Command Palette
Search for a command to run...
HiF-VLA:通过运动表征实现的回望、洞察与前瞻,用于视觉-语言-动作模型
HiF-VLA:通过运动表征实现的回望、洞察与前瞻,用于视觉-语言-动作模型
Minghui Lin Pengxiang Ding Shu Wang Zifeng Zhuang Yang Liu Xinyang Tong Wenxuan Song Shangke Lyu Siteng Huang Donglin Wang
摘要
视觉-语言-动作(Vision-Language-Action, VLA)模型近年来通过将视觉与语言线索映射为具体动作,显著推动了机器人操作的发展。然而,大多数现有VLA模型均假设具备马尔可夫性质,仅依赖当前观测信息,因而存在时间上的短视问题,导致长时程任务中动作连贯性下降。在本研究中,我们提出将运动(motion)视为一种更为紧凑且信息丰富的时序上下文与世界动态表征,其能够捕捉状态之间的变化,同时有效过滤静态像素级噪声。基于这一思想,我们提出了HiF-VLA(Hindsight, Insight, and Foresight for VLAs)——一种统一的框架,利用运动信息实现双向时序推理。HiF-VLA通过“ hindsight prior”编码历史动态,借助“foresight reasoning”预测未来运动,并通过一个“hindsight-modulated joint expert”融合两者,从而实现“边执行边思考”(think-while-acting)的长时程操作范式。实验结果表明,HiF-VLA在LIBERO-Long与CALVIN ABC-D基准测试中均显著超越现有强基线模型,且推理延迟几乎无额外增加。此外,该方法在真实世界中的长时程操作任务中也取得了显著性能提升,充分验证了其在实际机器人应用场景中的广泛有效性。
一句话总结
来自西湖大学、浙江大学和港科大(广州)的研究人员提出了HiF-VLA,这是一种统一的视觉-语言-动作框架,利用运动信息实现双向时间推理,具备回溯与前瞻能力,可在极低延迟下显著提升长视野机器人操作任务的性能,并在真实世界中表现出色。
主要贡献
- HiF-VLA通过将运动作为时间动态的紧凑、低维表示,解决了视觉-语言-动作(VLA)模型中的时间短视问题,实现了高效的、结构化的双向时间推理,包括回溯(hindsight)和前瞻(foresight)机制。
- 该框架引入了一种回溯调制的联合专家模块(hindsight-modulated joint expert),将过去的运动先验与未来的运动预测相结合,实现了“边思考边行动”(think-while-acting)的范式,提升了长视野操作任务中的因果一致性和时间连贯性。
- HiF-VLA在LIBERO-Long和CALVIN ABC-D基准上达到了最先进的性能,并在真实机器人任务中表现出显著提升,且相比基线方法推理延迟几乎无增加。
引言
视觉-语言-动作(VLA)模型使机器人能够理解语言和视觉输入并生成控制动作,但大多数模型假设马尔可夫性质——仅依赖当前观测——导致在长视野任务中出现时间短视,影响性能。先前的方法尝试通过堆叠历史帧或预测未来子目标来引入时间上下文,但这些方法存在计算成本高、像素级冗余以及难以建模双向时间动态的问题。本文作者利用运动作为时间变化的紧凑、低维表示,提出了HiF-VLA框架,通过回溯(编码过去动态)、前瞻(预测未来运动)和洞察(理解当前任务上下文)实现双向时间推理。其核心贡献是一种回溯调制的联合专家模块,将这三种线索在统一空间中融合,实现“边思考边行动”的范式,在几乎无延迟增加的前提下提升了时间连贯性和因果一致性。
方法
作者提出了一种名为HiF-VLA的统一框架,通过整合结构化的历史先验和前瞻推理机制,扩展了基础的视觉-语言-动作(VLA)模型,以增强动作预测中的时间一致性和因果连贯性。该架构旨在联合预测未来运动和动作,条件于当前观测、任务指令以及压缩的历史运动先验,从而在视觉输入稀疏或被遮挡的情况下实现更鲁棒的决策。
该框架包含三个主要阶段:回溯先验获取、结合洞察的前瞻推理,以及回溯调制的联合专家融合。在第一阶段,使用MPEG-4视频编码标准将历史视觉动态编码为紧凑的运动向量(MVs)。这些MVs源自连续帧之间的宏块位移,构成了机械臂过去运动的结构化、低冗余表示。一个轻量级的ViT编码器(辅以浅层3D卷积)处理该MV流,生成紧凑的回溯标记 Mh∈RKh×d,作为时间先验,同时不破坏视觉语言模型(VLM)的模态对齐。
如下图所示,第二阶段利用VLM对未来的视觉动态和动作生成进行并行推理。模型将可学习的前瞻查询标记和空动作标记引入VLM嵌入空间,并与当前观测和任务指令拼接。VLM随后输出前瞻运动标记 Mf∈RKf×d 和动作隐变量标记 Af∈RKa×d,使模型能够同时推理视觉后果和运动指令。该设计避免了易产生失真和语义漂移的像素级未来帧预测,转而使用MVs作为结构化的时空目标。
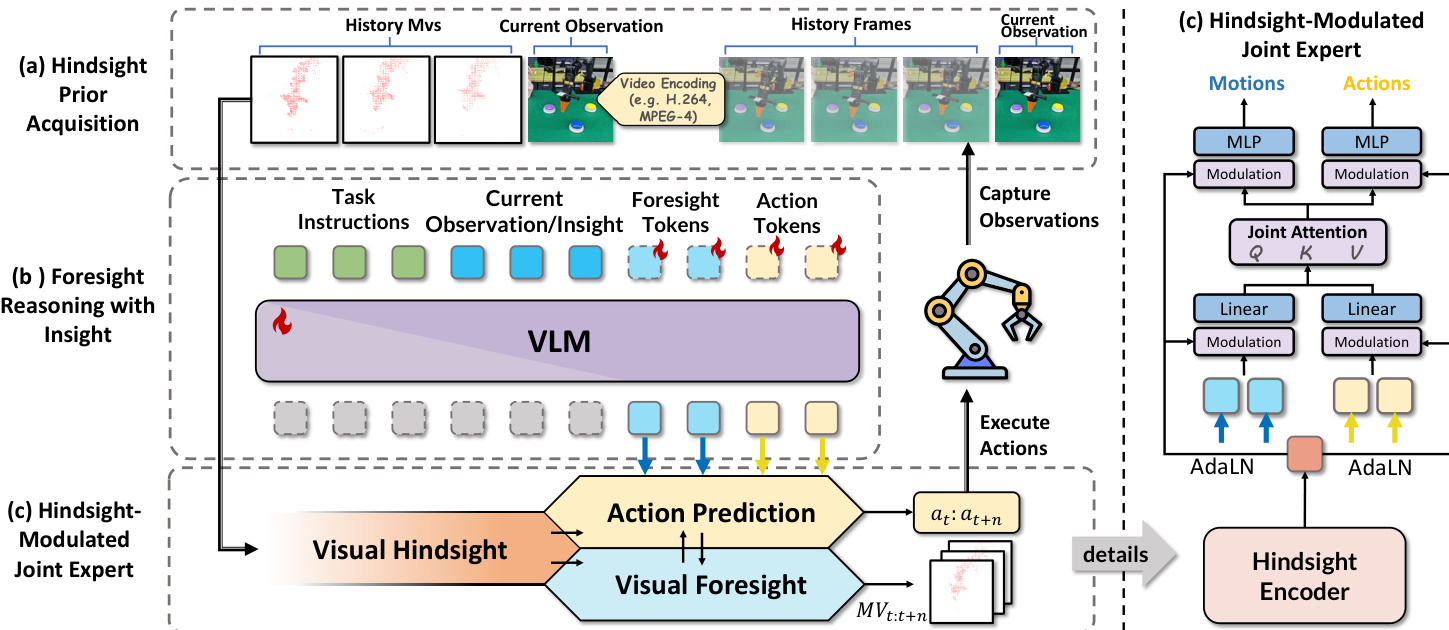
在最后阶段,回溯调制的联合专家模块在历史先验的引导下融合前瞻运动和动作表示。不同于直接将历史标记注入VLM(可能导致模态错位),模型将 Mh 投影为一个条件向量 hc,并通过自适应层归一化(AdaLN)调制运动和动作流。联合专家在 Mf 和 Af 的拼接序列上采用非因果自注意力机制,允许跨流交互,同时通过独立的前馈网络保持表示的解耦。位置信息通过旋转位置编码(RoPE)进行编码,以维持时空顺序。调制后的表示再通过各自的头部分别生成最终的预测运动序列 m~t:t+n 和动作序列 a~t:t+n。
在训练过程中,模型通过联合L1损失函数优化,同时惩罚动作和运动预测的偏差:
Lall=LA+λ⋅LMV,其中 λ=0.01 用于平衡运动重建与动作准确性的贡献。这种双目标训练确保模型学习生成物理合理且语义对齐的行为。在推理时,运动解码是可选的,为不需要显式运动预测的下游应用提供了灵活性。
整体架构使模型能够在统一的潜在空间中推理过去动态、预测未来后果并生成时间一致的动作,同时保持模态对齐并避免冗余。
实验
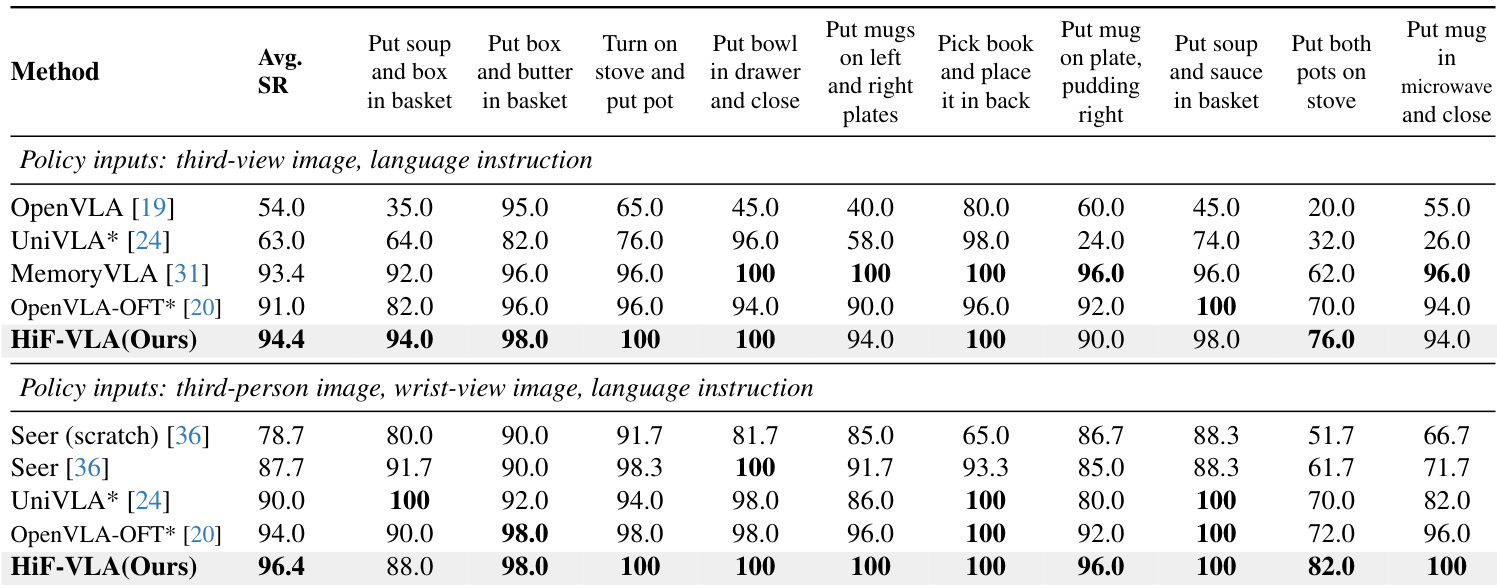
- 在LIBERO-Long和CALVIN ABC-D基准上评估,HiF-VLA实现了96.4%的成功率(多视角)和CALVIN上4.35的平均任务长度,超越了Seer、VPP和OpenVLA-OFT等先前最先进方法。
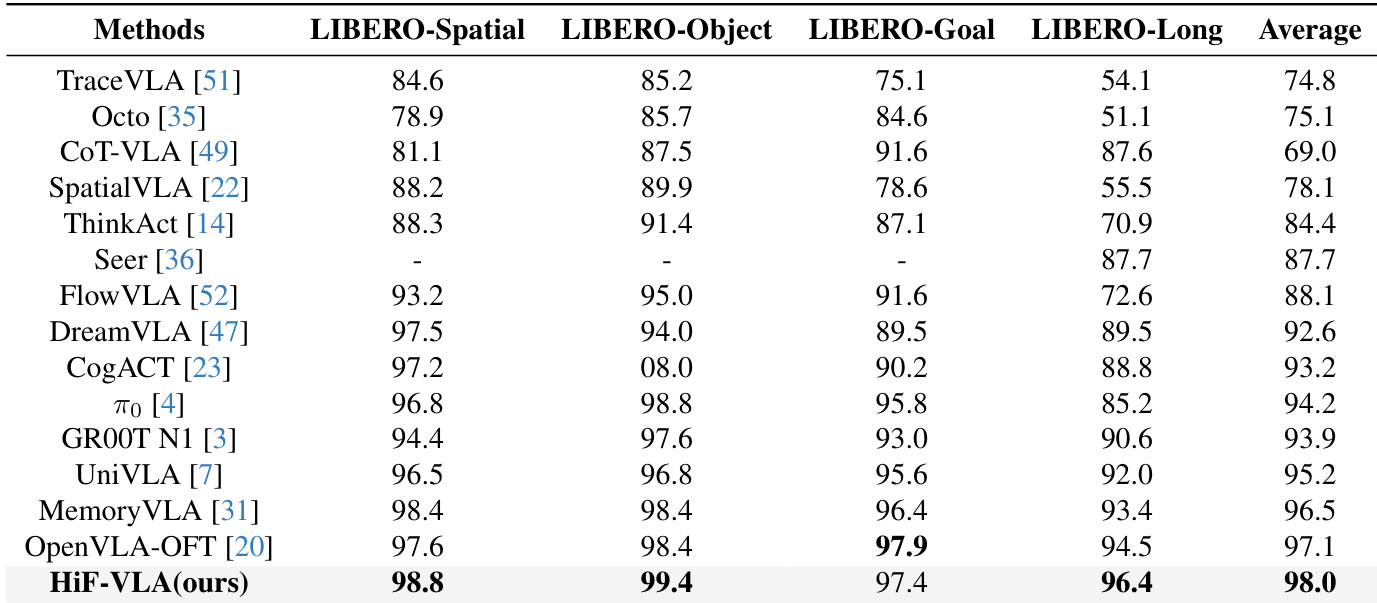
- 在完整的LIBERO基准(四个套件)上,HiF-VLA实现了98.0%的平均成功率,优于OpenVLA-OFT(97.1%)和MemoryVLA(96.5%)等现有方法。
- 消融实验表明,回溯长度为8且使用专家条件嵌入时性能最优,在LIBERO-Long上达到96.4%的成功率。
- HiF-VLA保持低推理延迟(1.67×基线),且计算可随上下文长度扩展,显著优于因上下文增长而延迟线性上升的多帧基线方法。
- 用基于运动的表示替代冗余的RGB历史,减少了GPU内存使用并提高了效率,同时在LIBERO-Long上比基线成功率提升2.2%。
- 在真实世界的AgileX Piper机器人上验证了长视野任务(如堆叠、覆盖、按钮按压),在基线(OpenVLA-OFT)失败的任务中仍取得高成功率,例如在按钮按压等视觉变化细微的状态转换中表现出鲁棒性。
HiF-VLA在所有四个LIBERO基准套件上均取得最高平均性能,尤其在具有挑战性的LIBERO-Long任务中表现突出。该模型在LIBERO-Spatial和LIBERO-Object上优于先前最先进方法,在LIBERO-Goal和LIBERO-Long上达到或超过顶尖性能,展示了其在处理多样化长视野操作任务中的强大泛化能力和有效性。
作者评估了前瞻运动损失权重λ对任务成功率的影响,发现当λ=0.01时性能最高,达到96.4%。结果表明,适度加权运动预测可增强规划能力而不 destabilize 模型,而过高或过低的权重则会降低效果。

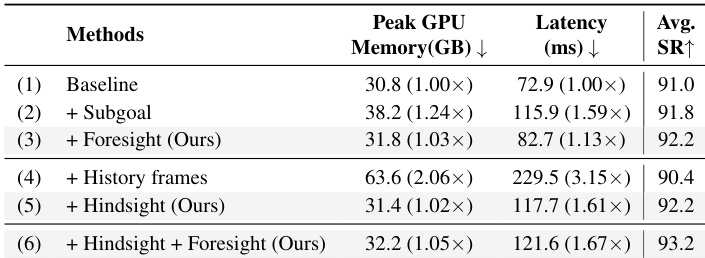
作者通过比较引入子目标、前瞻或历史帧输入的不同变体,评估HiF-VLA的效率与冗余性。结果表明,单独添加前瞻或回溯均能在极低延迟开销下提升成功率,而两者结合时性能最高(93.2%),延迟仅比基线增加1.67倍。相比之下,密集的历史帧显著增加延迟并降低性能,凸显了HiF-VLA使用紧凑运动表示避免冗余的优势。
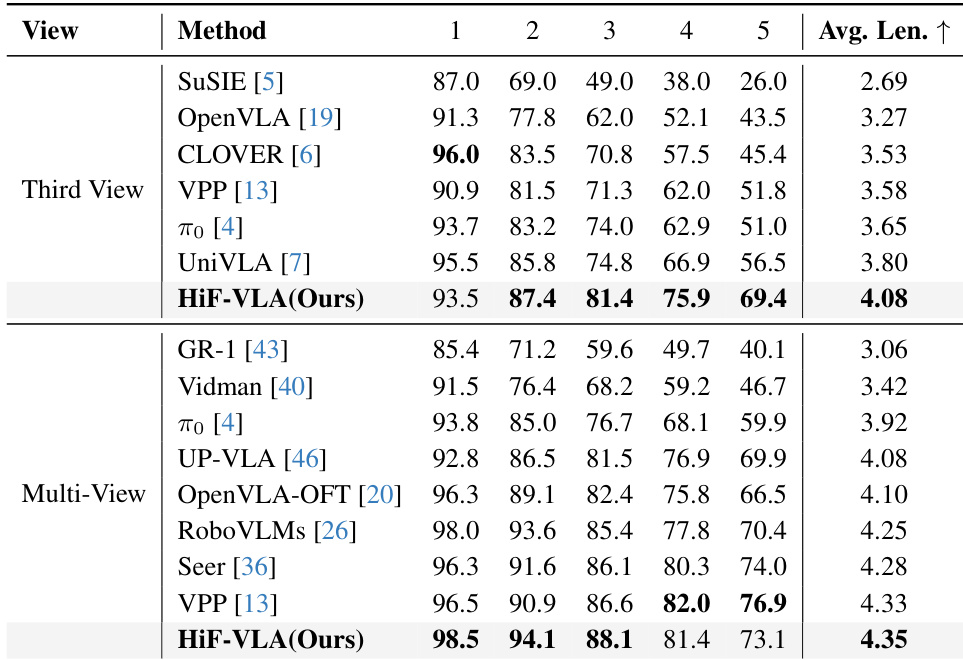
在CALVIN ABC-D基准的第三视角和多视角设置下,HiF-VLA均优于所有对比方法,分别实现了4.08和4.35的最高平均任务长度。该模型在未见环境中表现出卓越的泛化能力,并在连续任务步骤中保持稳定的性能提升,尤其在需要长视野推理的后期阶段表现突出。这些结果验证了HiF-VLA通过其双向时间建模架构处理复杂、长时间机器人任务的有效性。
在第三视角和多视角设置下,HiF-VLA在LIBERO-Long基准上均取得最高平均成功率,优于OpenVLA-OFT和UniVLA等先前最先进方法。该模型在各个长视野任务中均表现出持续优势,尤其在需要时间连贯性的复杂序列(如堆叠、覆盖和有序按钮按压)中表现优异。其在第三视角输入下的性能达到甚至超过多视角基线,凸显了其强大的时间推理能力,无需依赖额外的相机流。