Command Palette
Search for a command to run...
T-pro 2.0:一种高效的俄语混合推理LLM与实验平台
T-pro 2.0:一种高效的俄语混合推理LLM与实验平台
摘要
我们推出了 T-pro 2.0,这是一个面向混合推理与高效推理的开源俄语大语言模型(LLM)。该模型支持直接回答问题以及生成推理轨迹,采用以西里尔字母为主的密集分词器,并结合经过优化的 EAGLE 伪推理解码(speculative-decoding)流水线,显著降低推理延迟。为促进可复现且可扩展的研究,我们已在 Hugging Face 平台上公开发布模型权重、T-Wix 500k 指令语料库、T-Math 推理基准测试数据集,以及 EAGLE 的相关权重。这些资源使研究人员能够深入探究俄语语言推理能力,并对模型及推理流水线进行扩展或适配。此外,我们还提供公开的网页演示,展示模型在推理与非推理模式下的表现,并直观呈现我们推理架构在多个领域实现的性能加速效果。因此,T-pro 2.0 为构建与评估高效、实用的俄语大语言模型应用,提供了一个开放且易于访问的系统平台。
一句话总结
来自莫斯科T-Tech的Gen-T团队提出了T-pro 2.0,这是一款开源权重的俄语大语言模型,采用西里尔文密集型分词器,并适配EAGLE推测解码以实现更快推理。该模型支持推理链和直接回答,可在实际应用中实现高效的混合推理,所有模型权重、基准测试和工具均已公开,便于可复现研究。
主要贡献
- T-pro 2.0 通过在单语模型中引入混合推理能力,解决了高效开源俄语大模型缺乏的问题,能够在俄语应用中实现直接回答生成和逐步推理,同时降低延迟。
- 该模型引入了以推理为中心的中期训练阶段、推测解码适配方法以及推理链生成技术,以提升性能。
- 我们为研究社区提供了包括模型权重在内的全面资源。
引言
作者利用近期在面向推理的训练和高效推理方面的进展,解决了缺乏能够进行混合推理的高性能开源俄语语言模型的问题。尽管存在强大的多语言模型,但俄语开源生态受限于闭源系统、规模小或范围窄的指令数据集,以及缺乏用于研究推理动态和推理效率的工具。以往工作要么专注于能力有限的单语预训练,要么在未针对推理或速度优化的情况下适配多语言模型。
为克服这些挑战,作者推出了T-pro 2.0,这是一款支持直接回答和逐步推理的开源权重俄语大模型,结合西里尔文密集型分词器和适配的EAGLE推测解码流程,实现更快的推理。主要贡献包括发布模型和EAGLE权重、包含推理链的T-Wix 500k指令数据集、用于俄语数学推理评估的T-Math基准测试,以及一个交互式网页演示,支持实时比较不同推理模式和推理性能。这些资源共同构成了一个全面且可复现的平台,推动俄语大模型的研究与应用。
数据集
-
作者使用一个多阶段指令微调数据集(T-Wix 500k),包含多样化、高质量、以俄语为核心的推理任务,用于训练旨在增强大模型推理能力的T-pro 2.0。
-
数据集来源包括一个由50万条指令遵循数据组成的数据集,这些数据从以英语为中心的数据集翻译而来,专注于俄语语言模型的训练与评估。
-
T-Wix 500k数据集经过过滤,仅保留10%的英文数据。
-
关键处理步骤包括:
- 从公开资源(如Hugging Face Hub)构建一个400万token的语料库。
- 通过奖励建模和拒绝采样进行指令过滤,以提高响应质量并减少冗余。
-
元数据构建包括:
- 注重多语言支持,许可允许用于研究,且在数据集平衡方面符合教学原则,兼顾多样性与推理需求。
-
最终数据集包含50万条高质量的俄英双语样本,其中10%为英文数据,涵盖代码、数学、科学和常识等领域,确保推理任务的广泛覆盖。
-
处理过程包括按数据类别(推理、通用问答、代码等)应用基于InsTag的去重,采用精确匹配和标签级语义去重,随后进行贪心多样性采样,以在宏观层面控制类别平衡。
-
对于每个保留的样本,最终助手回复由更强的教师模型(Qwen3-235B)重新生成,以提升答案质量和风格一致性。
-
中期训练的数据混合有意比SFT阶段更大且更少人工筛选,以牺牲部分噪声换取更广泛的任务和领域覆盖。
-
消融研究表明,仅使用指令数据的混合优于或匹配包含通用预训练数据的混合变体,突显了在已充分预训练的模型中专注指令微调的有效性。
方法
作者为T-pro 2.0设计了一个多阶段训练流程,整合了分词器适配、指令中期训练、通用后训练以及基于EAGLE的推测解码。每个阶段旨在提升俄语和多语言任务的性能,同时保持效率并符合人类偏好。
流程始于西里尔文密集型分词器的适配。为解决多语言模型中对俄语分词不足的问题,作者将Qwen3词汇表中3.4万个低频非西里尔文token替换为西里尔文token,保持总词汇量不变。扩展集通过从四个捐赠分词器中提取包含至少一个西里尔文字母的3.57万个候选token构建。每个候选token在当前合并图下进行评估,并迭代添加所需合并,以确保两部分分解完全可达。经过四轮优化后,约95%的候选token变得可达。token保留依据字符组成(西里尔文、纯拉丁文、标点、1–2符号单元),而移除的token则通过在中期训练混合数据上进行对数平滑频率评分选择。此修改带来显著压缩增益:在俄语维基百科上,被分词为最多两个token的词比例从38%提升至60%,在八种西里尔文语言中均有一致改进。
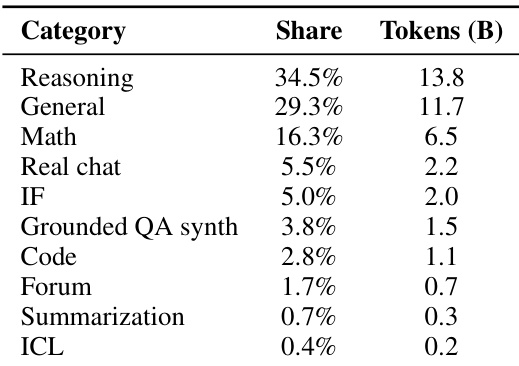
随后是指令中期训练,将Qwen3-32B模型适配至新分词器并增强推理能力。该阶段使用来自精选开源指令、合成任务和并行语料的400亿token,主要为俄语(49%)和英语(36%)。领域包括推理(34.6%)、通用问答(28.8%)和数学(16.2%),辅以基于事实的合成问答、代码和真实用户对话。数据经过领域特定的LSH去重和基于InsTag的语义去重以确保多样性。助手回复由Qwen3-235B-A22B教师模型重新生成。训练使用32k上下文窗口,以稳定模型用于后续SFT。消融实验证实,仅使用指令的中期训练优于保留原始预训练数据的混合方案,使ruAIME 2024得分从0.60提升至0.67。小规模实验也验证了分词器迁移的有效性,T-pro分词器在MERA宏平均得分上(0.574)高于原始Qwen3分词器(0.560)。
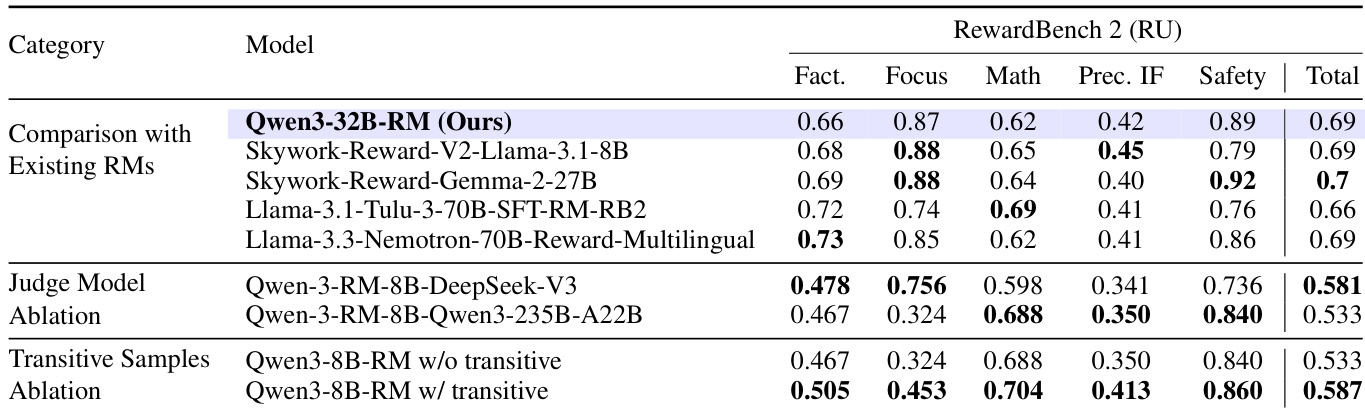
在后训练阶段,作者构建了一个专用奖励模型(RM),初始化自Qwen3-32B并配备标量回归头。训练采用Bradley-Terry偏好目标,处理最长32K token的序列,使用Ulysses风格的序列并行。合成偏好数据通过多个不同规模模型组的淘汰赛生成。每场比赛包含 n 名参与者,按模型类别(如小规模或推理导向)分组,以确保有意义的比较。外部大模型担任裁判,以避免位置偏差。添加传递性比赛关系以提升偏好覆盖。该方法将成对评估数量从 2n(n−1) 减少到 2nlog2n,同时保留信息信号。RM在翻译版RewardBench 2和自定义Arena-Hard Best-of-N基准上评估,取得最高 ΔBoN 得分(22.21),表明其卓越的判别能力。
通用后训练包括监督微调(SFT)和直接偏好优化(DPO)。T-Wix SFT数据集从1400万条原始指令开始,通过去重、多阶段过滤以及在六个领域和三个难度等级上的领域/复杂度平衡,筛选出46.8万条样本。每条指令由Qwen3-235B-A22B或DeepSeek-V3生成8个候选完成,再通过RM引导选择进行过滤。最终数据集噪声低、领域平衡,主要为俄语,保留10%英文数据以维持双语能力。对于推理任务,从45万条英文池中抽取3万条样本,翻译并去重。候选解由教师模型和中期训练检查点生成,再通过基于RM的拒绝过滤。对于可验证任务,选择得分最高的事实正确输出;对于开放任务,选择RM排名靠前候选中最短的有效推理链。DPO在从T-Wix数据集中采样的10万条指令上进行(通用与推理比例为90/10)。每条指令生成16个策略内完成,评分后形成一对高对比度偏好样本(最优 vs 最差),直接针对失败模式优化,无需在线强化学习开销。
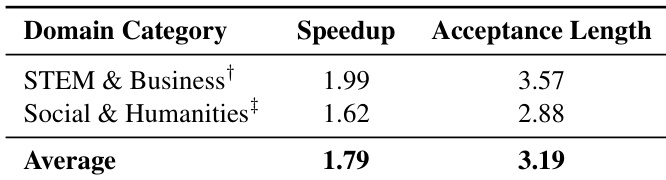
最后,作者集成基于EAGLE的推测解码模块以加速推理。轻量级草稿模型由一个基于Llama-2的解码层和FR-Spec组件构成,提出由冻结的32B目标模型验证的候选token。草稿模型在隐藏状态重建(平滑 L1)和token分布对齐(KL散度)损失上训练。推理时,通过SGLang采用EAGLE-2的动态草稿树机制。在温度0.8下,该模块在标准模式下平均加速 1.85×,推理模式下增益相似。STEM领域加速更高(1.99×),人文领域较低(1.62×),归因于技术内容中更可预测的token分布。
实验
- 实验验证了EAGLE推测解码在T-pro 2.0上的加速效果,跨领域平均加速 1.79×,平均接受长度3.19个token;STEM和商业领域增益最高(1.99×,3.57个token),社科与人文领域为 1.62× 和2.88个token。
- 数据集构成中推理任务占34.5%,通用指令占29.3%,数学内容占16.3%;结果表明该分布支持在T-Math和ruAIME等俄语推理基准上的强性能,同时保持英语推理竞争力。
- 通过公开网页演示,在相同服务条件下对比T-pro 2.0与Qwen3-32B、GigaChat 2 Max和RuadaptQwen3-32B-Instruct等基线模型,T-pro 2.0平均延迟最低(2.71),显示其卓越的推理效率,归功于在H100 GPU上部署的EAGLE式推测解码流程。
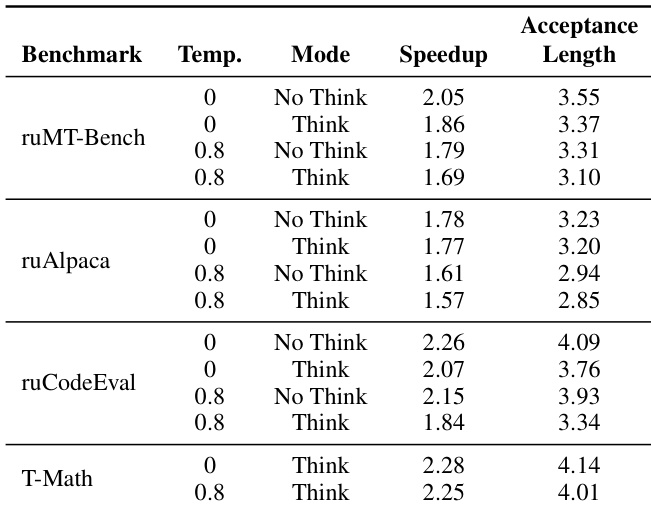
- 使用EAGLE推测解码在T-Math上最高加速达 2.28×,并在ruMT-Bench、ruAlpaca和ruCodeEval上持续改善延迟;在温度0和“思考”模式下加速和接受长度更高,表明该方法对确定性、高推理强度任务最有效;系统在减少生成时间的同时保持输出质量,代码和数学领域增益最大。
- 在RewardBench 2(RU)上评估Qwen3-32B-RM奖励模型,总得分为0.69,表现具有竞争力;消融研究表明,使用DeepSeek-V3作为裁判模型比Qwen3-235B-A22B对齐更好,训练中引入传递性偏好样本可提升所有类别得分,总分从0.533升至0.587。