Command Palette
Search for a command to run...
Voxify3D:像素艺术邂逅体素渲染
Voxify3D:像素艺术邂逅体素渲染
Yi-Chuan Huang Jiewen Chan Hao-Jen Chien Yu-Lun Liu
摘要
体素艺术(Voxel art)是一种在游戏与数字媒体中广泛应用的独特视觉风格,然而,从三维网格(3D mesh)自动生成体素艺术仍面临巨大挑战,主要源于几何抽象、语义保留与离散色彩一致性之间的矛盾需求。现有方法或过度简化几何结构,或无法实现体素艺术所特有的像素级精确性与调色板约束下的美学效果。为此,我们提出 Voxify3D——一种可微分的两阶段框架,通过将三维网格优化与二维像素艺术监督相结合,实现高质量体素艺术的自动化生成。本工作的核心创新在于三个组件的协同整合:(1)正交投影下的像素艺术监督机制,有效消除透视畸变,实现体素与像素之间的精确对齐;(2)基于图像块(patch-based)的CLIP语义对齐策略,在离散化过程中保持跨层级的语义一致性;(3)受调色板约束的Gumbel-Softmax量化方法,支持在离散色彩空间中进行可微优化,并具备可控的调色板策略设计能力。该框架系统性地解决了三大核心挑战:在极端离散化条件下保持语义完整性、通过体素渲染实现像素艺术的美学表达,以及端到端的离散优化能力。实验结果表明,Voxify3D在多种角色模型上均展现出卓越性能(CLIP-IQA达37.12分,用户偏好度达77.90%),并支持可控的抽象程度(2–8种颜色,分辨率提升20倍至50倍)。项目主页:https://yichuanh.github.io/Voxify-3D/
摘要
来自台湾大学的研究人员提出了 Voxify3D,这是一种可微分的两阶段框架,通过结合正交像素艺术监督、基于图像块的 CLIP 对齐以及调色板约束的 Gumbel-Softmax 量化,从 3D 网格生成高保真体素艺术。该方法实现了语义保持、精确的体素-像素对齐以及可控的颜色离散化,适用于游戏就绪资源的生成。
主要贡献
- Voxify3D 通过在六个标准视角上引入正交像素艺术监督,解决了从 3D 网格生成语义上有意义的体素艺术的挑战,消除了透视畸变,并实现了精确的体素-像素对齐,从而支持有效的基于梯度的优化。
- 该方法通过基于图像块的 CLIP 损失,在极端几何离散化(分辨率降低 20×–50×)下仍能保留关键语义特征,而标准感知损失在此情况下失效。
- Voxify3D 利用调色板约束的 Gumbel-Softmax 量化,实现了对离散颜色调色板(2–8 种颜色)的端到端优化,支持灵活的调色板提取策略,并在 CLIP-IQA 评分(37.12)和用户偏好(77.90%)方面表现出优越的美学质量。
引言
作者利用游戏和数字媒体中对风格化 3D 内容日益增长的需求,解决从 3D 网格自动生成高质量体素艺术的挑战。现有方法要么专注于 2D 像素艺术——由于投影错位和视图不一致,不适合 3D 应用——要么依赖于缺乏风格抽象的逼真神经渲染。先前的方法在极端离散化下也无法保留语义特征,并且在离散颜色优化方面存在困难,而程序化工具则需要大量手动调整。
作者的主要贡献是 Voxify3D,一种两阶段框架,将 3D 体素优化与 2D 像素艺术监督相结合,生成语义忠实且调色板受限的体素艺术。该方法通过紧密耦合的渲染和损失设计,克服了根本性的错位和量化问题。
关键创新包括:
- 正交像素艺术监督:使用六个标准视角消除透视畸变,实现精确的基于梯度的风格化。
- 分辨率自适应的基于图像块的 CLIP 损失:即使在 20×–50× 的离散化下,也能保留关键语义特征(如面部细节),而全局感知损失在此失效。
- 调色板约束的可微分量化:通过 Gumbel-Softmax 实现,支持用户可控的调色板提取(K-means、Max-Min、中值切割、模拟退火),实现对离散颜色空间(2–8 种颜色)的端到端优化。
方法
作者采用两阶段框架将 3D 网格转换为风格化的体素艺术,在几何保真度和语义抽象之间取得平衡。该流程从粗略的体素网格初始化开始,逐步在像素艺术监督下进行微调,结合语义引导和离散颜色量化,生成风格化输出。
在第一阶段,作者采用直接体素网格优化(Direct Voxel Grid Optimization, DVGO)构建显式的体素辐射场。该网格包含两个部分:用于空间占据的密度网格 d 和用于外观的 RGB 颜色网格 c=(r,g,b)。网格分辨率由将对象的包围盒划分为 (W/cell_size)3 个体素决定,其中 W 是标准正交图像宽度,cell_size 定义像素到体素的缩放比例。沿光线 r 的体渲染使用标准合成公式计算最终颜色 C(r):
C(r)=k=1∑NTkαkck,Tk=exp(−j=1∑k−1djδj),αk=1−exp(−dkδk),其中 N 是采样数,dk 是密度,δk 是步长,Tk 是累积透射率,αk 是第 k 个采样的不透明度。粗略网格通过复合损失进行优化:
Ltotal=Lrender+λdLdensity+λbLbg,其中 Lrender 最小化渲染颜色与目标颜色之间的均方误差,Ldensity 应用 TV 正则化以增强空间平滑性,Lbg 使用熵损失抑制背景伪影。该阶段为几何和颜色提供了稳定的初始化。
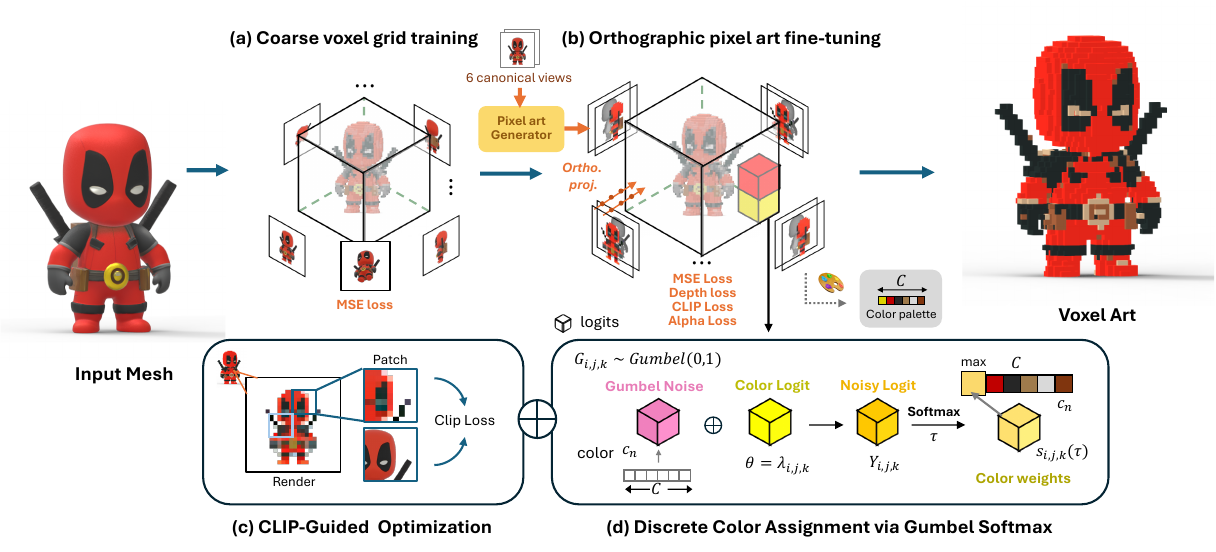
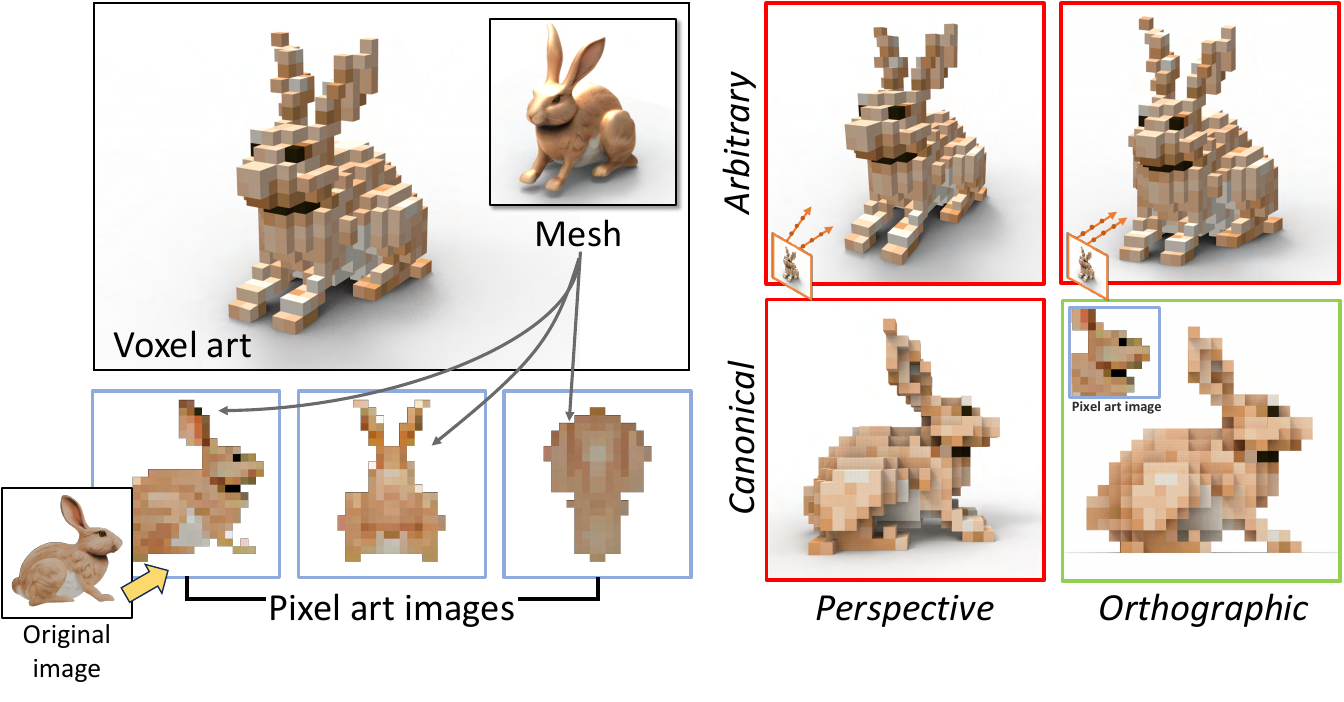
在第二阶段,作者使用从六个轴对齐视图生成的正交像素艺术监督对体素网格进行微调。该设置确保了无透视畸变的像素到体素对齐,如透视投影与正交投影的对比所示。正交光线定义为 ri(t)=oi+td,其中 oi 是像素 pi 的光线原点,d 是固定方向。作者应用三种关键损失:像素级 MSE Lpixel=∥C(r)−Cpixel∥22、深度一致性 Ldepth=∥D(r)−Dgt∥1 和 alpha 正则化 Lα=∥Mα⊙αˉ∥2,其中 Mα 是来自像素艺术 alpha 通道的二值掩码,αˉ 是累积不透明度。这些损失共同保留结构、确保清晰的轮廓,并抑制背景区域的漂浮密度。
为了在风格化过程中保持语义对齐,作者引入了基于 CLIP 的感知损失。一半的光线被采样以形成图像块,并从渲染的图像块 I^patch 和对应的基于网格的图像块 Ipatchmesh 中提取 CLIP 特征。损失计算如下:
Lclip=1−cos(CLIP(I^patch), CLIP(Ipatchmesh)),其中余弦相似性鼓励语义保真度,同时允许风格化抽象。
为了实现具有统一调色板的清晰、风格化输出,作者将 RGB 颜色网格替换为学习得到的颜色-对数网格。每个体素 (i,j,k) 存储一个对数向量 λi,j,k∈RC,其中 C 是从像素艺术视图中提取的预定义调色板中的颜色数量。在训练期间,向对数添加 Gumbel 噪声 Gi,j,k∼Gumbel(0,1) 以生成噪声对数:
Yi,j,k=λi,j,k+Gi,j,k.然后通过温度控制的 softmax 计算选择概率:
si,j,k,n(τ)=∑n′=1Cexp(Yi,j,k,n′/τ)exp(Yi,j,k,n/τ),其中 τ 在训练期间逐渐退火,从软探索过渡到离散选择。最终的 RGB 值是调色板上的加权和:
RGBi,j,k=n=1∑Csi,j,k,n⋅cn.在前向传播中,直通估计器使用 argmaxnsi,j,k,n 进行离散选择,而梯度通过软权重流动。训练后,体素颜色分配为:
RGBi,j,kvoxel=cargmaxnλi,j,k,n.这使得在训练期间保持可微性的同时,实现对离散颜色分配的端到端优化。
整体微调损失为加权和:
Ltotal=λpixelLpixel+λdepthLdepth+λalphaLalpha+λclipLclip,其中 Lpixel、Ldepth 和 Lalpha 监督几何和外观,Lclip 提供语义引导。训练调度优先考虑早期的 CLIP 损失(直到 6000 次迭代),然后通过 Lalpha 转向轮廓细化。在 4500 次迭代后,优化限制在前视图,以细化显著特征同时保持全局一致性。
实验
- 在八个角色网格上的定性比较表明,所提方法在 25×–50× 分辨率下保持了锐利边缘和关键特征(如耳朵、眼睛),在一致性、风格化和语义对齐方面优于 IN2N、Vox-E 和 Blender。
- 在 35 个角色网格上使用 CLIP-IQA 进行的定量评估表明,该方法在 GPT-4 生成的提示与渲染图像之间的平均余弦相似性最高,表明其在语义保真度和风格化方面表现优越。
- 消融研究证实了关键组件的必要性:移除像素艺术监督、正交投影、粗略初始化、深度损失、CLIP 损失或 Gumbel Softmax 会导致结果模糊、失真或颜色模糊。
- 包含 72 名参与者的用户研究表明,该方法在抽象细节上获得 77.90% 的投票,在视觉吸引力上获得 80.36%,在几何保持上获得 96.55%,显著优于四个基线方法。
- 包含 10 名艺术背景参与者的专家研究表明,88.89% 的参与者更偏好使用 Gumbel Softmax 进行颜色量化的结果,突显其在实现清晰边缘和主导色调方面的作用。
- 通过 K-means、中值切割、Max-Min 和模拟退火方法,在 2–8 种颜色范围内展示了颜色调色板的可控性,其中 K-means 为默认方法。
- 额外比较表明,由于多视图优化,该方法在可控体素分辨率和颜色方面优于 Gemini 3,在几何保真度方面优于 Rodin。
- 运行时间分析报告在 RTX 4090 上总生成时间不到 2 小时(第一阶段 8.5 分钟,第二阶段 108 分钟),快于 SD-piXL(约 4 小时)。
- 在低分辨率下高度复杂的形状上会出现失败案例,表明未来在自适应体素网格方面具有潜力。
作者使用 CLIP-IQA 评估语义保真度,计算 GPT-4 生成的提示与 35 个角色网格的体素渲染输出之间的余弦相似性。结果表明,该方法获得 37.12 的最高分,优于所有基线方法,包括 Blender(36.31)、Pixel(35.53)和 Vox-E(35.02),而 IN2N 得分最低,为 23.93。这证实了其在语义对齐和风格化抽象方面的优越性。

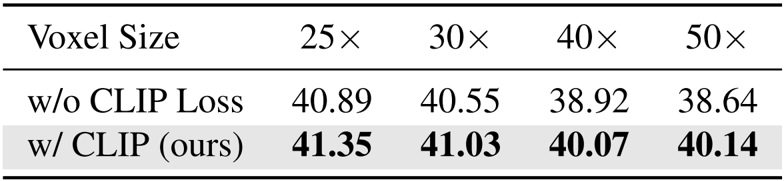
作者评估了 CLIP 损失在不同体素分辨率下的影响,表明与无 CLIP 损失的消融相比,引入 CLIP 损失始终能改善语义对齐。结果表明,在所有测试的体素尺寸(25× 到 50×)下,CLIP-IQA 分数更高,证实 CLIP 损失在体素抽象过程中增强了角色身份的保持。
作者通过包含 72 名参与者的用户研究,将该方法与四个基线方法进行比较,评估其在抽象细节、视觉吸引力和几何保持方面的表现。结果表明,该方法在抽象细节上获得 77.90% 的投票,在视觉吸引力上获得 80.36%,在几何保真度上获得 96.55%,显著优于所有替代方法。

作者通过包含 10 名艺术背景参与者的用户研究评估颜色量化,比较了使用和不使用 Gumbel-Softmax 的 10 组示例。结果表明,88.89% 的参与者更偏好使用 Gumbel-Softmax 生成的体素艺术输出,突显其在产生清晰边缘和主导色调方面的作用。
