Command Palette
Search for a command to run...
MotionEdit:面向运动中心图像编辑的基准测试与学习
MotionEdit:面向运动中心图像编辑的基准测试与学习
Yixin Wan Lei Ke Wenhao Yu Kai-Wei Chang Dong Yu
摘要
我们提出 MotionEdit,一个面向以动作为中心的图像编辑任务的新型数据集——该任务旨在修改主体的动作与交互行为,同时保持其身份、结构以及物理合理性。与现有图像编辑数据集主要关注静态外观变化,或仅包含稀疏且低质量动作编辑不同,MotionEdit 提供了从连续视频中提取并验证的高质量图像对,真实呈现了动作变换过程。这一新任务不仅具有显著的科学挑战性,也具备重要的实际应用价值,可为帧控制视频生成、动画制作等下游应用提供支持。为评估模型在该新任务上的表现,我们引入 MotionEdit-Bench,一个专门针对以动作为中心的编辑任务设计的基准测试平台,通过生成性、判别性以及偏好性等多种度量方式,全面衡量模型性能。基准测试结果表明,当前最先进的基于扩散模型的编辑方法在动作编辑任务上仍面临巨大挑战。为弥补这一差距,我们提出 MotionNFT(Motion-guided Negative-aware Fine Tuning,运动引导的负向感知微调)——一种后训练框架,其核心机制是基于输入图像与模型编辑后图像之间的运动流与真实运动流的匹配程度,计算运动对齐奖励,从而引导模型实现更精确的动作变换。在 FLUX.1 Kontext 和 Qwen-Image-Edit 等模型上的大量实验表明,MotionNFT 能够在不牺牲模型通用编辑能力的前提下,持续提升基础模型在动作编辑任务中的编辑质量与运动保真度,充分验证了该方法的有效性与实用性。
一句话总结
腾讯AI与加州大学洛杉矶分校的研究人员推出了MotionEdit,这是一个面向以动作为核心的图像编辑的高保真数据集和基准,并提出了MotionNFT,一种后训练框架,该框架利用动作对齐奖励来提升扩散模型中的动作变换准确性,同时保持身份和结构一致性,从而实现精确、符合指令的动作编辑,适用于动画和视频合成等应用。
主要贡献
- MotionEdit引入了一个高质量的数据集和基准,用于以动作为中心的图像编辑,解决了现有数据集中缺乏真实、遵循指令的动作变换问题,通过从连续视频帧中提取配对图像数据,提供准确且物理上合理的动作变化。
- 本文提出了MotionNFT,一种后训练框架,在负样本感知微调设置中使用基于光流的动作对齐奖励,引导扩散模型实现更准确、连贯的动作编辑,同时保持身份和场景结构不变。
- 在FLUX.1 Kontext和Qwen-Image-Edit上的实验表明,MotionNFT在基础模型和商业模型上显著提升了动作保真度和编辑准确性,MotionEdit-Bench上的基准结果显示其在生成性、判别性和人类偏好指标上均有一致提升。
引言
作者利用文本引导图像编辑的最新进展,解决了一个关键问题:现有模型在保持视觉一致性的前提下,难以准确修改图像中的动作、姿态或交互。尽管当前系统在颜色更改或对象替换等静态编辑方面表现出色,但在调整人物姿势或改变对象交互等动态变化上仍存在困难——这一局限性源于现有数据集要么忽略动作,要么提供低质量、不连贯的动作编辑示例。为解决此问题,作者提出了MOTIONEDIT,一个高质量基准,其图像序列精确配对,源自高分辨率视频,能够在姿态、朝向和交互等类别上实现真实且多样化的动作编辑评估。此外,作者进一步提出MotionNFT,一种强化学习框架,利用光流作为以动作为核心的奖励信号,引导编辑结果趋向物理合理且几何准确,从而在动作准确性和视觉连贯性方面超越现有模型。
数据集
- 作者使用MotionEdit数据集,这是一个专为以动作为核心的图像编辑设计的高质量数据集,目标是在保持身份、结构和场景一致性的前提下修改主体动作和交互。
- 该数据集基于两个合成视频源构建:ShareVeo3(基于Veo-3)和KlingAI视频数据集,均由最先进的文本到视频模型生成,提供清晰、时间连贯、主体和背景稳定的视频。
- 通过将视频分割为3秒片段并提取首尾帧来获取帧对,捕捉基于真实视频运动学的自然动作过渡。
- 每一对图像都经过Google的Gemini多模态大语言模型(MLLM)自动过滤,确保:(1)场景一致性(稳定的背景、视角、光照),(2)有意义的动作变化(例如,“未拿杯子 → 喝水”),(3)主体完整性(无遮挡、失真或消失),(4)高视觉质量。
- 编辑指令通过将MLLM生成的动作摘要优化为命令式、用户友好的提示(例如,“让女人把头转向狗”)生成,采用源自先前工作的提示标准化方法。
- 最终数据集包含10,157个高保真(输入图像、指令、目标图像)三元组——其中6,006个来自Veo-3,4,151个来自KlingAI——按90/10随机划分,得到9,142个训练样本和1,015个评估样本。
- 评估集构成MotionEdit-Bench,用于在生成性、判别性和人类偏好指标上评估动作编辑性能。
- 数据涵盖六类动作编辑:姿态/姿势、移动/距离、物体状态/构型、朝向/视角、主客体交互、主体间交互。
- 作者使用训练集应用MotionNFT,这是一种微调框架,通过光流计算动作对齐奖励,引导模型在编辑过程中更好地匹配真实动作的方向和幅度。
- 未提及裁剪或空间缩放;处理重点是通过基于MLLM的验证和指令生成构建元数据,确保图像对之间的语义和视觉保真度。
方法
作者采用MotionNFT,这是一种建立在扩散负样本感知微调(NFT)之上的后训练框架,以增强扩散模型的动作编辑能力。其核心创新在于将基于光流的动作对齐信号集成到NFT训练循环中,使模型不仅能学习应生成何种动作,还能学习应避免何种动作,由几何基础的奖励信号进行引导。
该框架操作于三元组输入图像:原始图像、模型生成的编辑图像和真实编辑图像。如下图所示,MotionNFT奖励流程首先从一个基于编辑提示条件化的流匹配模型(FMM)中采样候选结果。然后使用预训练的光流估计器将模型输出与真实编辑进行比较。预测动作(输入与编辑图像之间)和真实动作(输入与真实图像之间)均被计算为二维向量场 RH×W×2,并通过图像对角线归一化,以确保跨分辨率的尺度不变性。
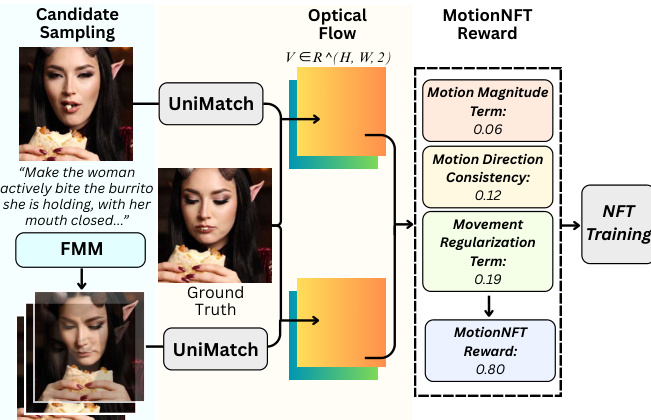
奖励由三个不同部分构成。首先,动作幅度一致性项 Dmag 测量归一化光流幅度之间的鲁棒 ℓ1 距离,使用指数 q∈(0,1) 抑制异常值影响。其次,动作方向一致性项 Ddir 计算单位光流向量之间的加权余弦误差,权重由真实动作的相对幅度导出,并通过阈值处理以聚焦于具有显著动作的区域。第三,运动正则化项 Mmove 引入铰链惩罚以防止出现极小动作的退化解,通过一个小的边界 τ 比较预测和真实光流幅度的空间均值。
这些组件被聚合为复合距离 Dcomb=αDmag+βDdir+λmoveMmove,其中超参数用于平衡各项贡献。复合距离随后被归一化并裁剪至 [0,1],取反形成连续奖励 rcont=1−D~,并量化为六个离散等级 {0.0,0.2,0.4,0.6,0.8,1.0},以与人类偏好建模对齐。该标量奖励通过组内归一化转换为最优性奖励,以调整不同提示和模型间的奖励分布偏移。
生成的奖励信号随后被输入扩散NFT训练目标。模型学习预测正速度 vθ+(xt,c,t) ——旧策略与当前策略的凸组合——以及负速度 vθ−(xt,c,t) ——旧策略远离当前策略的反射。训练损失是这些隐式策略与目标速度 v 之间平方误差的加权和,权重由最优性奖励 r 决定。这种双策略学习机制使模型能够导向高奖励的动作编辑,同时主动避免低奖励、几何不一致的编辑。
实验
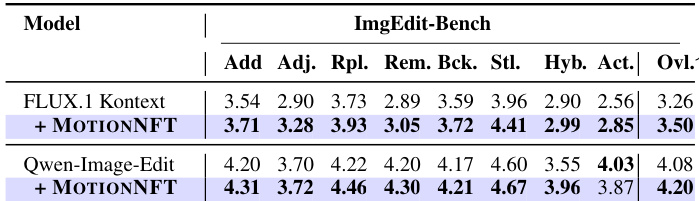
作者在ImgEdit-Bench上评估MOTIONNFT,发现将其应用于FLUX.1 Kontext和Qwen-Image-Edit后,在所有编辑子任务(包括添加、调整、替换、移除、背景、风格、混合和动作类别)上均提升或保持了性能。结果表明,MOTIONNFT在不牺牲动作特定性能的前提下增强了整体编辑能力,使两个基础模型的整体得分更高。
作者使用MotionNFT增强FLUX.1 Kontext和Qwen-Image-Edit模型,在MotionEdit-Bench的所有指标上均取得最高分,包括总体得分、保真度、保持性、连贯性、动作对齐得分和胜率。结果表明,MotionNFT在基础模型和所有对比方法上均持续提升了动作编辑质量和对齐效果,其中Qwen-Image-Edit变体整体表现最佳。
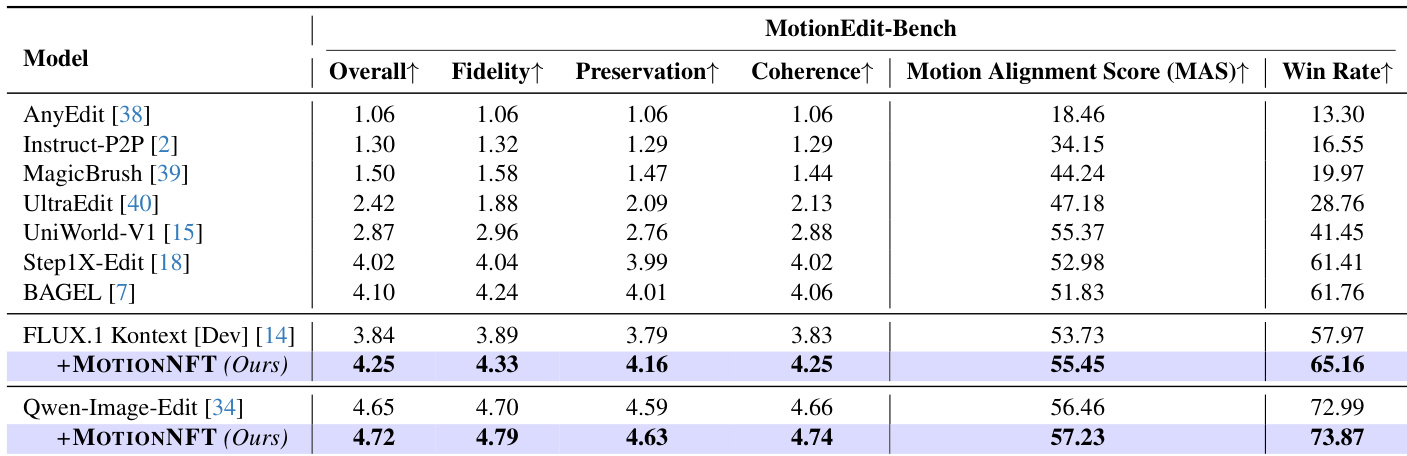
作者在MotionEdit-Bench上使用FLUX.1 Kontext和Qwen-Image-Edit作为基础模型评估MotionNFT,并与UniWorld-V2及仅基础模型进行比较。结果表明,MotionNFT在两个骨干模型上均持续提升了总体得分、动作对齐得分(MAS)和胜率,优于UniWorld-V2和基础模型。这证明了引入基于光流的动作引导可在不牺牲整体图像质量的前提下提升动作编辑精度。

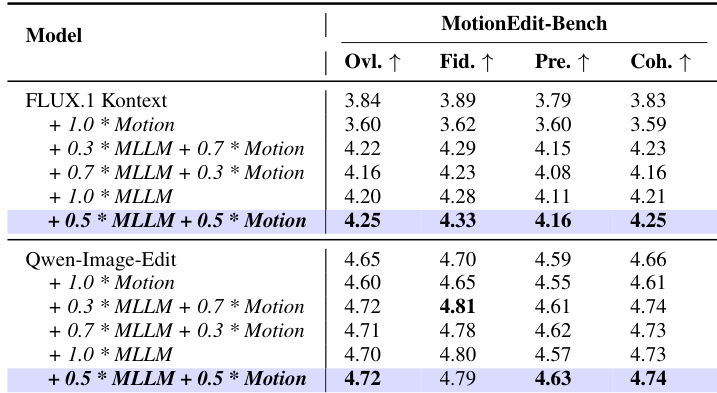
作者通过比较基于MLLM和基于光流的动作对齐奖励的不同权重配置来评估MotionNFT。结果表明,0.5:0.5的平衡权重在FLUX.1 Kontext和Qwen-Image-Edit上均取得最高整体性能,优于仅依赖单一奖励类型的配置。这表明结合语义引导与显式动作线索可产生最有效的动作编辑效果。