Command Palette
Search for a command to run...
StereoWorld:面向几何感知的单目到立体视频生成
StereoWorld:面向几何感知的单目到立体视频生成
摘要
随着XR设备的广泛应用,对高质量立体视频的需求日益增长,但其制作过程仍面临成本高昂且易产生伪影的挑战。为应对这一难题,我们提出StereoWorld——一种端到端框架,该框架复用预训练的视频生成模型,实现从单目视频到立体视频的高保真生成。我们的方法在接收单目视频输入的同时,通过引入一种面向几何结构的正则化监督机制,显式保障生成立体视频的三维结构一致性。此外,框架还集成了一种时空分块(spatio-temporal tiling)策略,以实现高效且高分辨率的视频合成。为支持大规模训练与评估,我们构建了一个高清立体视频数据集,包含超过1100万帧图像,并严格对齐自然人眼瞳距(IPD)。大量实验表明,StereoWorld显著优于现有方法,在视觉保真度与几何一致性方面均展现出卓越性能。项目主页详见:https://ke-xing.github.io/StereoWorld/。
一句话总结
来自北京交通大学、Dzine AI 和多伦多大学的研究人员提出了 StereoWorld,这是一种端到端框架,利用预训练生成器结合几何感知正则化和时空分块策略,将单目视频转换为高保真立体视频,从而为扩展现实(XR)应用实现可扩展、时间一致的 3D 内容生成。
主要贡献
- StereoWorld 通过引入一种基于扩散模型的端到端框架,解决了从单目视频生成高保真立体视频的难题。该方法复用预训练视频生成器,联合以输入视频为条件,并通过视差和深度监督来强制保证几何准确性。
- 该方法采用时空分块策略,能够在保持时间连贯性和 3D 结构保真度的同时,高效合成高分辨率立体视频,克服了多阶段深度扭曲方法中存在的伪影和错位问题。
- 为支持训练与评估,作者构建了 StereoWorld-11M,这是首个大规模、公开可用的立体视频数据集,包含超过 1100 万帧,且对齐于自然人眼瞳距(IPD),并在客观指标和主观视觉质量上均展现出显著提升,达到当前最优性能。
引言
作者利用扩展现实(XR)设备推动的对沉浸式立体内容日益增长的需求,指出高质量立体视频至关重要,但因依赖专用双摄像头系统而成本高昂。以往将单目视频转换为立体视频的方法,要么依赖易出错的 3D 场景重建,要么采用多阶段的“深度扭曲-修复”流程,破坏了时空一致性,导致伪影和几何一致性差。为克服这些局限,作者提出 StereoWorld,这是一种基于扩散模型的端到端框架,通过联合 RGB 与深度建模,对预训练的单目视频生成器进行适配,直接合成高保真立体视频,并引入显式的几何感知监督。该方法确保了跨视角对齐和时间稳定性,并通过时空分块策略实现高分辨率生成。本工作的关键支撑是 StereoWorld-11M 的构建,这是首个大规模、高清、对齐人眼瞳距的立体视频数据集,可用于 XR 应用的训练与真实评估。
数据集
- 作者使用了一个新构建的数据集 StereoWorld-11M,专为对齐人类视觉感知的高保真立体视频生成而设计。
- 该数据集基于在线收集的 100 多部高清蓝光侧边并排(SBS)立体电影构建,涵盖动画、写实、战争、科幻、历史和剧情等多种类型,以确保视觉多样性。
- 所有视频均标准化为 1080p 分辨率、16:9 宽高比、24 fps 帧率的 SBS 格式,左右视图通过水平裁剪和拉伸提取。
- 为满足模型输入要求,每段视频被下采样至 480p 分辨率,并在每个片段中以固定间隔均匀采样 81 帧,以增强运动多样性和时间密度。
- 处理后的数据集作为基础模型的主要训练来源,提供经过立体对齐的视频片段,其基线距离匹配典型人眼瞳距(IPD),优化了自然观看舒适度。
方法
作者采用基于扩散变换器(DiT)架构的预训练文本到视频扩散模型作为立体视频合成框架的基础。该模型在由 3D 变分自编码器(3D VAE)导出的潜在空间中运行,将输入视频编码为紧凑表示。DiT 主干网络集成自注意力和交叉注意力模块,以联合建模时空动态和跨视图交互。训练遵循修正流(Rectified Flow)框架,前向过程定义数据与噪声之间的线性轨迹:zt=(1−t)z0+tϵ,其中 ϵ∼N(0,I)。模型学习一个速度场 vΘ(zt,t),通过常微分方程(ODE)将噪声 z1 映射回数据 z0,并使用条件流匹配(CFM)损失优化,回归目标向量场 ut(z0∣ϵ)。
为将此单目生成器适配于立体合成,作者引入一种条件策略,将左视图和右视图的潜在表示沿帧维度拼接,使模型能通过现有的 3D 注意力机制自然融合跨视图信息。该方法避免了架构修改,保持了计算效率。参见框架图以了解训练与推理流程的可视化概览。
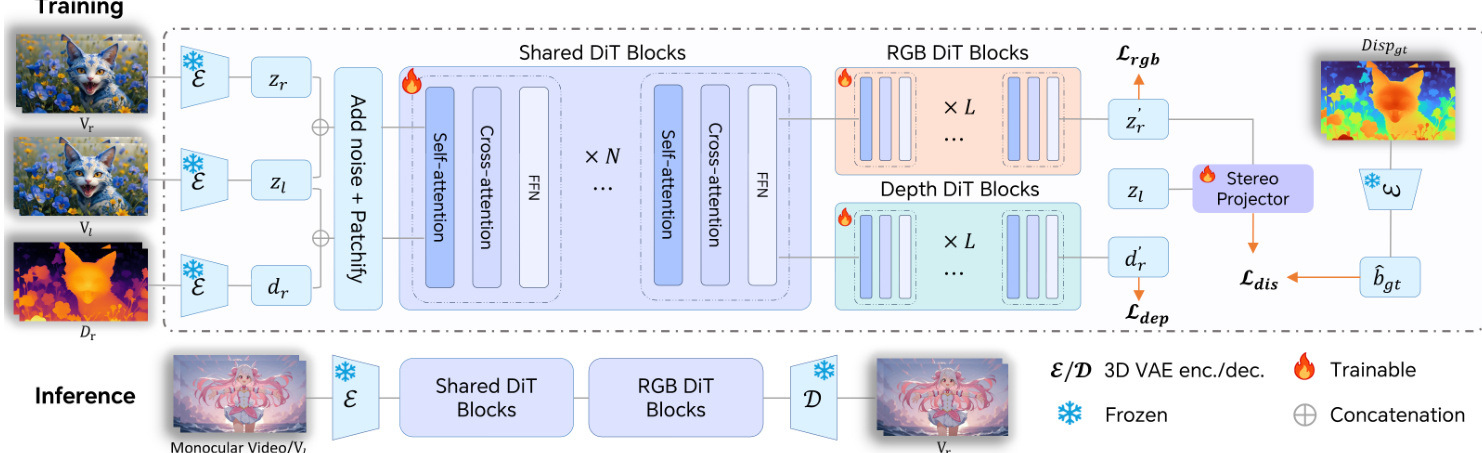
为增强几何一致性,作者引入几何感知正则化,包含视差和深度监督。训练期间,使用立体匹配网络预计算真实视差图,并用于监督一个轻量级可微立体投影器,该投影器从生成的右视图潜在表示和输入左视图潜在表示中估计视差。视差损失结合了对数尺度的全局一致性项和 L1 像素级误差项:Ldis=Llog+λL1LL1。这有效缓解了视图间的错位和时间漂移。
由于视差监督仅限于重叠区域,作者补充了深度监督。右视图的预计算深度图被编码到潜在空间,并通过相同的 CFM 目标训练一个独立的深度速度场。为避免 RGB 与深度任务之间的梯度冲突,最终的 DiT 模块被复制为两个专用分支——一个用于 RGB,一个用于深度——而早期模块保持共享,以捕获联合表示。整体训练目标结合了 RGB 重建、深度一致性与视差损失:L=Lrgb+Ldep+λdisLdis。
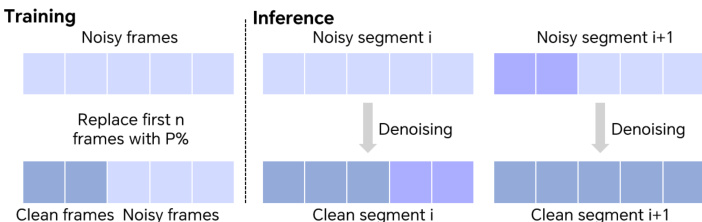
对于长视频生成,训练期间采用时间分块策略:以概率 p,将前 n 个带噪帧替换为干净的真实帧,以稳定学习过程。在推理阶段,长序列被划分为重叠片段,前一片段的末尾帧用于引导下一片段,以维持时间一致性。
对于高分辨率推理,采用空间分块策略:输入视频被编码为潜在表示,划分为重叠块,独立去噪后,通过融合重叠区域拼接,再进行解码。该方法实现了可扩展生成,不受内存限制。
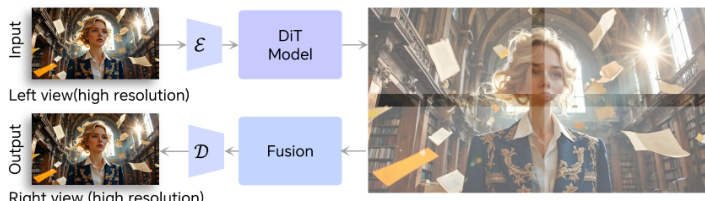
推理流程仅使用共享和 RGB DiT 模块,以单目视频为输入,生成几何一致的右视图视频,可直接用于立体成像(如红蓝立体)或 XR 设备渲染。

实验
- 在训练中引入时间分块策略,以概率性替换干净帧,提升长程时间一致性,减少生成视频中的闪烁现象。
- 采用基于块的潜在扩散实现空间分块,支持超越 480p 训练分辨率的高分辨率视频合成,同时保持空间细节和一致性。
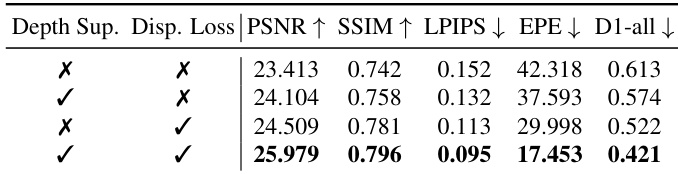
- 在定量指标上达到当前最优性能:在测试集上取得 25.98 PSNR、0.796 SSIM、0.095 LPIPS、0.502 IQ-Score 和 0.970 TF-Score,优于 GenStereo、SVG 和 StereoCrafter。
- 在几何准确性方面表现更优,EPE 为 17.45,D1-all 为 0.421,表明视差估计更准确,立体对应关系更强。
- 消融实验验证了深度与视差监督的重要性,完整模型取得最佳结果(25.98 PSNR、0.796 SSIM、17.45 EPE、0.421 D1-all)。
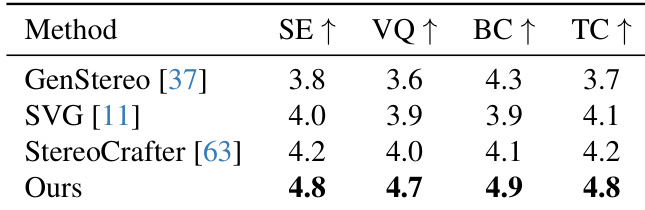
- 对 20 名参与者的主观评估显示,在所有感知指标上均有显著提升:立体效果(4.8)、视觉质量(4.7)、双眼一致性(4.9)、时间一致性(4.8),验证了更强的 3D 沉浸感和视觉保真度。
作者将所提方法与三种基线方法在视觉保真度和几何准确性方面进行定量比较。结果表明,该方法在 PSNR、SSIM、IQ-Score 上最高,在 LPIPS、EPE 和 D1-all 上最低,表明其图像质量和立体对应关系更优。在时间稳定性方面(由 TF-Score 反映),该方法也达到或超过基线水平。

作者在四个感知维度上进行了主观评估,发现所提方法在所有类别中得分均最高:立体效果、视觉质量、双眼一致性和时间一致性。结果表明,与所有基线相比,参与者认为生成的立体视频更具沉浸感、视觉更清晰、空间对齐更好、时间更稳定。
作者评估了深度和视差监督在模型中的影响,结果表明,结合两者可使所有指标达到最佳性能。单独视差监督在提升几何准确性方面优于单独深度监督,但同时使用两种信号的完整模型在 PSNR、SSIM 上最高,在 LPIPS、EPE 和 D1-all 上最低。这表明两种监督信号互补,对生成几何准确且视觉保真的立体视频至关重要。