Command Palette
Search for a command to run...
文本到3D生成中的强化学习:我们准备好了吗?一项渐进式探究
文本到3D生成中的强化学习:我们准备好了吗?一项渐进式探究
摘要
强化学习(Reinforcement Learning, RL)此前已被证明在大型语言模型和多模态模型中具有显著效果,近年来更成功地被拓展至2D图像生成任务。然而,将RL应用于3D生成仍处于探索初期,主要受限于3D物体更高的空间复杂性——其生成需同时保证全局一致的几何结构与精细的局部纹理。这使得3D生成对奖励函数设计和强化学习算法的选择尤为敏感。为应对上述挑战,本文首次系统性地研究了强化学习在文本到3D自回归生成任务中的应用,涵盖多个关键维度:(1)奖励设计:我们评估了多种奖励维度与模型选择,结果表明,与人类偏好对齐至关重要,且通用多模态模型能够为3D属性提供稳健的信号;(2)强化学习算法:我们深入研究了GRPO的多种变体,凸显了基于token级别的优化策略的有效性,并进一步探究了训练数据规模与迭代次数的扩展规律;(3)文本到3D基准测试:鉴于现有基准难以衡量3D生成模型的隐式推理能力,我们提出了全新的MME-3DR基准;(4)先进强化学习范式:受3D生成过程天然层级结构的启发,我们提出Hi-GRPO,通过专用奖励集合实现从全局到局部的分层优化,有效提升生成质量。基于上述发现,我们构建了AR3D-R1——首个基于强化学习增强的文本到3D生成模型,能够从粗略形状逐步优化至精细纹理,实现端到端的高质量生成。我们期望本研究能为基于强化学习驱动的3D生成推理提供重要参考。相关代码已开源,地址为:https://github.com/Ivan-Tang-3D/3DGen-R1。
一句话总结
来自西北工业大学、北京大学和香港科技大学的研究人员提出了 AR3D-R1,这是首个基于强化学习增强的文本到3D自回归模型,引入了用于从全局到局部层次优化的 Hi-GRPO 方法,并构建了新的基准 MME-3DR,通过改进奖励设计和词元级强化学习策略推动了3D生成的发展。
主要贡献
- 本文首次系统研究了在文本到3D生成中应用强化学习(RL)所面临的关键挑战,例如由于3D对象在几何和纹理上的复杂性导致对奖励设计和算法选择的高度敏感性,并在自回归框架内评估了多种奖励模型和RL算法。
- 提出了 MME-3DR,这是一个包含249个高推理难度的3D生成案例的新基准,涵盖五个极具挑战性的类别;同时提出 Hi-GRPO,一种分层强化学习方法,利用专用的奖励集成来优化从全局到局部的3D结构与纹理生成。
- 基于上述发现,作者开发了 AR3D-R1,这是首个经强化学习增强的文本到3D生成模型,在 MME-3DR 基准上显著优于基线方法,验证了词元级优化以及通用多模态奖励模型在3D生成中的有效性。
引言
强化学习(RL)已被证明在提升大语言模型和2D图像模型的推理与生成能力方面非常有效,但由于3D对象具有更高的空间复杂性,且需要保持全局一致的几何结构和细粒度的纹理,其在文本到3D生成中的应用仍处于探索阶段。以往的3D生成工作主要依赖预训练和微调,对基于RL的优化探索有限;同时现有基准未能有效评估模型的隐式推理能力(如空间、物理和抽象推理),导致模型性能被高估。作者首次系统性地研究了自回归文本到3D生成中的强化学习,评估了奖励模型、RL算法及训练动态,并提出了 MME-3DR 这一专注于高推理强度任务的新基准。进一步地,他们提出了 Hi-GRPO,一种分层RL框架,通过专用奖励集成为粗到细的3D生成提供优化支持,并开发了 AR3D-R1——首个经RL增强的文本到3D模型,通过提升结构连贯性和纹理保真度实现了当前最优性能。
数据集
-
作者在训练中结合使用了三个主要的3D对象数据集:Objaverse-XL、HSSD 和 ABO,评估则在 Toys4K 上进行。
-
Objaverse-XL 是一个大规模数据源,包含从 GitHub、Thingiverse、Sketchfab 和 Polycam 等平台收集的超过1000万个3D对象。该数据集经过严格的去重和渲染验证,以确保类别和细粒度属性上的质量和多样性。
-
HSSD 提供约18,656个真实世界物体模型,嵌入于211个高质量合成室内场景中。该数据集强调真实的室内布局、语义结构和物体间关系。
-
ABO 包含约8,000个高质量的家居物品3D模型,源自近147,000个产品列表和400,000张目录图像,这些模型附有详细的材质、几何和属性标注。
-
用于评估的 Toys4K 包含约4,000个跨105个类别的3D对象实例,具有多样的形状和显著的形式变化。
-
训练过程中,提示词从 Objaverse-XL、HSSD 和 ABO 中采样,模型在这些数据源的混合数据上训练,未指定具体比例。基础模型为 ShapeLLM-Omni,使用8个GPU训练1,200步,每设备批量大小为1,梯度累积2步,有效批量大小为16。
-
训练设置采用学习率 1×10−6,β 值为 0.01,组大小为8。使用可配置的损失权重 λ=1.0,以最终质量评分监督全局规划。
-
奖励模型通过 vLLM API 框架提供服务,但所提供的文本中未描述明确的裁剪策略、元数据构建方法或其他预处理细节。
方法
作者采用一种分层强化学习范式 Hi-GRPO,将文本到3D生成分解为两个明确且顺序进行的阶段:先进行全局几何规划,再进行局部外观细化。该架构显式建模了人类3D感知由粗到细的特性,使每个细节层级都能实现针对性优化。
在第一步中,模型接收3D文本提示和一个高层语义指令,用于生成简洁的语义推理计划。该计划表示为语义词元序列 {si,1,…,si,∣si∣},用于澄清对象子类别、建立关键组件的空间布局并解析模糊术语。如框架图所示,该语义推理与原始提示及网格起始词元结合,作为3D自回归模型的条件输入。模型随后生成粗粒度3D词元序列 {ti,1,…,ti,M},并通过 VQVAE 解码器解码为三角网格 Mi(1)。此初始输出捕捉了全局结构和基本颜色分布,例如确保花的比例均衡,或花瓣从中心到外围呈现粉红色渐变。
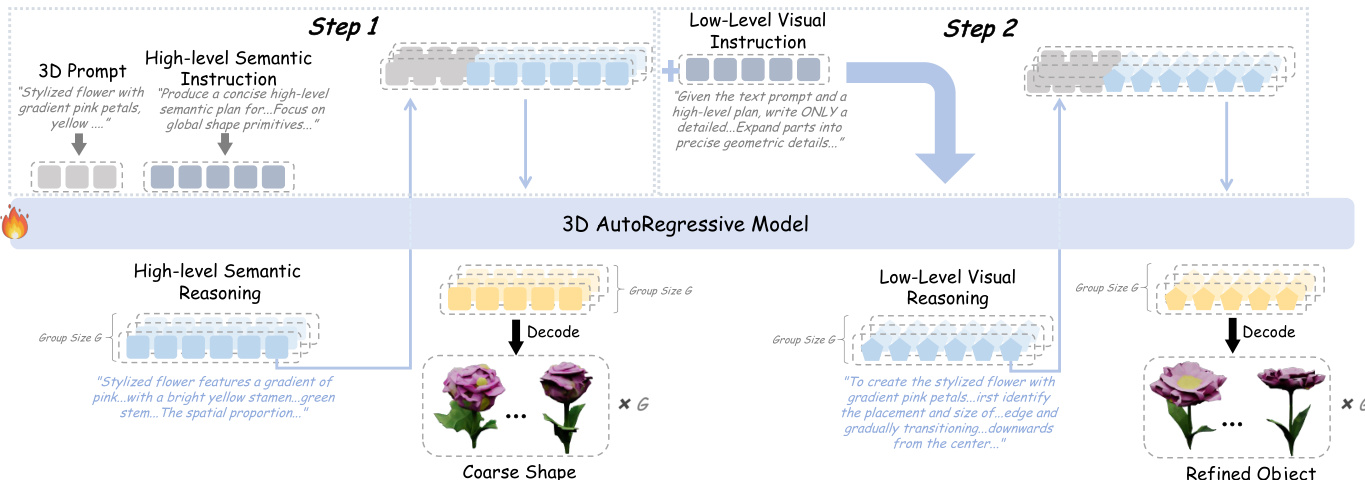
在第二步中,模型以原始提示、先前生成的高层语义推理以及一个低层视觉指令为条件,生成视觉推理词元序列 {vi,1,…,vi,∣vi∣},聚焦于局部外观细节的优化。这包括指定纹理、组件间的交互关系,以及元素数量和对称性等局部属性。随后模型生成第二组3D词元序列 {oi,1,…,oi,M},解码为最终精细化的网格 Mi(2)。此步骤添加了如花瓣纹理、雄蕊与花瓣的空间关系、叶片数量等细粒度细节,将粗糙形状转化为高保真的3D资产。
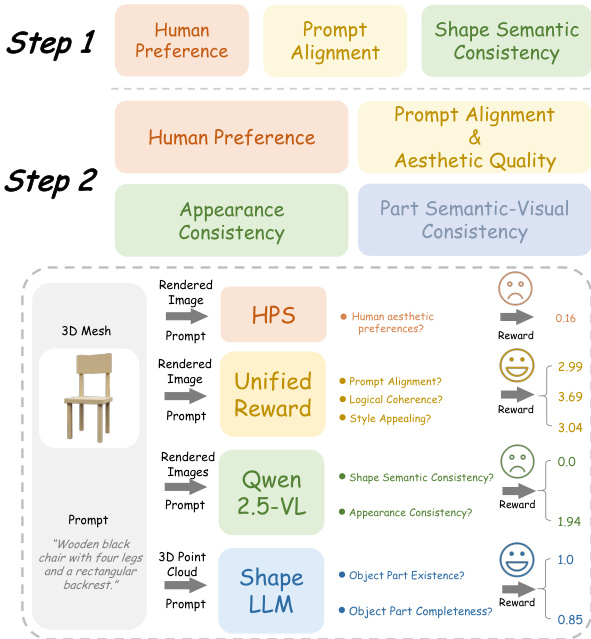
训练过程为每一步采用定制的奖励集成,以指导策略梯度优化。如奖励设计图所示,第一步的奖励聚焦于全局对齐,包括人类偏好(HPS)、提示对齐(UnifiedReward)和几何一致性(Qwen2.5-VL);第二步奖励则强调局部优化,包含人类偏好、外观质量(UnifiedReward-2.0)、跨视角一致性(Qwen2.5-VL)和组件完整性(ShapeLLM)。每个奖励均进行维度归一化以确保贡献均衡。关键的是,第二步的奖励通过可配置权重 λ 反向传播至第一步,使最终输出质量可监督初始的全局规划。总损失为各步骤独立计算的策略损失之和,采用带非对称裁剪阈值的裁剪代理目标,以促进探索并防止熵崩溃。
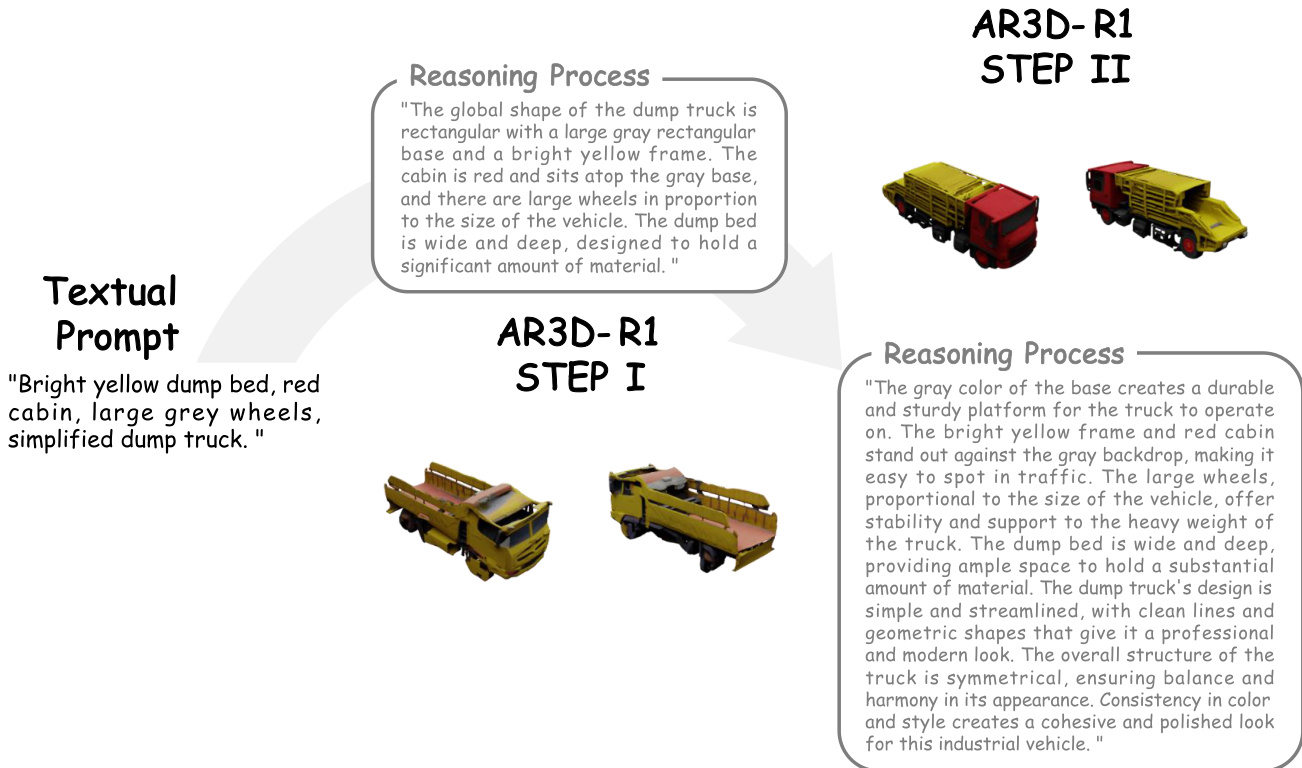
模型在推理阶段的输出遵循相同的两步流程。如定性结果所示,第一步生成一个基本的、几何一致的形状,第二步则通过添加详细纹理、颜色和部件结构进行细化,最终生成的网格与提示描述高度一致。
实验
作者在3D词元生成前引入文本推理作为前置步骤,发现该方法可使 CLIP Score 从基线模型的 22.7 提升至包含推理时的 24.0,优于无推理的直接生成(23.4)。结果表明,引入推理增强了模型生成语义连贯3D输出的规划能力。

作者在两个生成步骤中采用分层奖励系统,结合人类偏好、统一美学、3D一致性和部件级奖励。结果表明,引入步骤特定奖励——尤其是第二步中的部件级引导——可获得最高的 CLIP Score 和最低的 KD_incep,说明语义对齐和结构保真度得到提升。若省略任一组件,特别是步骤特定或部件级奖励,性能将明显下降。
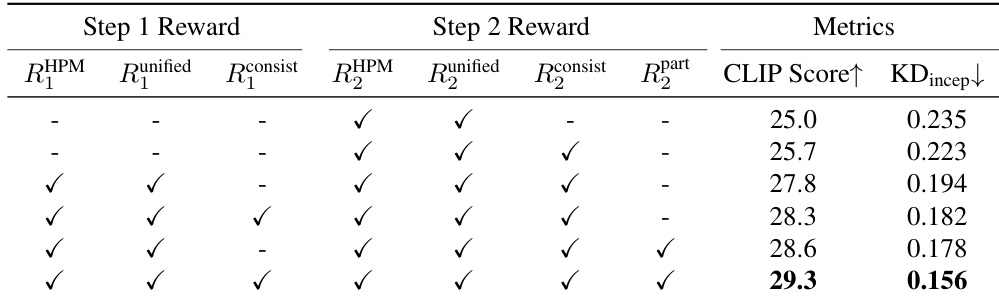
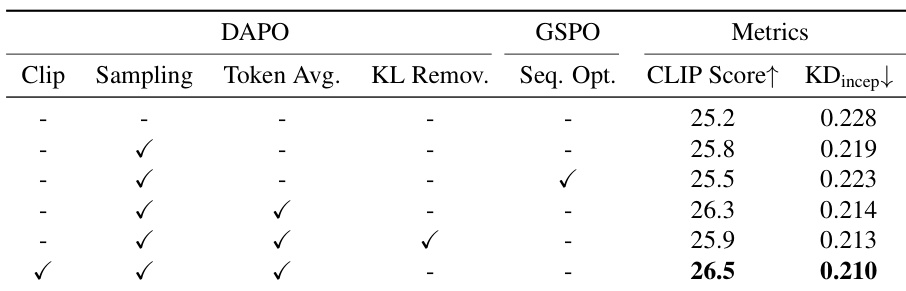
结果表明,在 DAPO 中结合动态采样(Dynamic Sampling)、词元级损失聚合(Token-level Loss Aggregation)和解耦裁剪(Decoupled Clip),可达到最高的 CLIP Score(26.5)和最低的 KD_incep(0.210),优于标准 GRPO 和 GSPO 变体。词元级策略始终优于序列级优化,同时保留 KL 惩罚有助于稳定训练并防止性能退化。
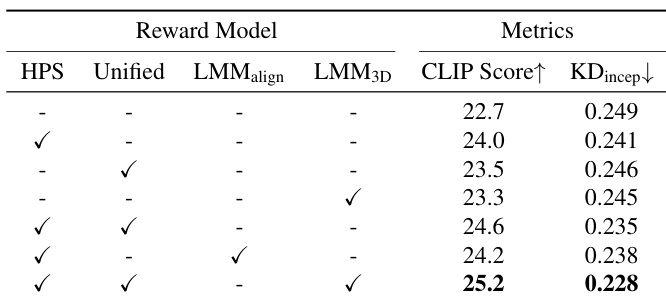
作者使用人类偏好(HPS)、UnifiedReward 和基于LMM的3D一致性奖励,通过 GRPO 优化3D自回归生成。结果表明,结合全部三种奖励信号可获得最高的 CLIP Score(25.2)和最低的 KD_incep(0.228),优于任何单一或部分组合。HPS 单独提供了最强的基线提升,而 LMM_3D 在增强跨视角结构一致性方面具有独特价值。
结果表明,AR3D-R1 在 MME-3DR 和 Toys4K 两个基准上均优于先前方法,取得了最高的 CLIP 分数以及最低的 KD 和 FD 指标。该模型在复杂对象类别中展现出卓越的文本到3D对齐能力和结构连贯性。这些提升源于其结合了步骤特定奖励和文本推理引导的分层强化学习框架。