Command Palette
Search for a command to run...
通过概念提示绑定从图像和视频中组合概念
通过概念提示绑定从图像和视频中组合概念
Xianghao Kong Zeyu Zhang Yuwei Guo Zhuoran Zhao Songchun Zhang Anyi Rao
摘要
视觉概念组合旨在将图像与视频中的不同元素整合为一个连贯统一的视觉输出,然而现有方法在从视觉输入中准确提取复杂概念,以及灵活融合图像与视频中的概念方面仍存在不足。为此,我们提出了一种名为“Bind & Compose”的一次性方法,通过将视觉概念与对应的提示词(prompt token)绑定,并利用来自不同来源的绑定词组合生成目标提示,实现灵活的视觉概念组合。该方法采用分层绑定结构,在扩散变换器(Diffusion Transformers)中实现跨注意力条件化,将视觉概念编码为相应的提示词,从而实现对复杂视觉概念的精确分解。为提升概念-提示词绑定的准确性,我们设计了一种“多样化吸收机制”(Diversify-and-Absorb Mechanism),引入一个额外的吸收令牌(absorbent token),在使用多样化提示进行训练时有效消除与概念无关的细节干扰。为进一步增强图像与视频概念之间的兼容性,我们提出一种时间解耦策略(Temporal Disentanglement Strategy),通过双分支绑定结构将视频概念的训练过程分为两个阶段,实现更优的时间建模。实验评估表明,与现有方法相比,本方法在概念一致性、提示保真度以及运动质量等方面均表现出显著优势,为视觉创意生成开辟了新的可能性。
一句话总结
来自香港科技大学、香港中文大学和港科大(广州)的研究人员提出了一种名为 BiCo 的单次视觉概念组合方法,该方法通过扩散变换器中的分层绑定器将视觉概念与提示词元绑定。BiCo 采用“多样化-吸收机制”和“时间解耦策略”,提升了绑定准确性和跨模态兼容性,实现了图像与视频元素的灵活、高保真组合,在概念一致性与运动质量方面表现优异。
主要贡献
- 视觉概念组合面临从视觉输入中准确提取复杂概念、以及灵活组合图像和视频元素的挑战;现有方法难以分解被遮挡或非物体类概念,且缺乏对跨域组合的支持。
- 提出的绑定与组合(BiCo)方法在扩散变换器中引入了分层绑定器结构,通过交叉注意力条件化将视觉概念绑定到文本提示词元,实现无需显式掩码的精确分解与灵活组合。
- 为提升绑定准确性和跨模态兼容性,BiCo 设计了“多样化-吸收机制”,在训练过程中滤除与概念无关的细节,并提出“时间解耦策略”配合双分支绑定器,对齐图像与视频的概念学习,在概念一致性、提示保真度和运动质量方面表现出优越性能。
引言
作者利用文本到视频扩散模型的最新进展,解决灵活视觉概念组合的难题——即从图像和视频中提取并融合多样化的视觉元素(如物体、风格和运动),生成连贯的输出。此前的方法在无手动掩码的情况下难以准确提取复杂或非物体类概念(如风格、光照),或在组合概念时灵活性不足,尤其在跨模态(图像 vs. 视频)场景下表现受限。许多方法依赖 LoRA 适配或联合优化,限制了可组合输入的数量和类型,且大多仅支持将图像主体用视频动作进行动画化,无法实现通用属性混合。
为克服这些局限,作者提出“绑定与组合”(BiCo)方法,这是一种单次方法,可将视觉概念绑定至扩散模型提示空间中的对应文本词元,通过简单的词元选择实现精确分解与灵活重组。该方法包含三项关键创新:用于在扩散变换器中精确编码概念的分层绑定器结构;“多样化-吸收机制”(Diversify-and-Absorb Mechanism),通过在训练中滤除无关细节提升绑定鲁棒性;以及“时间解耦策略”(Temporal Disentanglement Strategy),采用双分支绑定器对齐图像与视频的概念学习,确保跨模态组合的兼容性。该设计实现了来自异构源的空间与时间属性的无缝融合,显著提升了生成视频中的概念一致性、提示保真度和运动质量。
方法
作者采用模块化、两阶段框架——概念绑定与概念组合——实现从图像和视频等异构源中进行单次视觉概念组合。核心架构基于 DiT 构建的文本到视频(T2V)模型,并引入轻量级可学习的绑定模块,在多个粒度层级上编码视觉-文本关联。整体流程首先将每个视觉输入与其对应的文本提示进行绑定,随后通过选择特定概念的词元子集重组新提示,驱动生成连贯的合成输出。
在概念绑定阶段,每个视觉输入(无论是图像还是视频)均与其文本描述配对。绑定模块连接至 DiT 的交叉注意力条件化层,将提示词元转换为编码输入中视觉外观或运动特征的形式。该绑定以单次方式执行,每个源仅需一次前向-反向传播。更新后的提示词元在去噪过程中作为 DiT 交叉注意力层的键值输入。如框架图所示,该过程使模型在组合前独立内化每个概念的视觉语义。
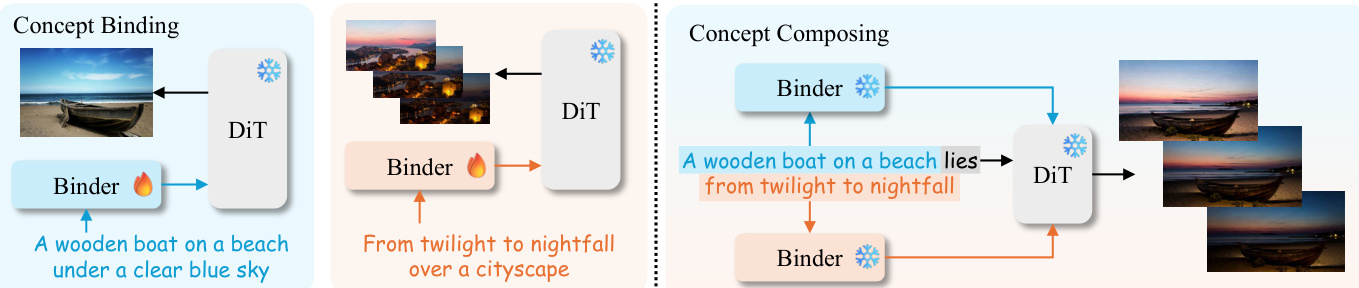
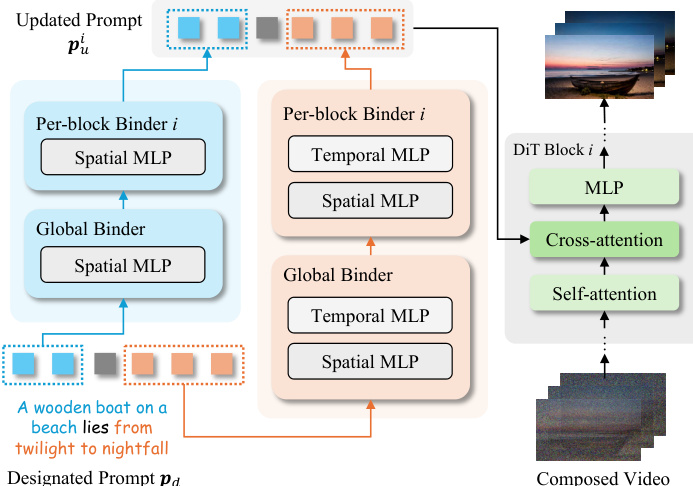
为支持细粒度的概念分解控制,作者引入了分层绑定器结构。该设计包含一个全局绑定器,用于对整个提示进行初步粗略更新,随后由每个 DiT 块对应的块级绑定器进一步细化提示词元。每个绑定器以 MLP 实现,并采用残差结构中的零初始化可学习缩放因子 γ:
f(p)=p+γ⋅MLP(p).对于视频输入,绑定器扩展为双分支架构,分别包含空间和时间 MLP,使模型能够解耦并独立优化空间与时间概念表示。在推理阶段,指定提示 pd 被分解为特定概念的片段,每个片段通过对应的绑定器处理。输出随后组合为每个 DiT 块的统一更新提示 pui,实现灵活的概念操控。
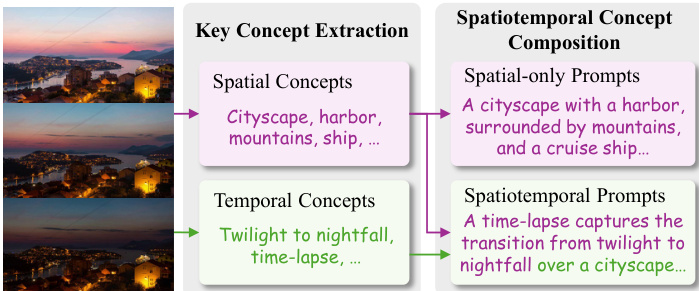
为提升概念-词元绑定的保真度,尤其是在单次约束下,作者提出“多样化-吸收机制”(DAM)。该机制利用视觉-语言模型(VLM)从视觉输入中提取关键空间与时间概念,并生成多个保留核心语义元素的多样化提示。VLM 首先识别关键概念(如“城市景观”、“黄昏至夜幕”或“港口”),然后将其组合成多种提示形式,包括仅空间和时空变体。为减轻无关视觉细节的干扰,训练期间在提示末尾添加一个可学习的吸收词元,推理时将其丢弃,从而有效滤除噪声并提升绑定准确性。
为解决静态图像与动态视频之间的时间异质性,作者提出“时间解耦策略”(TDS)。该策略将视频概念训练分为两个阶段:首先,仅使用空间提示对单帧进行训练,以对齐基于图像的绑定;其次,使用时空提示和双分支绑定器对完整视频进行训练。时间 MLP 分支初始化时继承自空间分支的权重,并通过可学习门控函数 g(⋅) 融合:
MLP(p)←(1−g(p))⋅MLPs(p)+g(p)⋅MLPt(p).该门控函数初始化为零,以确保优化路径稳定。这种分阶段、解耦的方法实现了图像与视频源概念的无缝组合,同时保持生成输出的时间连贯性。
实验
- BiCo 在 Wan2.1-T2V-1.3B 模型上进行视觉概念组合评估,绑定器在 NVIDIA RTX 4090 GPU 上每阶段训练 2400 次迭代。
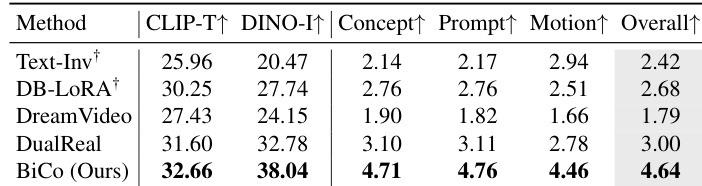
- 在来自 DAVIS 和互联网的 40 个测试案例上,BiCo 取得当前最优性能:CLIP-T 得分为 32.66,DINO-I 得分为 38.04;在人类评估中,整体质量得分为 4.64,相比 DualReal [55] 提升 54.67%(3.00)。
- 定性结果显示,BiCo 在运动迁移和风格组合任务中表现优异,而 Text-Inv、DB-LoRA、DreamVideo 和 DualReal 则出现概念漂移、信息泄露或静态输出等问题。
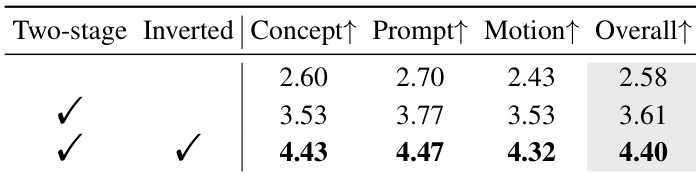
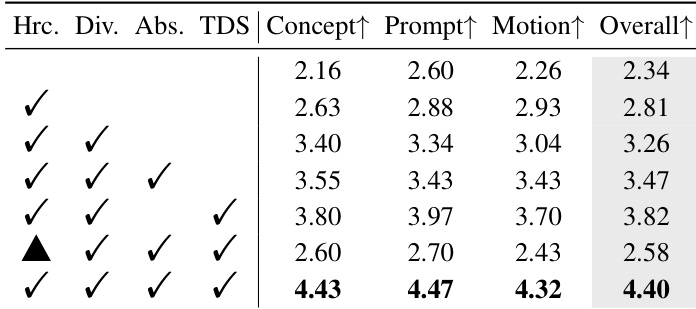
- 消融实验验证了分层绑定器、提示多样化、吸收词元和两阶段倒置训练策略的重要性,完整模型整体质量得分为 4.40,无两阶段训练时仅为 2.58。
- BiCo 支持灵活应用,包括概念解耦(如从混合场景中分离狗)和通过操作训练后的绑定器词元实现文本引导编辑。
- 局限性包括对词元重要性处理不均,以及缺乏常识推理能力,导致在复杂概念再现(如奇特帽子)和解剖结构错误(如五条腿的狗)时失败。
作者通过消融研究评估 BiCo 各组件的贡献,结果表明,结合分层绑定器、提示多样化、吸收词元和 TDS 策略可获得最高的人类评估分数,涵盖概念保持、提示保真度、运动质量和整体性能。移除两阶段倒置训练策略会显著降低所有指标,验证其在稳定优化中的关键作用。结果表明,每个组件逐步提升组合质量,完整配置取得最佳分数。
作者使用 BiCo 在自动指标和人类评估中均超越先前的视觉概念组合方法,在 CLIP-T、DINO-I 以及所有人类评分维度(包括概念、提示、运动和整体质量)上取得最高分。结果显示,BiCo 相比先前最优方法 DualReal,整体质量提升 54.67%,同时支持灵活的概念组合和非物体类概念提取。
作者评估了两阶段倒置训练策略对 BiCo 性能的影响,结果表明两个阶段和倒置机制均至关重要。数据表明,同时使用这两种技术可在所有人类评估指标(包括概念、提示、运动和整体质量)上取得最高分。若缺少该策略,性能显著下降,验证其在稳定训练和提升概念绑定中的作用。