Command Palette
Search for a command to run...
InfiniteVL:融合线性与稀疏注意力机制以实现高效、无限输入的视觉-语言模型
InfiniteVL:融合线性与稀疏注意力机制以实现高效、无限输入的视觉-语言模型
Hongyuan Tao Bencheng Liao Shaoyu Chen Haoran Yin Qian Zhang Wenyu Liu Xinggang Wang
摘要
窗口注意力(Window Attention)与线性注意力(Linear Attention)是缓解视觉-语言模型(VLMs)中二次方复杂度及不断增长的键值缓存(KV Cache)问题的两种主要策略。然而,我们观察到,基于窗口的VLM在序列长度超过窗口尺寸时性能显著下降,而线性注意力在信息密集型任务(如光学字符识别OCR和文档理解)中表现欠佳。为克服上述局限,本文提出InfiniteVL——一种具有线性复杂度的VLM架构,该架构通过融合滑动窗口注意力(Sliding Window Attention, SWA)与门控DeltaNet(Gated DeltaNet),实现了高效且稳定的多模态建模。为在资源受限条件下实现优异的多模态性能,我们设计了一套三阶段训练策略:知识蒸馏预训练、指令微调(Instruction Tuning)以及长序列监督微调(Long-sequence SFT)。令人瞩目的是,InfiniteVL仅需领先VLMs所需训练数据的2%以下,便不仅显著超越此前所有线性复杂度的VLM,还达到了主流基于Transformer架构VLM的性能水平,同时展现出优异的长期记忆保持能力。相较于采用FlashAttention-2加速的同规模Transformer-VLM,InfiniteVL在推理阶段实现了超过3.6倍的加速,且保持恒定的延迟与内存占用。在流式视频理解场景中,其能够稳定维持24 FPS的实时预填充(prefill)速度,同时完整保留长期记忆缓存。相关代码与模型已开源,地址为:https://github.com/hustvl/InfiniteVL。
一句话总结
来自华中科技大学和地平线机器人的研究人员提出了 InfiniteVL,这是一种线性复杂度的视觉-语言模型(VLM),通过结合滑动窗口注意力与门控 DeltaNet 来克服先前注意力机制的局限性。采用三阶段训练策略,InfiniteVL 仅用不到 Transformer 基础 VLM 2% 的训练数据即可达到相当性能,推理速度比使用 FlashAttention-2 加速的模型快 3.6 倍以上,并能在恒定内存下实现 24 FPS 的实时流式处理,从而高效支持长序列和视频理解。
主要贡献
- 我们提出了 InfiniteVL,一种线性复杂度的视觉-语言模型,结合滑动窗口注意力与门控 DeltaNet,解决了传统注意力机制效率低下的问题,能够在不依赖外部存储的情况下高效建模长上下文。
- 该模型利用蒸馏预训练和包含指令微调与长序列监督微调(SFT)的三阶段训练流程,在保持高效率的同时实现了优异性能,在长序列理解任务上优于现有方法。
- 实验表明,InfiniteVL 不仅在长序列任务上达到甚至超越了当前最优模型的性能,还在保持内存恒定的前提下实现了流式视频理解中 24 FPS 的实时性能。
引言
视觉-语言模型(VLM)在自动驾驶系统和视频理解等多模态应用中至关重要,但其可扩展性受限于 Transformer 架构中注意力计算的二次复杂度以及推理过程中不断增长的键值缓存。长输入序列加剧了计算和内存开销,尤其在资源受限的场景下更为明显。
以往扩展 VLM 的方法在细粒度感知与长程推理之间存在权衡。基于窗口的方法会丢弃窗口范围之外的全局上下文,而线性注意力模型在处理全局视觉上下文时仍面临较高的计算需求。
作者提出了 InfiniteVL,一种混合架构,将用于长期记忆的门控 DeltaNet 层与滑动窗口注意力(SWA)相结合,以在 OCR 和文档理解等信息密集型任务上保持性能,而这些任务是先前方法因二次复杂度而难以应对的。
InfiniteVL 通过将用于长期记忆的门控 DeltaNet 层与用于细粒度局部建模的滑动窗口注意力协同结合,解决了上述挑战。这种混合设计实现了高效的长上下文处理,同时在信息密集型任务上保持了性能。
方法
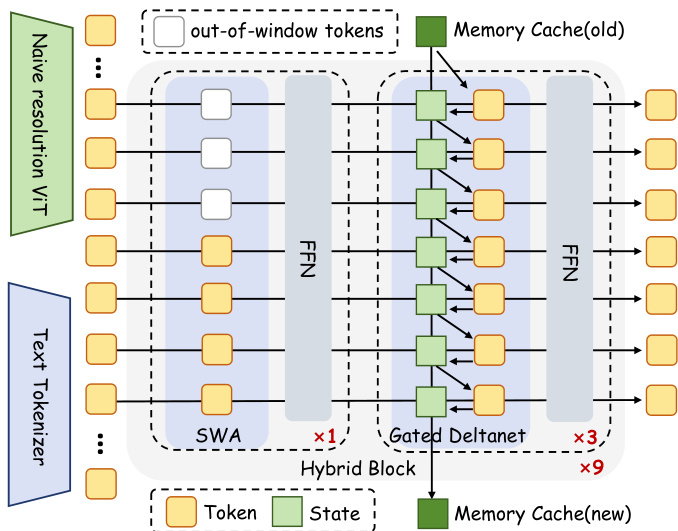
作者采用一种混合架构,结合局部与全局 token 混合机制,以在多模态场景中实现高效且与上下文长度无关的推理。该框架首先通过原生分辨率 ViT 编码视觉输入,通过标准分词器编码文本输入,然后将两者拼接并通过九个混合块(Hybrid Block)堆叠处理。每个混合块由一个滑动窗口注意力(SWA)层后接三个门控 DeltaNet 层组成,所有层均与前馈网络(FFN)交错连接,并通过带层归一化的残差路径相连。
参考框架图:SWA 层采用分组多头注意力,包含 16 个查询头和 2 个键值头,并使用 RoPE 进行位置编码。该设计确保在固定窗口大小(8192 个 token)内高效建模局部上下文,避免长距离位置外推带来的不稳定性。相比之下,门控 DeltaNet 层无需位置编码或权重偏置,维护一个固定大小的内存缓存以捕捉长程依赖。该缓存通过门控低秩变换更新,对累积状态应用类似 Householder 的旋转,其公式为:
St=St−1(αt(I−βtktkt⊤))+βtvtkt⊤,其中 αt 和 βt 是可学习的门控参数,分别调节记忆保留和更新缩放。作者进一步在每个门控 DeltaNet 层中插入一维卷积(窗口大小为 4)和输出门,以增强表达能力。
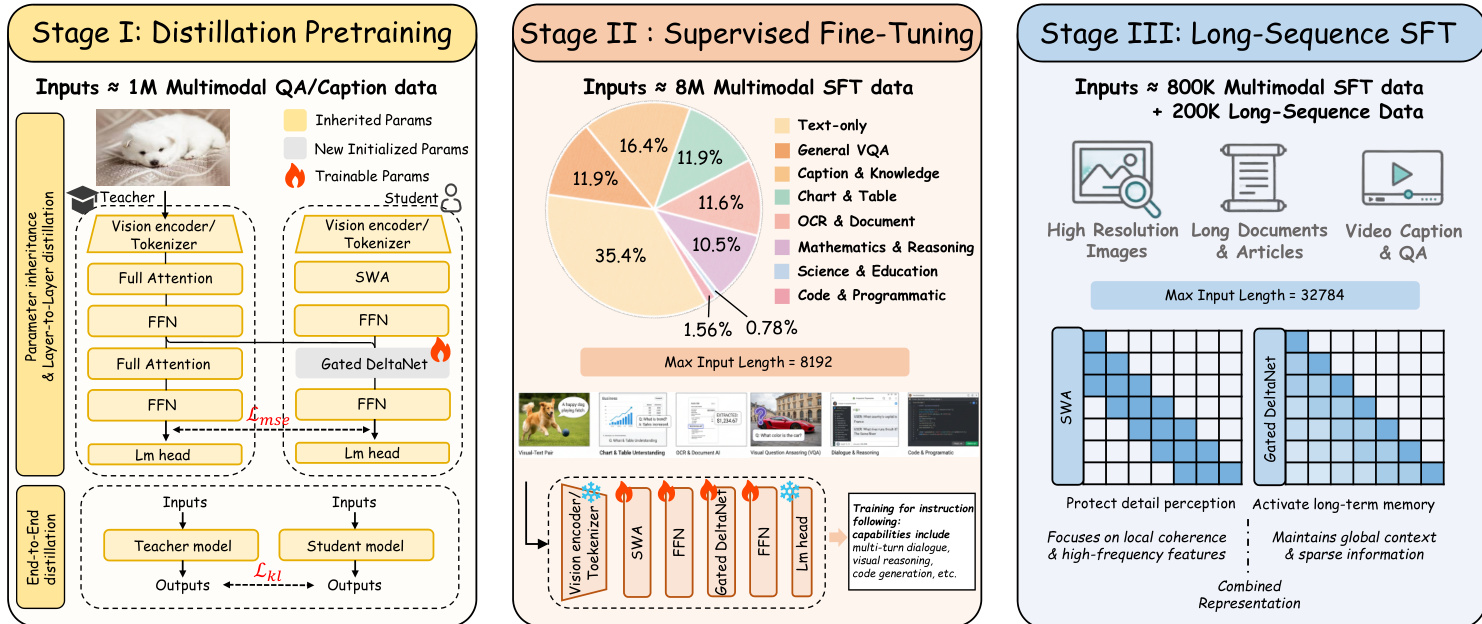
为高效训练该架构,作者采用三阶段训练策略。第一阶段(Stage I)从全注意力教师模型(Qwen2.5-VL)进行逐层和端到端蒸馏,将其注意力层替换为门控 DeltaNet,同时继承其余所有参数。通过对应层输出之间的均方误差(MSE)损失实现逐层对齐,随后使用 token 级别 logits 间的 KL 散度进行端到端蒸馏。第二阶段(Stage II)在多样化的多模态指令语料库上进行监督微调,提升指令遵循和推理能力,并将图像分辨率提升至 1344×1344。第三阶段(Stage III)将上下文长度扩展至 32,768 个 token,并引入来自视频和文档的长序列数据,通过 LoRA 训练,使模型能力聚焦于鲁棒的长程建模。
如下图所示:训练流程从参数高效的蒸馏过渡到指令微调,最终实现长序列适配,每一阶段逐步使模型接触更复杂的多模态交互和更长的上下文。
实验
- 使用 VLMEvalKit 在公开多模态基准上评估 InfiniteVL,显示其性能与基于 Transformer 及线性/混合型 VLM 相当。在 MMBench_test 上达到 79.0,RealworldQA 上为 67.3,MMMU_val 上为 44.0,在线性/混合模型中排名第二。
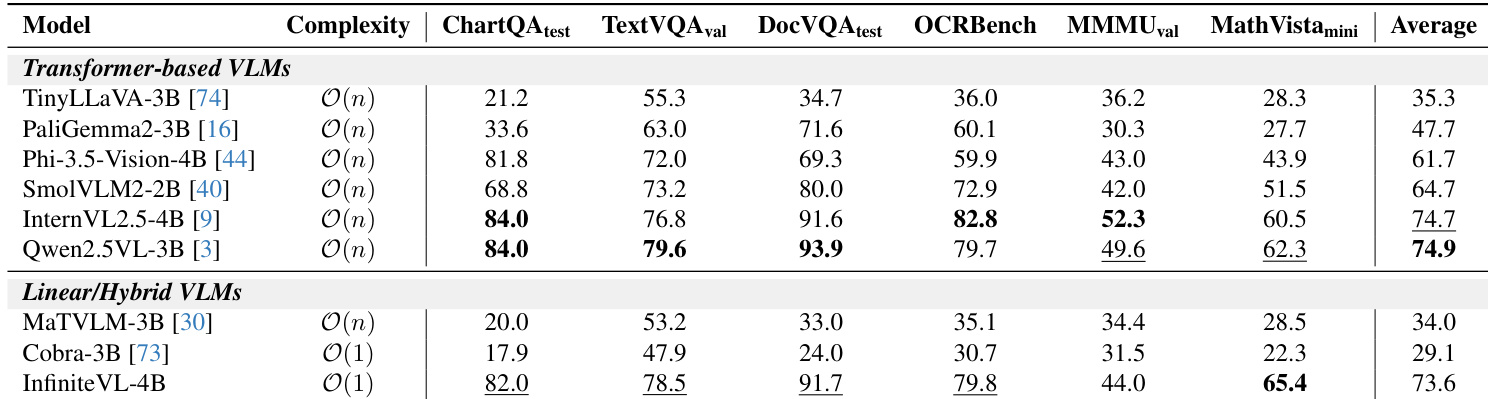
- 在文本密集型任务上表现优异:ChartQA_test 上达到 82.0,TextVQA_val 上为 78.5,DocVQA_test 上为 91.7,优于先前的线性模型,并接近基于 Transformer 的领先模型。
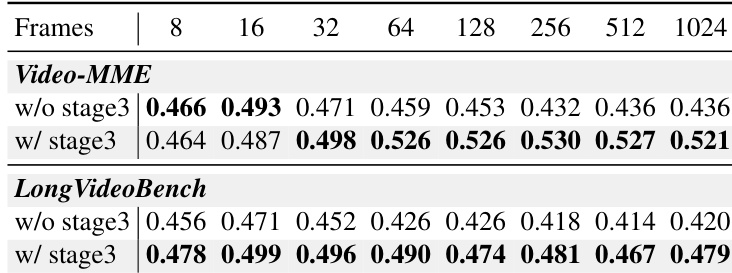
- 在 Video-MME 和 LongVideoBench 上验证了长度泛化能力:在 1024 帧时,InfiniteVL 仍保持稳定的理解与推理能力,可在多种场景下实现稳健性能。
结果表明,经过第三阶段长序列微调的 InfiniteVL 随着输入帧数超过 32 而保持或提升性能,而未经过第三阶段的版本则持续下降。这证实了第三阶段增强了长上下文泛化能力,即使在长达 1024 帧的超长序列下也能实现稳定理解。
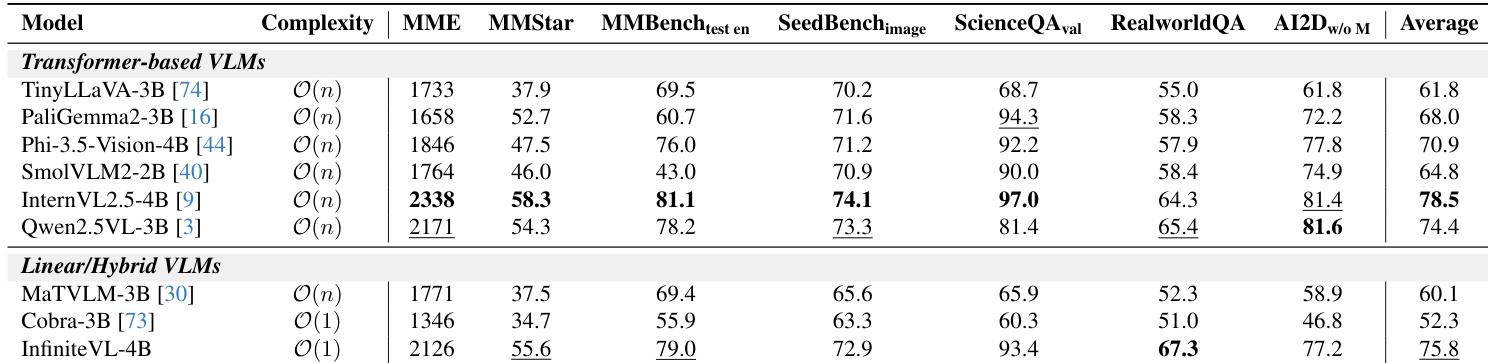
InfiniteVL-4B 是一种具有 O(1) 复杂度的线性/混合 VLM,在文本密集型和推理基准测试中表现出竞争力,在 ChartQA、TextVQA 和 MathVista 等多个类别中达到或超过更大的基于 Transformer 的模型。尽管其整体平均分略低于 Qwen2.5VL-3B,但在 MathVista 和 OCRBench 上表现更优,表明其在结构ured和数学推理任务上具有强大能力,尽管采用了恒定复杂度设计。
作者评估了不同线性序列建模模块,发现门控 DeltaNet 在关键文本密集型基准上优于 Mamba 和 GLA,在 DocVQA、TextVQA 和 OCRBench 上取得最高分。仅使用线性注意力无法收敛,而门控 DeltaNet 的状态压缩机制实现了稳定训练,并在细粒度视觉-语言任务上表现出更优性能。
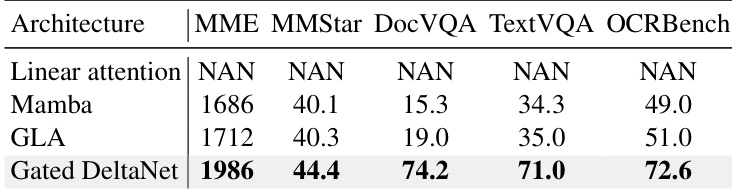
InfiniteVL-4B 在多模态基准上的平均得分为 75.8,优于其他线性/混合模型,并接近 InternVL2.5-4B 和 Qwen2.5VL-3B 等更大基于 Transformer 模型的性能。其在 RealworldQA 和 AI2D 上表现突出,展示了在恒定复杂度设计下强大的现实世界理解和视觉推理能力。
作者评估了滑动窗口注意力层比例变化对性能的影响,发现即使很小的比例(1/8)也能显著提升文本密集型任务得分,1/4 和 1/2 比例下进一步提升,但收益递减。结果表明,增加混合比例对文本密集型基准的提升大于通用多模态基准,1/2 配置取得最高的总体平均分。最终选择 1/4 作为默认配置,在文本密集任务性能与长程上下文处理效率之间取得平衡。
