Command Palette
Search for a command to run...
超越真实:用于长上下文LLM的旋转位置编码的虚数扩展
超越真实:用于长上下文LLM的旋转位置编码的虚数扩展
Xiaoran Liu Yuerong Song Zhigeng Liu Zengfeng Huang Qipeng Guo Zhaoxiang Liu Shiguo Lian Ziwei He Xipeng Qiu
摘要
旋转位置编码(Rotary Position Embeddings, RoPE)通过在复数平面上对查询(query)和键(key)向量进行旋转变换,已成为大型语言模型(Large Language Models, LLMs)中编码序列顺序的标准方法。然而,现有标准实现仅使用复数点积的实部来计算注意力分数,忽略了包含重要相位信息的虚部,从而可能导致建模长程依赖关系时丢失关键的相对关系细节。本文提出一种扩展方法,重新引入此前被舍弃的虚部信息。该方法充分利用完整的复数表示,构建双成分注意力分数。我们从理论和实证两个层面证明,该方法通过保留更丰富的位置信息,显著提升了对长上下文依赖关系的建模能力。在一系列长上下文语言建模基准测试中,我们的方法在所有场景下均优于标准RoPE,且随着上下文长度的增加,性能提升愈发显著。相关代码已开源,地址为:https://github.com/OpenMOSS/rope_pp。
摘要
来自复旦大学、上海创新研究院和中国联通的研究人员提出了 RoPE++,这是一种增强型旋转位置编码方法,其在注意力计算中保留了复数值点积的虚部。通过利用完整的复数信息,RoPE++ 在长上下文建模方面优于标准 RoPE,在多种长上下文基准测试中,随着上下文长度的增加表现出持续的性能提升。
主要贡献
- 标准旋转位置编码(RoPE)在注意力得分中丢弃了复数的虚部,导致相位信息丢失,而这些信息本可用于增强对长距离依赖关系的建模;本文指出,虚部捕捉到了与实部注意力强调的局部语义不同的、互补的长距离关系模式。
- 作者提出了 RoPE++,该方法通过两种配置将虚部重新整合进注意力机制:RoPE++EH 在保持注意力头数量不变的同时将 KV 缓存使用量减半,而 RoPE++EC 在相同的缓存占用下将注意力头数量翻倍,两者均保持了 RoPE 统一的绝对-相对位置编码结构。
- 在 3.76 亿和 7.76 亿参数规模的模型上进行的评估表明,RoPE++ 在短上下文和长上下文基准测试中始终优于标准 RoPE 及其他位置编码方法,其中 RoPE++EC 在长上下文任务中取得了显著提升,验证了虚部注意力在扩展有效上下文长度中的关键作用。
引言
作者利用旋转位置编码(RoPE),这是现代大语言模型中用于编码位置信息的主流方法,通过复数乘法结合了绝对和相对位置感知能力。尽管 RoPE 被广泛使用,但它丢弃了复数值注意力得分中的虚部,仅保留实部——这一不可逆操作导致信息损失。以往工作主要通过插值、缩放或数据感知设计来改进 RoPE,却普遍忽视了这一内在的计算局限性。作者的主要贡献是 RoPE++,一种新颖的增强方法,将被丢弃的虚部重新引入作为功能性注意力头,从而在不破坏现有 RoPE 框架的前提下增强模型容量。
- RoPE++ 恢复了被忽略的虚部注意力,该部分表现出更强的长距离依赖关注能力,从而增强了长上下文建模。
- 该方法提供两种配置:RoPE++EH 在保持注意力头数量的同时将 KV 缓存使用量减半,RoPE++EC 在相同缓存占用下将注意力头数量翻倍,两者均与标准 RoPE 兼容。
- 该方法在短上下文和长上下文任务中均提升了性能,消融实验确认了虚部注意力在捕捉扩展上下文关系中的关键作用。
方法
作者利用旋转位置编码(RoPE)的复数形式设计了 RoPE++,这是一种增强型注意力机制,重新引入了此前被丢弃的注意力得分虚部。与标准 RoPE 仅保留实部不同,RoPE++ 在同一注意力层中将实部和虚部注意力得分作为独立并行的注意力头进行计算。该设计保留了 RoPE 的核心数学特性——即通过绝对位置编码表达相对位置信息的能力——同时扩展了注意力机制的表征能力。
核心创新在于对虚部的处理。作者恢复了复数注意力乘积的负虚部,该部分可表示为在应用标准 RoPE 编码前将查询向量旋转 −π/2。如框架图所示,此操作无需修改键或值的投影,仅需对查询进行旋转。虚部注意力得分与实部并行计算,使用相同的键和值矩阵,两者均被视为独立的注意力头。这使得 RoPE++ 能够捕捉互补的位置语义:实部注意力强调语义局部性并随距离衰减,而虚部注意力衰减更慢,更倾向于关注长距离依赖。
请参考框架图以直观比较实部与虚部注意力路径,包括由余弦和正弦积分函数导出的各自特征曲线。该图说明了 RoPE++ 如何重新整合虚部以增强长上下文建模、缓存效率和长度外推能力。
为集成到现有的多头注意力(MHA)或分组查询注意力(GQA)等架构中,作者提出了两种配置。在 RoPE++EC(等缓存)中,通过将原始查询向量与其 −π/2 旋转后的副本交错排列,使注意力头总数翻倍,从而在不增加 KV 缓存大小的情况下,通过一次 FlashAttention 计算完成实部和虚部注意力的计算。如 RoPE++EC 的 GQA 示意图所示,每个键同时被原始查询和旋转后的查询关注,有效将头数翻倍,同时保持缓存效率。
相比之下,RoPE++EH(等头数)通过将查询、键和值的投影数量减半来保持原始注意力头数量不变。尽管仍计算旋转后的查询,但总头数保持不变,从而减少了参数量和 KV 缓存占用。如 RoPE++EH 的 GQA 示意图所示,该配置将键值对数量减半,但仍为每个查询计算实部和虚部注意力,从而在长上下文场景中提高吞吐量。
重要的是,作者强调实部和虚部注意力必须共享相同的查询投影矩阵。若为两个分量分配独立的头子集,会导致架构退化为标准 RoPE,因为在虚部路径中将查询旋转 π/2 会恢复实部注意力。因此,RoPE++ 被定义为一种联合操作:虚部注意力不是一个独立模块,而是相对于实部注意力的变换,两者必须共同计算才能实现增强表征的全部优势。
实验
- 在 7.76 亿和 3.76 亿参数规模的模型上使用 DCLM-Baseline-1.0 语料库(500 亿训练 token)评估 RoPE++
- 在 4k、8k、16k 和 32k 上下文长度上,将 RoPE++ 与标准 RoPE、FoPE 和 vanilla attention 进行比较
- 在 LAMBADA、WikiText 和 OpenBookQA 上测试 2k、4k、8k、16k 和 32k 上下文窗口
- 在 3.76 亿参数模型上,RoPE++ 在 RULER-4k 上取得 42.2 的最佳平均分,在 BABILong 上取得 41.8
- RoPE++EC 在长上下文任务中比 ALiBi、NoPE 和 YaRN 高出 33.9–44.1 分
- 在 3.76 亿参数模型上,RoPE++ 在短上下文任务中得分为 44.3,长上下文任务中为 52.6,超越先前方法 18.6–27.2 分
作者使用 RoPE++ 的 EH 和 EC 两种变体来改进 Transformer 模型中的位置编码,并在短上下文基准上与标准 RoPE 及其他设计进行比较。结果表明,RoPE++EC 在 3.76 亿和 7.76 亿参数模型上均持续取得最高的平均得分,优于 RoPE、FoPE、Pythia 和 ALiBi 等所有基线方法。RoPE++EH 的表现也具有竞争力,尽管 KV 缓存和 QKV 参数减少一半,仍能达到或超过 RoPE 的性能。
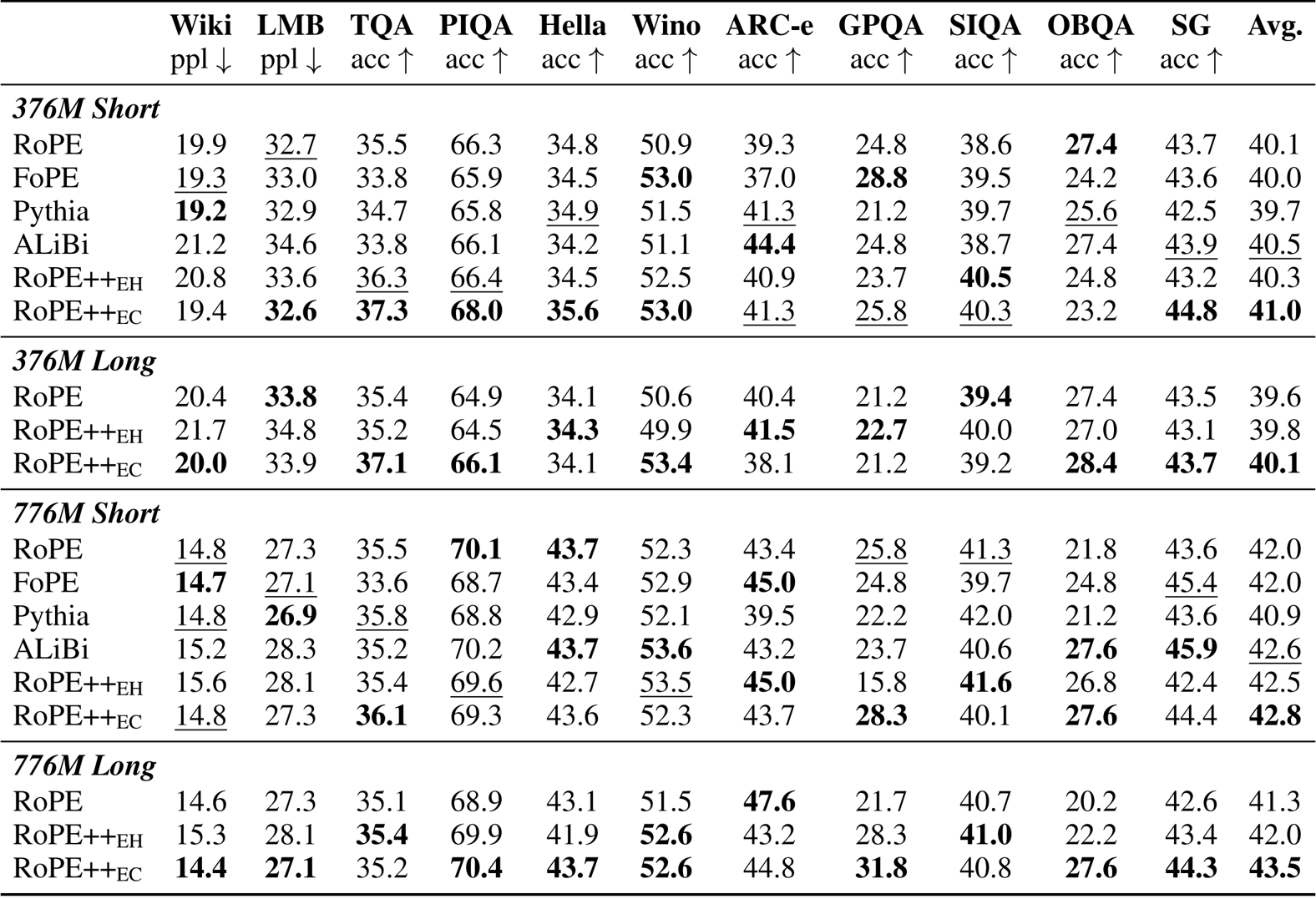
结果表明,RoPE++ 在 RULER 和 BABILong 等长上下文基准测试中,无论在 3.76 亿还是 7.76 亿参数模型上,均持续优于标准 RoPE,取得最高的平均得分,并在 64k 上下文长度下保持更强的性能。RoPE++EC 在相同 KV 缓存大小下实现了最佳的整体增益,而 RoPE++EH 在使用一半缓存和 QKV 参数的情况下仍能达到或超过 RoPE 的性能。
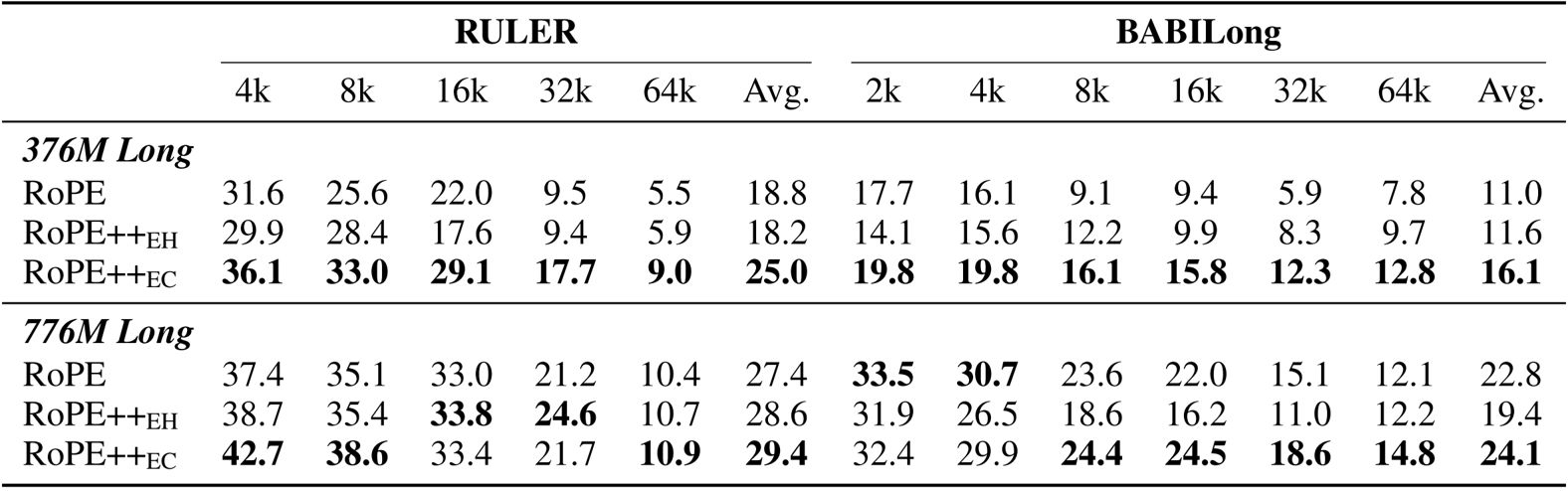
作者在使用线性 PI 和 YaRN 缩放进行长上下文预训练后评估 RoPE++ 变体,结果显示 RoPE++EC 在 RULER 和 BABILong 等短上下文和长上下文基准测试中持续取得最高的平均得分。RoPE++EH 在使用一半 KV 缓存的情况下仍能达到或超过标准 RoPE 的性能,而 RoPE++EC 在相同缓存大小下进一步提升了性能,尤其在更长的上下文长度下表现更优。结果证实 RoPE++ 同时提升了效率和准确性,且随着上下文长度增加,性能优势进一步扩大。
