.7k合成问答对
• 最终训练集:经严格过滤后保留14.1k样本
• 过滤规则:- 知识锚定检查:剔除无需上下文即可回答的样本(测试内部知识依赖性)
- 上下文鲁棒性检查:移除添加无关文档后答案失效的样本
• 复杂度增强:64K token以上样本数量较先前版本显著增加
-
数据用途:
• 仅用于强化学习训练(未描述独立验证/测试集划分)
• 未指定混合比例,但强调领域多样性:多跳推理、数值计算、时序分析、观点分析及对话记忆 -
处理策略:
• 上下文扩展:策略性插入无关文档以强制实现稀疏信息检索
• 难度分级:利用知识图谱/表格及多智能体自进化生成高难度问题
• 去污染:应用多阶段去重与测试集清洗
• 质量控制:语料构建中结合基于规则与LLM裁判的过滤机制
方法
作者采用综合后训练框架赋予QwenLong-L1.5强大的长上下文推理能力,整合新型数据合成流程、稳定化强化学习及记忆增强架构。整体训练范式设计为多阶段渐进过程,在扩展推理能力的同时维持训练稳定性。
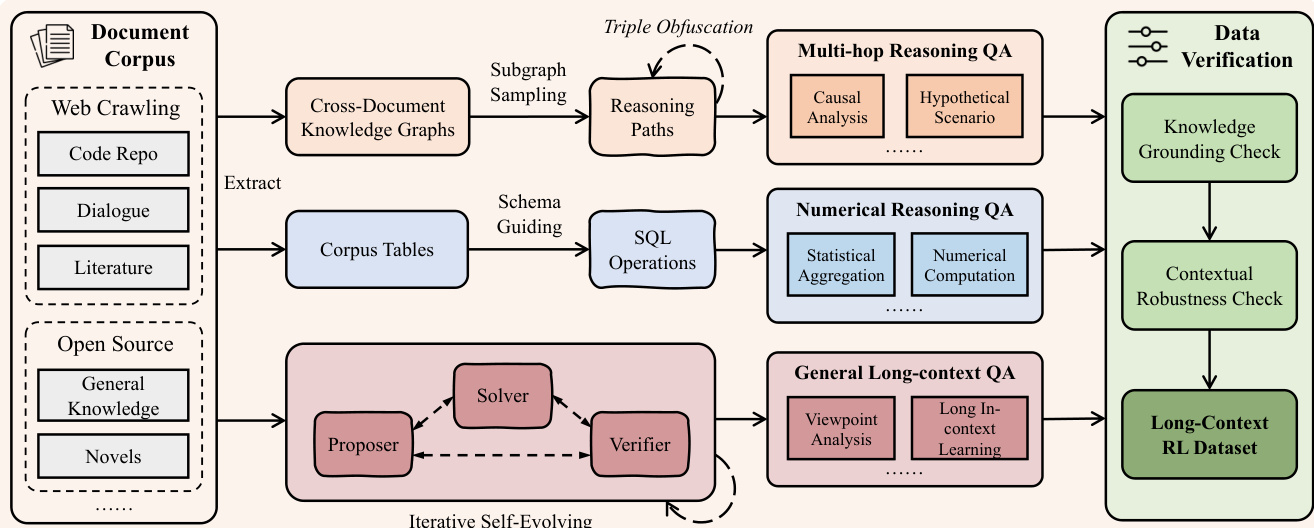
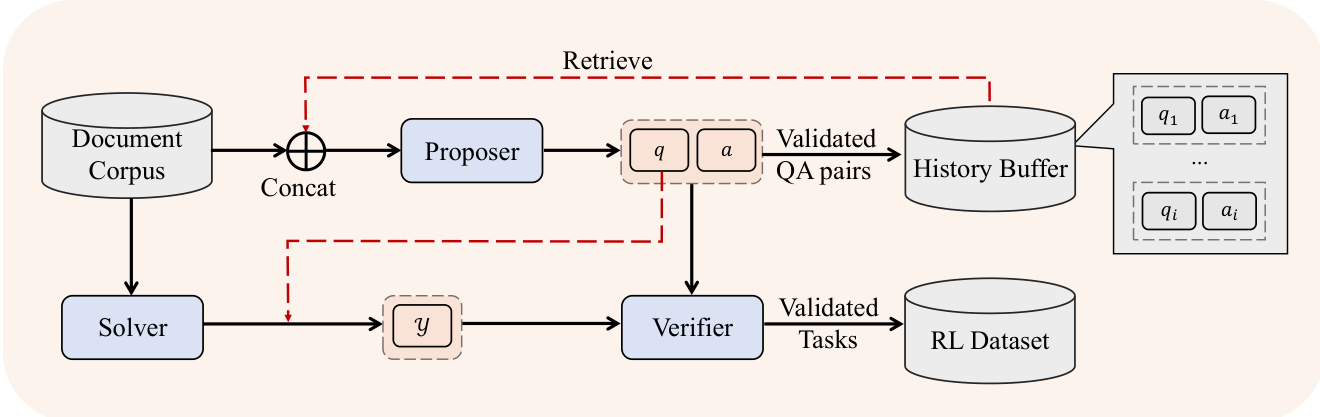
方法核心始于高质量复杂训练数据的系统化生成。如下图所示,数据合成流程通过构建需全局分布证据支持的多跳锚定挑战,突破简单检索任务范畴。流程首先摄入多样化文档语料库(含网络爬取内容、代码仓库、对话及文献),从中提取结构化表示:为多跳推理任务构建知识图谱,同时将非结构化文档解析为形式化语料表以支持数值推理。针对通用长上下文任务,采用多智能体自进化框架:提议者智能体生成问题,求解者智能体尝试作答,验证者智能体校验问答对正确性。如图所示的迭代过程确保生成数据集覆盖因果分析、假设场景、统计聚合及观点分析等广泛推理类型,并经过知识锚定与上下文鲁棒性的严格验证。
为在该数据上训练模型,作者将长上下文推理建模为强化学习问题:在参考策略约束下优化策略模型以最大化奖励函数。鉴于标准PPO在长序列上的计算不可行性,采用组相对策略优化(GRPO)——通过组内奖励z-score归一化估计优势值,省去独立价值网络需求。为解决多任务长上下文RL固有的不稳定性,引入两项关键创新:首先实施任务平衡采样,确保每个训练批次包含五类任务(如选择题、多跳问答、数值计算)的等量样本;其次提出任务特定优势估计,在批次内各任务子集而非全组范围内计算奖励标准差,从而隔离稠密/稀疏奖励分布任务,生成更精准、无偏的优势信号。
为进一步稳定训练过程,作者提出自适应熵控制策略优化(AEPO)。该算法通过监控策略的批次级熵值动态调节探索-利用权衡:当熵值超过预设上限时,AEPO屏蔽所有负优势样本(执行优势加权在线拒绝采样以降低熵值);当熵值低于下限时,则重新引入负梯度防止策略坍缩并鼓励探索。该机制支持在渐进增长长度的序列上稳定训练,对扩展模型推理能力至关重要。
对于超出模型物理上下文窗口的任务,作者部署记忆智能体框架。如下图所示,该架构将长上下文推理重构为序贯决策过程:用户查询首先分解为核心问题与格式指令;长文档切分为块后,策略在每步观察当前块与历史记忆状态,同步更新记忆与下一区块的导航计划。这种循环机制使模型能将全局上下文"折叠"为紧凑的动态表示。处理完所有块后,最终答案通过整合累积记忆与原始格式指令生成。策略采用GRPO进行端到端优化,轨迹级奖励基于最终答案正确性计算。
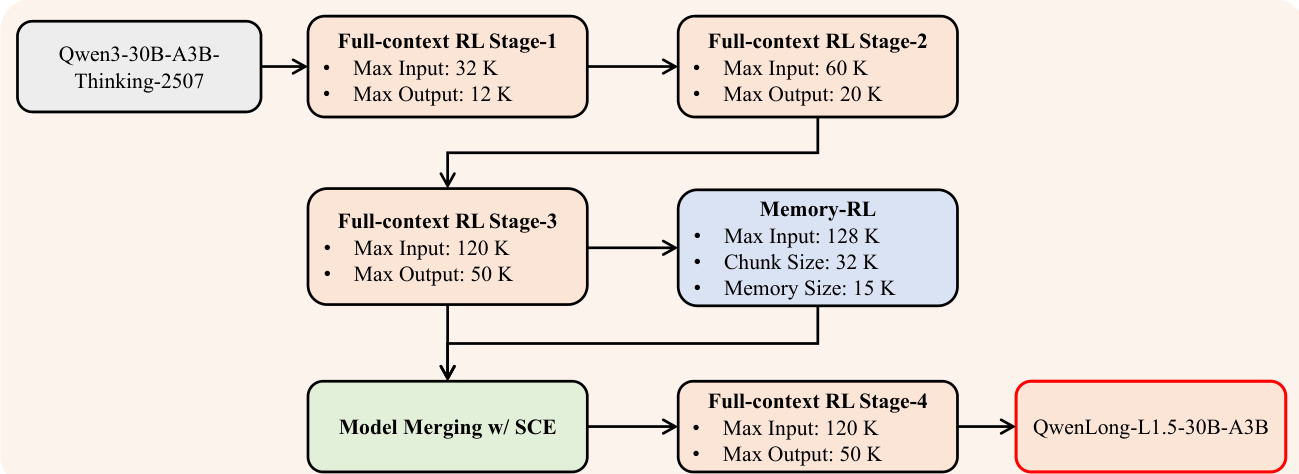
如最终图示,整体训练流程分阶段执行:从Qwen3-30B-A3B-Thinking基础模型出发,首先进行三阶段全上下文RL训练(输入/输出长度从20K/12K逐步提升至120K/50K token);第三阶段后,使用相同RL框架但以分块输入训练专用记忆智能体模型;该专家模型通过SCE算法与第三阶段模型融合,最终对融合模型应用全上下文RL训练生成QwenLong-L1.5。
这种整合可扩展数据合成、稳定化RL及记忆增强推理的方法,使QwenLong-L1.5在长上下文推理基准测试中达到顶尖性能,并有效泛化至需要长程连贯性与多跳推理的领域。
实验
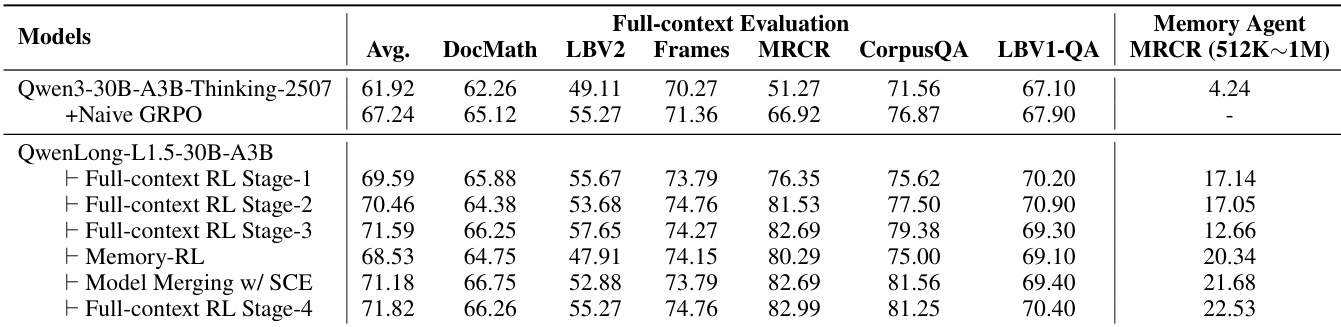
- QwenLong-L1.5-30B-A3B在LongBench-V2和MRCR等长上下文基准测试中平均得分71.82,超越DeepSeek-R1-0528(68.67)和Gemini-2.5-Flash-Thinking(68.73),其中MRCR得分82.99创当前最优。
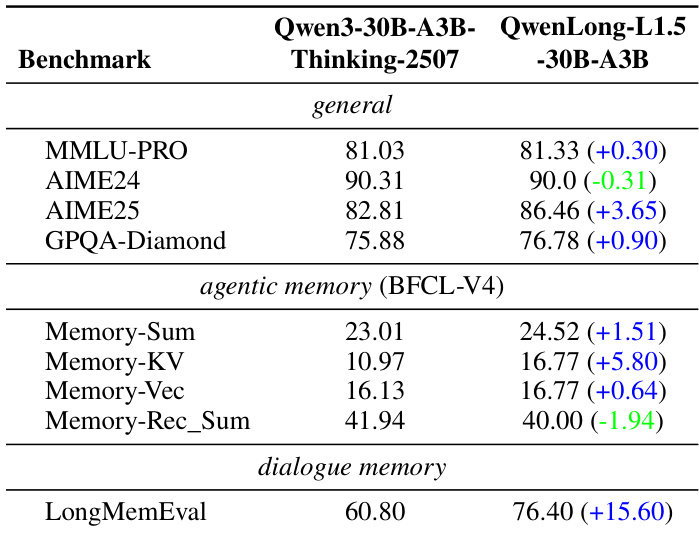
- 相较基线Qwen3-30B-A3B-Thinking-2507提升9.90分,长上下文任务增益最显著:MRCR(+31.72)、CorpusQA(+9.69)及LongBench-V2(+6.16)。
- 在非训练领域展现泛化能力:AIME25提升+3.65分,LongMemEval提升+15.60分,且MMLU-PRO等通用基准无性能退化。
- 支持高达400万token的超长上下文:在CorpusQA 4M子集得分14.29,MRCR 128K-512K子集超越基线18.32分。
- 多阶段训练验证渐进增益:第一阶段平均分提升+7.67分,后续阶段针对性增强长上下文推理与记忆智能体能力,且未损害全上下文性能。
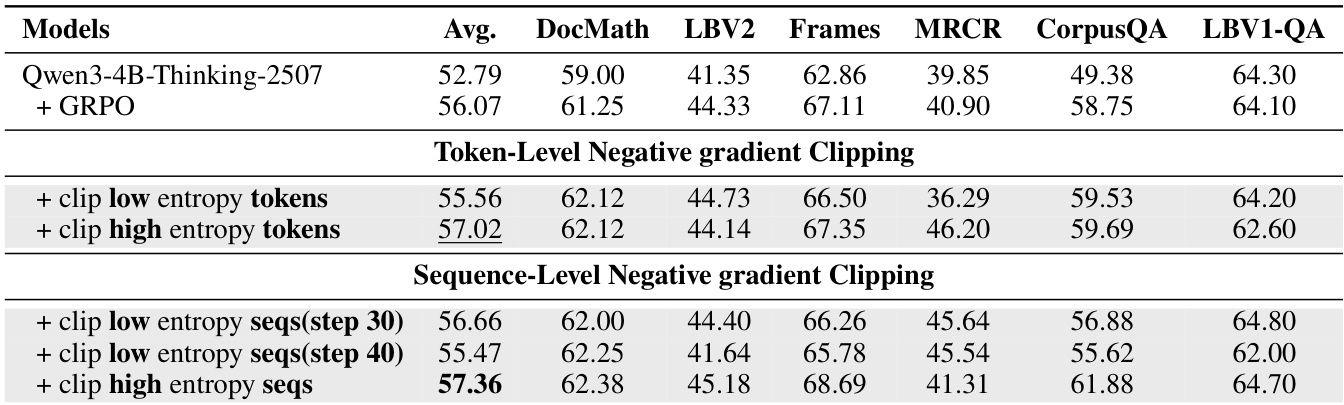
作者在Qwen3-4B-Thinking-2507上通过消融实验评估AEPO算法中不同负梯度裁剪策略的影响。结果显示:对高熵token进行token级裁剪获得最高平均分(57.02),而高熵序列的序列级裁剪实现最佳综合性能(57.36),表明序列级裁剪在训练中更有效保留有用推理路径。
作者将QwenLong-L1.5-30B-A3B与其基线Qwen3-30B-A3B-Thinking-2507在通用、智能体记忆及对话记忆基准上对比。结果显示:QwenLong-L1.5在多数任务保持或提升性能,AIME25(+3.65)、Memory-KV(+5.80)及LongMemEval(+15.60)增益显著,表明长上下文推理能力有效泛化至跨领域任务。
作者在Qwen3-4B-Thinking-2507上评估AEPO算法的消融实验,测试任务平衡采样与批次标准化的组合效果。结果显示:添加任务批次标准化获得最高平均分58.62,在Frames和CorpusQA上增益显著,但MRCR性能低于仅任务平衡采样。表明任务批次标准化提升整体性能,但对任务类型存在非均匀收益。
作者在LongBench-V1 QA基准上将QwenLong-L1.5-30B-A3B与旗舰及轻量级推理模型对比,显示其平均超越基线Qwen3-30B-A3B-Thinking-2507 3.30分。Musique(+7.00)和NarrativeQA(+9.00)增益显著,Qasper略有下降(-3.00)。该模型在多数子任务上达到或超越Gemini-2.5-Pro和DeepSeek-R1-0528等顶尖模型,展现竞争力的多跳推理能力。
作者以Qwen3-4B-Thinking-2507为基础模型,对比AEPO算法变体与GRPO的消融实验。结果显示:添加AEPO较基线模型平均提升3.29分,较GRPO提升2.29分,在DocMath、Frames及CorpusQA等所有基准测试中均保持性能提升。
