Command Palette
Search for a command to run...
孔子代码Agent:面向真实代码库的可扩展Agent框架
孔子代码Agent:面向真实代码库的可扩展Agent框架
摘要
现实世界中的软件工程任务要求编码代理能够处理大规模代码库、维持长时间的会话,并在测试时可靠地协调复杂的工具链。现有的研究级编码代理虽然具备良好的可解释性,但在扩展至更重、更接近生产环境的工作负载时表现不佳;而现有的生产级系统虽在实际性能上表现强劲,却在可扩展性、可解释性和可控性方面存在明显局限。为此,我们提出孔子编码代理(Confucius Code Agent, CCA),一种可运行于大规模代码库的软件工程代理。CCA基于孔子SDK(Confucius SDK)构建,该SDK是一个围绕三个互补视角设计的代理开发平台:代理体验(Agent Experience, AX)、用户体验(User Experience, UX)和开发者体验(Developer Experience, DX)。该SDK集成了统一的编排器与分层工作记忆系统,支持长上下文推理;具备持久化笔记系统,支持跨会话的持续学习;并提供模块化扩展机制,保障工具使用的可靠性。此外,我们引入了一个元代理(meta-agent),通过“构建-测试-改进”循环,自动完成代理配置的合成、评估与优化,从而实现对新任务、新环境和新工具栈的快速适应。依托上述机制,CCA在真实世界软件工程任务中展现出卓越性能。在SWE-Bench-Pro基准测试中,CCA的Resolve@1达到54.3%,超越了此前所有研究类基线,并在相同代码库、模型后端和工具访问条件下,与商业系统结果相媲美。
一句话总结
Meta 和哈佛大学的研究人员提出了孔子代码代理(Confucius Code Agent, CCA),这是一个基于孔子 SDK 构建的可扩展软件工程代理,集成了分层工作记忆、自适应上下文压缩、持久化笔记记录以及元代理驱动的自动化配置优化;通过显式分离代理体验(Agent Experience)、用户体验(User Experience)和开发者体验(Developer Experience),CCA 在 SWE-Bench-Pro 上实现了 54.3% 的 Resolve@1,达到当前最优水平,并在真实世界调试任务中展现出卓越的鲁棒性,优于相同条件下所有研究与商业系统。
主要贡献
-
现实世界软件工程需求编码代理能够处理大规模代码库中的长周期、多文件任务,但现有系统或缺乏可扩展性(研究级代理),或存在可解释性差、可扩展性弱的问题(生产级系统),导致智能体软件工程领域存在关键空白。
-
孔子代码代理(CCA)通过孔子 SDK 解决该问题,该 SDK 系统性地分离了代理体验(AX)、用户体验(UX)和开发者体验(DX),支持通过分层工作记忆实现可扩展推理、通过持久化笔记记录实现跨会话学习,并支持模块化工具扩展与完整可观测性。
-
在 SWE-Bench-Pro 上,CCA 达到 54.3% 的 Resolve@1,优于先前研究基线,并在相同条件下与商业系统持平;消融实验确认了其元代理驱动的配置优化与分层记忆机制的关键作用。
引言
作者针对日益增长的、能够处理大规模真实世界软件工程任务的编码代理需求展开研究——例如在大型代码库中导航、维持长周期工作流、协调复杂工具链——而现有系统在这些方面表现不足。以往工作面临根本性权衡:研究级代理具备透明性与可解释性,但无法扩展至生产负载;而生产系统虽性能强劲,却牺牲了可扩展性、可控性与可复现性。核心挑战在于如何在分散的代码模块间维持长上下文推理,并实现持久、跨会话的学习以避免重复劳动。为克服这些难题,作者提出基于孔子 SDK 的孔子代码代理(CCA),该平台围绕三个独立的设计维度构建:代理体验(AX)、用户体验(UX)和开发者体验(DX)。SDK 通过分层工作记忆实现高效长上下文推理,通过持久化笔记系统捕获可复用的洞察与失败模式,通过模块化扩展实现可靠工具集成,并通过元代理以“构建-测试-改进”循环自动完成配置合成与优化。这种系统化支撑使 CCA 在 SWE-Bench-Pro 上实现 54.3% 的 Resolve@1,超越先前研究基线并匹配商业系统,证明有效的代理设计(而非仅模型规模)才是实现真实世界影响的关键。
数据集

- 数据集由来自 GitHub 问题和代码仓库的真实世界软件工程任务构成,具体来自 PyTorch 和 Open Library 项目。
- 对于 PyTorch-Bench,作者从 2025 年 1 月至 7 月期间的 PyTorch GitHub 仓库中收集了 8 个可复现的问题,仅保留具备清晰复现脚本、详细描述和复现说明的问题。
- 对于 Open Library 子集,数据集包含由代理生成的项目特定与共享知识笔记,按层级结构组织,包含项目目录、共享工具目录以及记录边缘情况与修复方案的独立 Markdown 文件。
- 每个子集均经过处理以提取可操作洞察:问题按可复现性与技术清晰度筛选,笔记则通过包含 ID、标题、描述和关键词等元数据进行结构化,便于检索。
- 作者在训练混合数据中同时使用 PyTorch-Bench 与 Open Library 任务,采用均衡比例,确保对不同类型软件调试挑战的多样化覆盖。
- 采用裁剪策略,仅聚焦于相关代码文件与测试用例(如 find_author() 函数及其关联测试文件),确保代理在最小但上下文充分的输入上运行。
- 每条笔记的元数据使用标准化字段(id、title、description、keywords)构建,以支持代理执行过程中的语义搜索与检索。
方法
孔子 SDK 基于三轴框架设计,将代理体验(AX)、用户体验(UX)和开发者体验(DX)作为相互依赖且同等重要的设计核心。这一整体性方法体现在系统的架构中,即明确分离代理的内部认知工作区与外部用户及开发者接口。系统核心为孔子编排器(Confucius Orchestrator),一个轻量级执行循环,负责管理大语言模型(LLM)、代理记忆与外部工具之间的交互。编排器在有限循环内运行,以系统提示和当前记忆状态调用 LLM,解析模型输出为结构化动作,并将这些动作路由至相应扩展组件执行。该过程持续进行,直至代理发出完成信号或达到最大迭代次数。扩展组件是附加至编排器的模块化单元,负责处理特定任务,如解析模型输出、执行工具、生成提示等。这种分离实现了职责清晰划分,并支持不同代理间行为的复用。

该框架的设计理念通过孔子核心图示得以体现,图中展示了 AX、UX 和 DX 的独立通道。代理的内部认知工作区(AX)以效率和低噪声为目标,接收经过提炼与结构化的对话历史版本。相比之下,用户体验(UX)设计注重透明性与可解释性,提供丰富的、可仪器化的追踪信息,使用户能够观察并交互代理行为。开发者体验(DX)则通过可观测性工具支持,提供对代理推理(AX)与外部行为(UX)的深入洞察,从而实现可复现性、可调试性与快速迭代。这种关注点分离确保各轴可独立优化,而不影响其他轴。

长期运行代理任务的关键挑战在于管理 LLM 的上下文窗口,其可能因对话历史累积而被压垮。孔子 SDK 通过自适应上下文压缩机制应对该问题。当有效提示长度接近可配置阈值时,一个专用规划代理——代码架构师(Code Architect)——被调用,分析对话历史并构建结构化摘要。该摘要明确保留关键信息类别,如任务目标、已做决策、待办事项(TODO)和关键错误追踪,取代原始大段历史记录。系统保留最近交互的滚动窗口以原始形式存储,确保代理在长轨迹中仍能维持多步推理,而不会超出上下文限制。该方法相比固定窗口截断或简单检索方法,提供了更鲁棒且语义感知的替代方案。

孔子代码代理(CCA)是孔子 SDK 的具体实现,其构建基于一个元代理,该代理自动化代理开发流程。元代理在“构建-测试-改进”循环中运行:合成代理配置,连接编排器组件与扩展,对代表性任务评估候选代理,并根据观察到的失败迭代优化提示与工具使用策略。该自动化流程支持快速开发针对特定用例与环境的代理。CCA 由编排器、记忆系统与扩展组件构成,其中记忆系统包含一个分层笔记代理,将交互轨迹转化为结构化持久知识。这些知识以类文件系统树结构的 Markdown 文件形式存储,使代理能够在会话间检索与复用信息,包括失败案例与已知修复方案。扩展系统(如 Bash 工具与文件编辑工具)提供模块化且可扩展的方式,将新能力集成至代理中。整体架构图展示了孔子 SDK 各组件如何协同工作,构建出一个稳健且可适应的编码代理。
实验
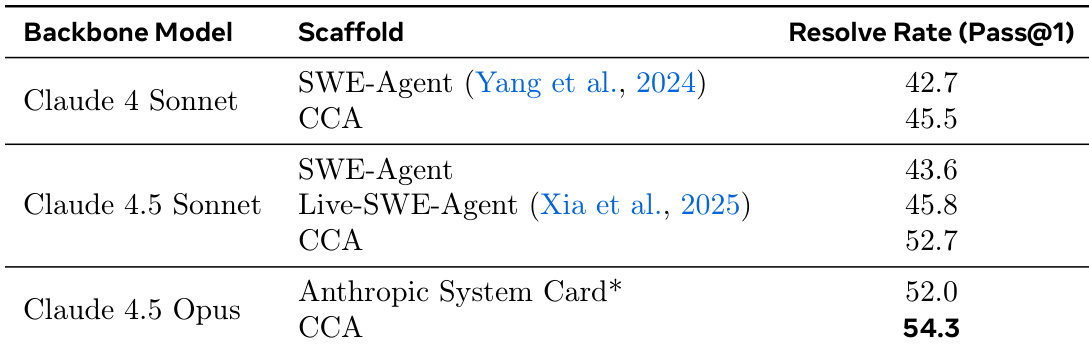
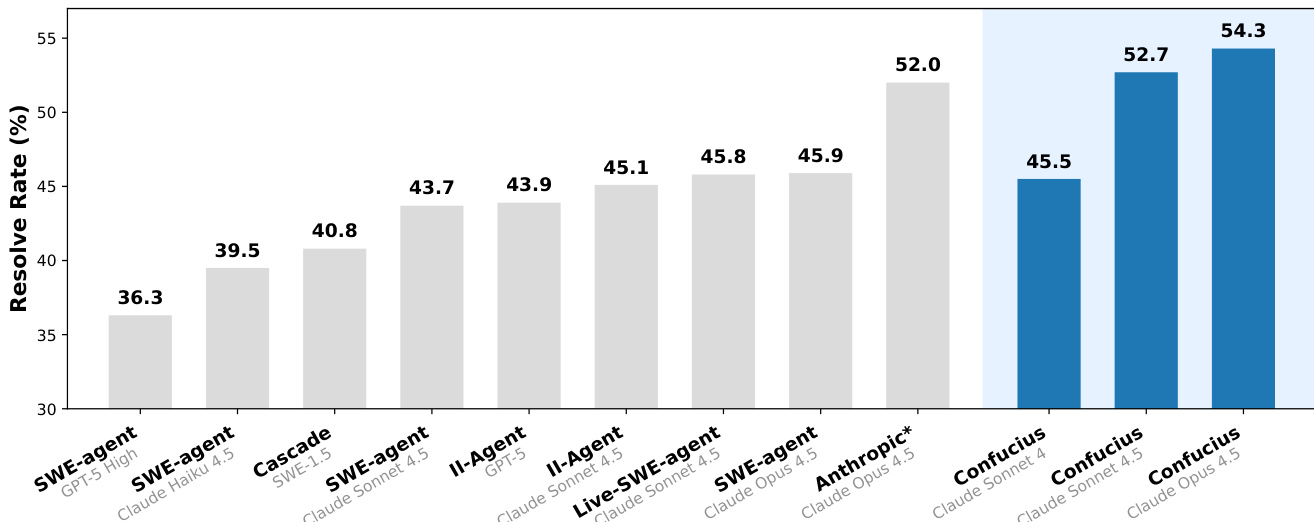
- 在 SWE-Bench-Pro 上,CCA 使用 Claude 4.5 Sonnet 达到 52.7% 的 Resolve@1,使用 Claude 4.5 Opus 达到 54.3%,超越 Live-SWE-Agent(45.8%)与 Anthropic 的专有框架(52.0%),表明仅改进智能体支撑结构即可带来性能提升。
- 消融实验显示,通过元代理学习的工具使用对性能贡献显著,即使在具备先进上下文管理的情况下,禁用该功能也会导致 Resolve@1 显著下降。
- 分层上下文管理使 Claude 4 Sonnet 的 Resolve@1 提升 6.6 个百分点(从 42.0 提升至 48.6),支持更深层次推理,同时在不丢失关键信息的前提下将提示长度减少 40% 以上。
- CCA 在多文件编辑场景中保持稳定性能,仅在修改更多文件的任务上出现适度退化,表明其在复杂重构任务中的鲁棒性。
- 通过笔记实现的长期记忆使 token 消耗减少 11k,迭代轮次减少 3,同时在重复的 SWE-Bench-Pro 任务上将 Resolve@1 从 53% 提升至 54.4%,证明了跨会话学习的有效性。
- 在 SWE-Bench-Verified 上,CCA 使用 Claude 4 Sonnet 实现 74.6% 的 Resolve Rate,优于 OpenHands 与使用 Claude 4.5 Sonnet 的 mini-SWE-Agent 变体,凸显支撑结构的影响远超底层模型强度。
- 思考预算扩展显示,在 SWE-Bench-Verified 上超过 16k token 后收益递减,且由于模型层面的抽象,无法精确控制内部推理长度。
- 对真实 PyTorch 问题的案例研究显示,CCA 的最小化、原则性修复方案与最终 PyTorch 团队解决方案一致;而 CC 的多代理方法虽更复杂,却导致过度工程化、上下文碎片化的解决方案。
作者使用 CCA 这一新型代理支撑结构,在 SWE-Bench-Pro 上实现了优于现有基线与专有系统的性能。结果表明,CCA 在不同骨干模型下持续超越 SWE-Agent 与 Live-SWE-Agent,使用 Claude 4.5 Opus 时达到 54.3% 的 Resolve Rate,优于 Anthropic 专有系统报告的结果。
作者使用表 5 将 CCA 与开源支撑结构在 SWE-Bench-Verified 基准上进行对比,结果显示 CCA 在使用 Claude 4 Sonnet 时达到 74.6% 的 Resolve Rate,优于最强的开源系统 OpenHands,在相同骨干模型条件下表现更优。该结果表明,增强的智能体支撑结构可弥合甚至超越因骨干模型能力差异带来的性能差距。

作者使用 SWE-Bench-Pro 基准对比 CCA 与多种代理支撑结构及骨干模型,结果显示 CCA 在不同模型上均持续优于 SWE-Agent 基线。使用 Claude 4.5 Opus 时,CCA 实现 54.3% 的 Resolve@1,超越最佳研究级编码代理与 Anthropic 的专有系统,证明性能提升源于支撑结构的增强,而非模型或评估差异。
作者分析 CCA 在 SWE-Bench-Pro 上的性能随修改文件数量的变化,将任务按修改文件数分组。结果显示,CCA 在不同编辑量下保持稳定性能,修改 1–2 个文件的任务达到最高解决率 57.8%,修改 10 个及以上文件的任务则适度下降至 44.4%。

结果表明,CCA 的性能在先进上下文管理与工具使用下显著提升。对于 Claude 4.5 Sonnet,同时启用先进上下文管理与先进工具使用,使 Resolve Rate 从 44.0% 提升至 51.6%,证明了这些功能的协同效应。
