Command Palette
Search for a command to run...
LongCat-Image 技术报告
LongCat-Image 技术报告
摘要
我们推出了LongCat-Image,这是一个开创性的开源双语(中文-英文)基础图像生成模型,旨在解决当前主流模型在多语言文本渲染、逼真度、部署效率以及开发者可访问性方面存在的核心挑战。1)我们通过在预训练、中段训练及监督微调(SFT)阶段实施严格的高质量数据筛选策略,并在强化学习(RL)阶段协同使用经过筛选的奖励模型,实现了这一突破。该策略使模型达到新的最先进水平(SOTA),在文本渲染能力与视觉逼真度方面表现卓越,显著提升了图像的美学质量。2)尤为突出的是,该模型树立了中文字符渲染的新行业标准。其能够准确生成复杂且罕见的汉字,无论在字符覆盖范围还是识别精度上,均超越现有主流开源与商业解决方案。3)模型凭借其紧凑的架构实现了卓越的运行效率。其核心扩散模型仅包含60亿参数,远小于当前领域常见的近200亿甚至更大的混合专家(Mixture-of-Experts, MoE)架构。这一轻量化设计极大降低了显存占用,实现了快速推理,显著削减了部署成本。除图像生成外,LongCat-Image在图像编辑任务中同样表现优异,在标准基准测试中达到SOTA水平,且编辑一致性优于其他开源模型。4)为全面赋能社区,我们构建了迄今为止最完善的开源生态系统。本次发布不仅包含多种文本到图像生成与图像编辑模型版本,涵盖中段训练与训练后阶段的完整模型检查点,还开放了完整的训练流程工具链。我们坚信,LongCat-Image的开放性将为开发者与研究者提供坚实支持,持续推动视觉内容创作技术的边界发展。
一句话总结
美团龙猫团队提出 LongCat-Image,一个拥有60亿参数的中英双语扩散模型,在多语言文本渲染、照片级真实感和图像编辑方面达到业界领先水平,通过精心设计的数据流水线与奖励引导训练实现,其效率和中文字符覆盖范围优于更大规模的MoE模型,同时依托全面开源生态实现低成本部署。
主要贡献
-
LongCat-Image 提出一种新颖的中英双语基础图像生成模型,在预训练、中段训练和SFT阶段均通过严格的数据筛选,并结合RLHF阶段使用的精选奖励模型,显著提升文本渲染、照片级真实感与美学质量,实现业界领先性能。
-
该模型在中文字符渲染方面树立新标准,支持复杂罕见汉字,覆盖与准确率均优于开源及商业模型,得益于专为多语言文本保真度设计的数据与训练策略。
-
模型采用紧凑的60亿参数扩散架构,远小于典型的200亿以上MoE模型,实现低VRAM占用、快速推理与低成本部署,同时在图像编辑任务中保持SOTA性能,并在标准基准测试中展现强大一致性。
引言
作者提出 LongCat-Image,一种轻量级中英双语图像生成与编辑基础模型,旨在解决多语言文本渲染、照片级真实感与部署效率等关键挑战。以往工作依赖大规模模型(通常200亿及以上,含MoE架构),导致计算成本高昂、推理缓慢且可及性受限,尽管质量提升微乎其微。此外,现有模型在复杂中文字符准确渲染与图像编辑视觉一致性方面仍存在不足。作者的核心贡献是一个60亿参数的扩散模型,在多个基准测试中实现SOTA性能的同时,显著降低VRAM使用与推理延迟。这一成果得益于严谨的多阶段数据筛选流程:早期训练排除AIGC生成内容,SFT阶段使用人工筛选的合成数据,RL阶段引入AIGC检测模型作为奖励信号以增强真实感。针对中文文本渲染,采用字符级编码与背景干净的合成图文数据,实现更优的覆盖与准确率。在图像编辑方面,采用从中段训练权重初始化的独立模型,结合多任务联合训练与高质量人工标注数据,实现SOTA的一致性与指令遵循能力。最后,团队发布完整的开源生态系统,包含多个检查点与完整训练代码,以加速社区驱动的创新。
数据集
-
数据集包含12亿条从多样化来源(开源仓库、合成流水线、视频序列、网络级交错语料)精心筛选的样本,构成大规模、高质量的生成建模训练语料库。
-
关键子集包括:
- 开源数据集(OmniEdit、OmniGen2、NHREdit):经过严格清洗与指令重写,生成高保真源-目标图像对。
- 合成数据:通过专家模型生成特定编辑任务(如对象操作、风格迁移、背景更改)的图像,由多模态大模型(MLLMs)生成指令,专家模型生成目标图像。
- 交错网络语料:从自然图像-文本序列中挖掘隐式编辑信号,经筛选与重写以适配训练,但受限于资源强度,规模仍有限。
-
数据通过四阶段处理流程:
- 过滤:通过MD5哈希与SigLIP相似度去除重复项;排除低分辨率图像(最短边 < 384px)、极端长宽比(0.25–4.0)、带水印内容,以及使用内部检测器排除AI生成内容(AIGC);仅保留LAION-Aesthetics评分 ≥ 4.5 的图像。
- 元数据提取:利用视觉语言模型(VLMs)与专用模型提取五项属性——类别、风格、命名实体、OCR文本与美学质量。
- 多粒度描述生成:VLMs基于提取的元数据与提示模板,生成从实体标签到详细描述的多层次图像描述。
- 分层组织:数据按风格质量与内容多样性构建金字塔结构,支持渐进式、多阶段训练。
-
美学质量评估采用双维度框架:质量(通过信号统计与无参考深度指标如MUSIQ和Q-Align衡量技术保真度),艺术性(通过VLM分析构图、光照与色调,辅以Q-Align-Aesthetics)。
-
图像编辑训练使用独立的高保真SFT数据集,由真实照片、专业修图与合成来源构建,采用严格的人工介入过滤机制,确保源图与编辑图在结构上对齐——这对维持生成稳定性与一致性至关重要。
-
模型训练采用T2I与编辑数据混合策略,编辑训练部分包含多样化的指令类型与任务粒度,涵盖基于参考的生成、结构修改与视角变换。
-
文本渲染能力通过OCR集成增强,提取的文本被纳入描述中,并通过人工介入检查验证,尤其针对海报、菜单、标识等复杂布局。
-
数据集支持通过CEdit-Bench进行评估,该基准包含1,464对双语编辑样本,覆盖15个细粒度任务类别,旨在克服现有基准在任务覆盖、粒度与指令多样性方面的局限。
方法
作者采用混合MM-DiT(多模态扩散Transformer)架构,基于FLUX.1-dev框架,实现高保真图像生成。核心模型为DiT(扩散Transformer),用于处理图像与文本的潜在表示。整体框架设计如下方图示,展示模型结构与数据流。

模型在初始层采用双流注意力机制,分别处理文本与图像潜在表示,随后在后续层过渡为单流机制。该设计保持双流与单流模块参数比例约为1:2。VAE组件采用FLUX.1-dev实现,将输入图像在空间上压缩8倍,再进行2×2令牌合并,最终序列长度为16×16H×W,再输入DiT模块。
文本编码器负责将用户提示嵌入连续表示,采用统一的Qwen2.5VL-7B模型。该选择增强了多语言兼容性,尤其在中文方面表现优异,并避免传统将文本嵌入注入时间步嵌入进行adaLN调制的做法,因实证表明其性能提升可忽略不计。对于视觉文本渲染,使用字符级分词器处理引号内内容,提升数据效率与收敛速度,无需专用编码器的额外开销。
位置嵌入采用3D多模态旋转位置嵌入(MRoPE)变体。该嵌入的第一维用于模态区分,区分噪声潜在、文本潜在与编辑任务中的参考图像潜在。其余两维编码图像的2D空间坐标;对于文本,两个坐标设为相同值,类比1D-RoPE,支持任意长宽比的灵活生成,并与其它模态无缝交互。
模型训练过程采用多阶段流水线,如下方图示。该流程包含三个阶段:预训练、中段训练与后训练。预训练阶段采用渐进式多分辨率策略,高效获取全局语义知识并优化高频细节。中段训练阶段作为关键桥梁,通过在高保真、精选数据集上训练,提升模型基础生成质量,强化美学先验与视觉真实感。后训练阶段聚焦对齐与风格化,包含监督微调(SFT)与强化学习(RL)。SFT阶段使用真实与合成数据混合集,优化照片级属性与风格保真度;RL阶段采用DPO与GRPO等先进对齐技术,提升指令遵循能力与生成质量。

针对图像编辑,模型架构增加图像条件分支。参考图像通过VAE编码为潜在表示,并通过操控3D RoPE嵌入的第一维,与噪声潜在区分开。这些参考令牌沿序列维度与噪声潜在拼接,作为扩散视觉流的输入。源图像与指令输入多模态编码器(Qwen2.5-VL),并使用特定系统提示区分编辑任务与标准文生图生成。该模型架构整体示意图如下图所示。

实验
- 分层实验验证分阶段训练的有效性:预训练阶段仅使用0.5%艺术数据,防止照片级生成崩溃;中段训练逐步将风格化数据提升至2.5%,增强风格表现力同时保持真实感;SFT阶段使用精选真实与合成数据,对齐人类审美偏好,实现快速收敛。
- 渐进式混合分辨率训练(256px → 512px → 512–1024px)结合桶采样与动态合成文本数据采样,提升训练稳定性与文本渲染准确性,尤其在罕见中文字符上表现优异,合成数据在最终预训练阶段逐步退出。
- GenEval、DPG-Bench与WISE评估显示,LongCat-Image在文本-图像对齐、构图推理与世界知识方面达到SOTA或具有竞争力的表现,展现出强大的语义理解与细粒度可控能力。
- GlyphDraw2、CVTG-2K、ChineseWord与Poster&SceneBench评估证实,LongCat-Image在复杂中英文文本渲染方面达到SOTA,涵盖多区域布局与长尾字符覆盖,尤其在复杂字符结构与真实场景融合方面表现卓越。
- 400个提示的人工评估(MOS)显示,LongCat-Image在所有指标上优于HunyuanImage 3.0,与Qwen-Image在对齐与合理性上持平,超越Qwen-Image与Seedream 4.0的视觉真实感,美学质量具有竞争力。
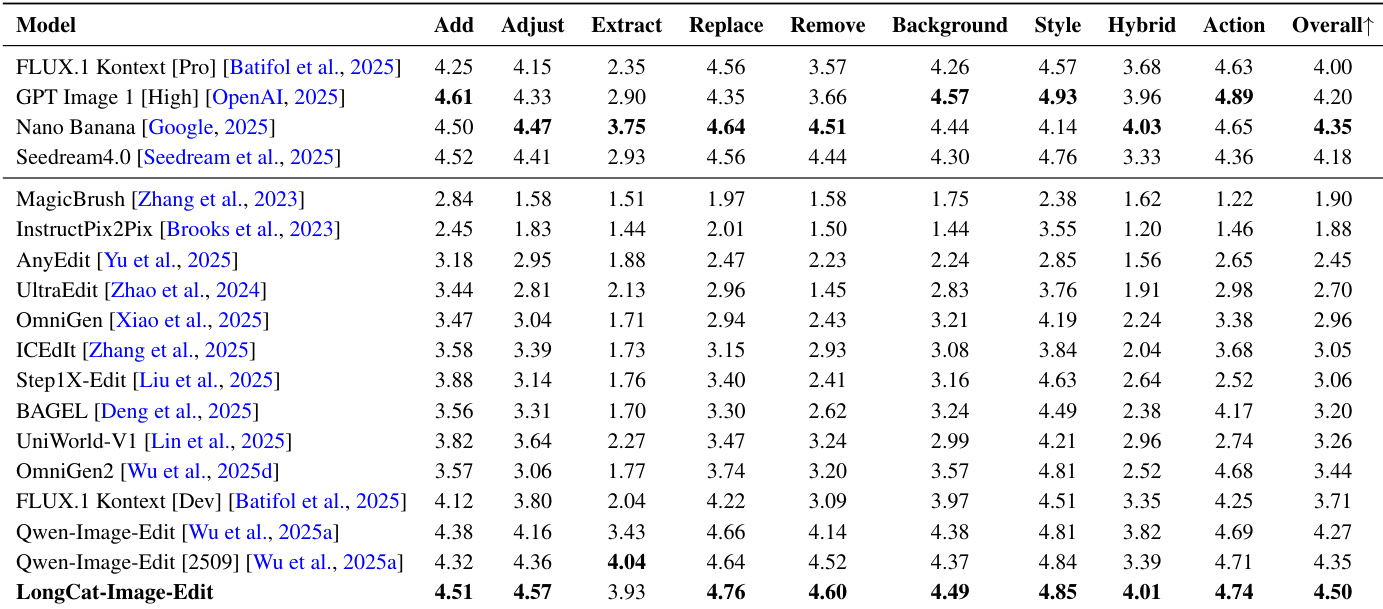
- CEdit-Bench、GEdit-Bench与ImgEdit-Bench定量评估表明,LongCat-Image在图像编辑任务中表现强劲,LongCat-Image-Edit在CEdit-Bench与GEdit-Bench上达到SOTA,且在综合质量与一致性上优于Qwen-Image-Edit与FLUX.1 Kontext [Pro]。
- 一对一人工评估(SBS)显示,LongCat-Image-Edit在综合质量与一致性上胜过Qwen-Image-Edit与FLUX.1 Kontext [Pro],但与商业模型Nano Banana和Seedream 4.0相比仍存在差距。
- 定性结果证实,LongCat-Image在多轮编辑、人像与以人为核心编辑、风格迁移、对象操作、场景文本编辑与视角变换方面表现卓越,复杂多步编辑中一致保持身份、布局与纹理。
结果表明,LongCat-Image-Edit在CEdit-Bench上取得4.50的最高综合得分,超越所有对比模型,包括FLUX.1 Kontext [Pro]与Qwen-Image-Edit等商业系统。模型在所有编辑类别中表现优异,尤其在动作、风格与混合编辑任务中显著提升一致性与综合质量。
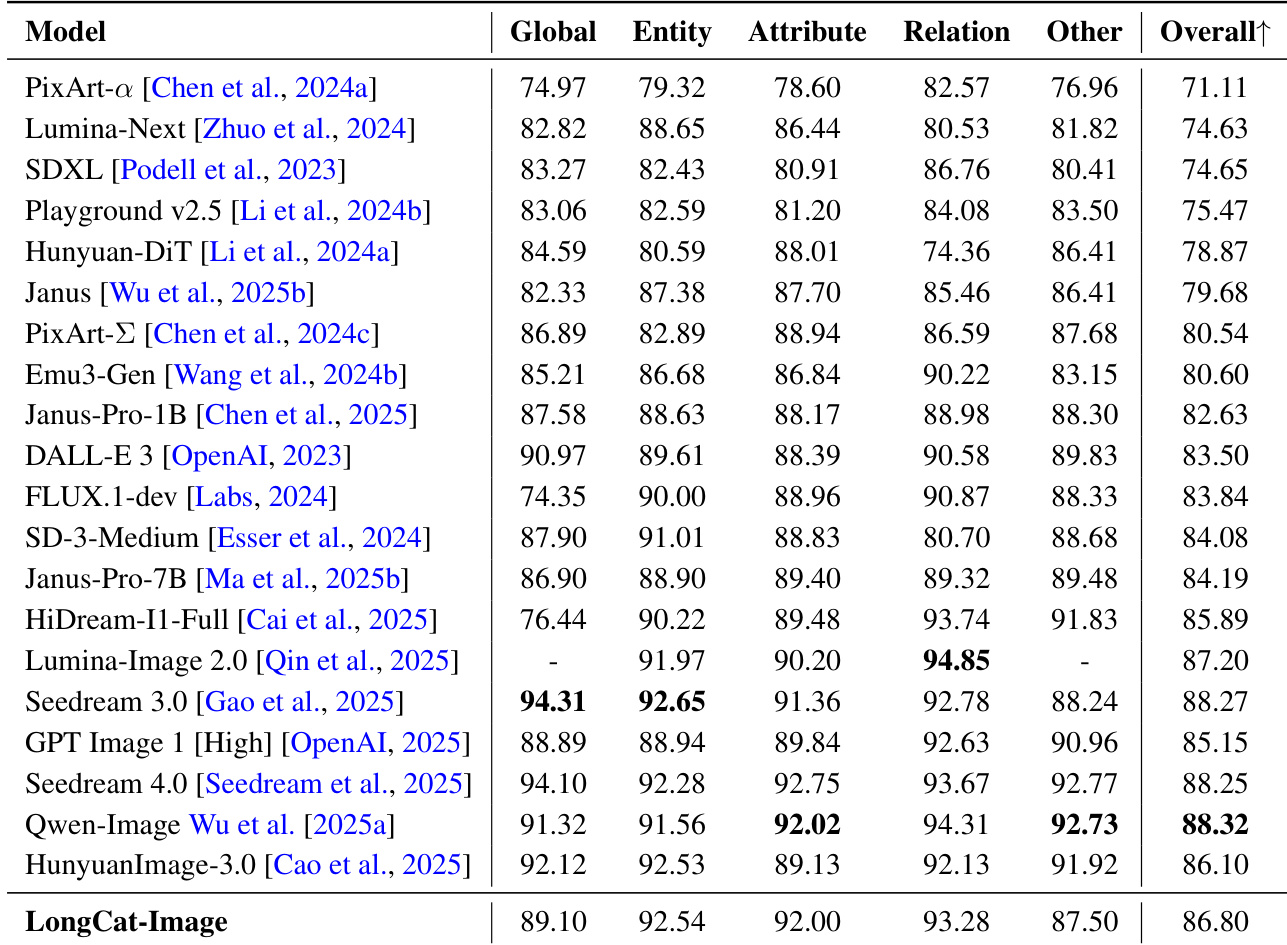
结果表明,LongCat-Image在所有评估基准上平均得分为0.95,优于HunyuanImage-3.0,接近Seedream 4.0(平均得分0.97)。模型在中英文文本渲染任务中均表现强劲,尤其在Complex-en与Poster-zh子集上得分极高,表明其在处理复杂文本内容与双语场景方面具有强大能力。

结果表明,LongCat-Image在平均词准确率上达到0.8658,优于Seedream 4.0与Qwen-Image,同时取得0.9361的NED得分与0.7859的CLIPScore,表现优异。模型在多区域文本渲染方面能力突出,尤其擅长处理复杂文本布局,但在NED上略逊于Seedream 4.0,在CLIPScore上落后于Qwen-Image。

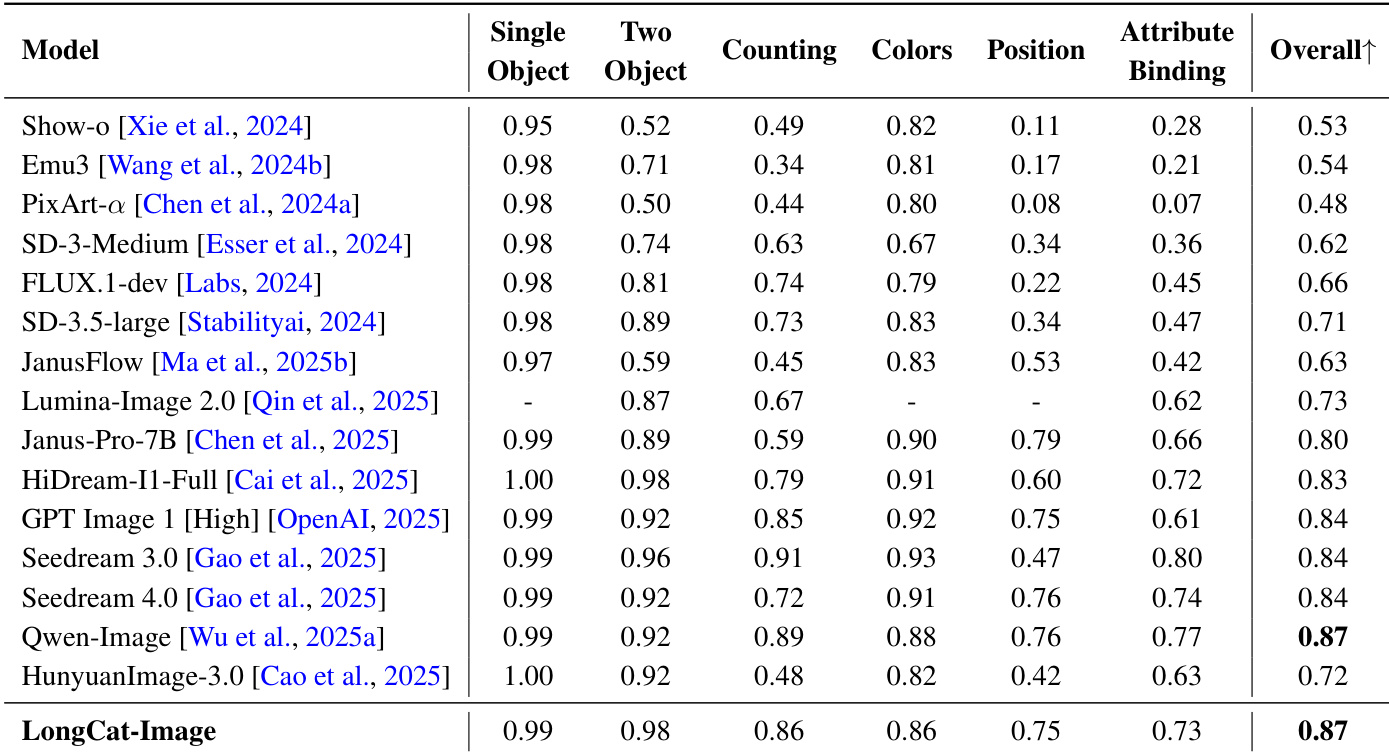
作者采用全面评估框架,从文本-图像对齐、实体识别、属性绑定与关系推理等多个维度评估LongCat-Image性能。结果表明,该模型在所有类别中表现强劲,尤其在实体与属性任务中得分突出,在整体性能上位列顶尖,展现出对复杂构图与语义约束的强大处理能力。
结果表明,LongCat-Image在GenEval基准上取得0.87的综合得分,与最佳模型Qwen-Image持平,优于所有列出的其他模型。模型在属性绑定、计数与位置理解方面能力突出,尤其在单对象与双对象任务中得分极高,表明其对构图元素具有强大的细粒度控制能力。