Command Palette
Search for a command to run...
基于时序推理的统一视频编辑
基于时序推理的统一视频编辑
Xiangpeng Yang Ji Xie Yiyuan Yang Yan Huang Min Xu Qiang Wu
摘要
现有的视频编辑方法面临一个关键的权衡:专家级模型虽能提供高精度,但依赖于任务特定的先验信息(如掩码),难以实现统一;而统一的时序上下文学习模型虽无需掩码,却缺乏显式的空间线索,导致指令到区域的映射能力较弱,定位精度不足。为解决这一矛盾,我们提出 VideoCoF——一种受思维链(Chain-of-Thought)推理启发的新型“帧链”(Chain-of-Frames)方法。VideoCoF 通过强制视频扩散模型遵循“先观察、再推理、后编辑”的流程,要求模型在生成目标视频帧之前,首先预测推理标记(即编辑区域的潜在表示)。这一显式的推理步骤在无需用户提供掩码的前提下,实现了精准的指令到区域对齐,支持细粒度的视频编辑。此外,我们引入了一种 RoPE 对齐策略,利用这些推理标记来保证运动的一致性,并支持超出训练时长的长度外推。实验表明,仅需 5 万对视频数据的极小数据成本,VideoCoF 即可在 VideoCoF-Bench 基准上达到当前最优性能,充分验证了该方法的高效性与有效性。相关代码、模型权重及数据已开源,地址为:https://github.com/knightyxp/VideoCoF。
视频编辑摘要
来自悉尼科技大学和浙江大学的研究人员提出了 VideoCoF,这是一种“帧链”(Chain-of-Frames)方法,通过引入推理标记(reasoning tokens),实现无需掩码、精确的指令到区域的视频编辑。通过模仿“思维链”(Chain-of-Thought)的推理过程,VideoCoF 在极少训练数据的情况下,在 VideoCoF-Bench 基准上实现了细粒度的空间控制和运动一致性,超越了以往模型。
主要贡献
- 提出了一种新颖的“帧链”方法,通过利用时间推理实现细粒度视频编辑,在基准数据集上达到了最先进的性能。
- 提出统一模型 VideoCoF,沿时间维度将源标记与加噪的编辑标记融合,确保运动一致性以及精确的指令到区域对齐。
- 在标准基准测试中表现出色,指令遵循准确率比基线方法高出 +15.14%,且无需用户提供的掩码即可实现有效的视频编辑。
引言
作者利用视频扩散模型的进展,解决现有视频编辑方法中的一个关键局限——空间控制不精确和指令遵循能力差——提出了一种统一的、基于推理的框架。当前的方法可分为两类:一类是专家模型,使用适配器模块和外部掩码实现精确编辑,但需要针对每项任务进行额外配置;另一类是统一的上下文学习模型,支持无掩码编辑,但由于缺乏显式的区域提示,空间准确性较弱。核心挑战在于如何在高编辑精度与无掩码、统一编辑的灵活性之间取得平衡。
为解决这一权衡问题,作者提出了 VideoCoF,一种“帧链”框架,通过在生成编辑视频之前预测推理标记(即编辑区域的潜在表示),将时间推理嵌入视频扩散模型中。这强制执行了受“思维链”提示启发的“观察 → 推理 → 编辑”工作流,从而在无需用户提供掩码的情况下实现准确的指令到区域对齐。
主要创新包括:
- “帧链”机制将编辑区域预测显式建模为推理步骤,提升了统一视频编辑中的定位准确性。
- 软灰度推理格式,在潜在空间中有效表示空间编辑区域,增强指令遵循能力。
- RoPE 对齐策略,重置时间位置索引以保持运动一致性并支持长度外推,使模型能够在比训练时长达 4 倍的视频上进行推理。
数据集
- 作者使用一个包含 5 万对视频的统一数据集进行训练,该数据集在四个核心编辑任务上精心平衡:对象添加(1 万)、对象移除(1.5 万)、对象替换(1.5 万)和局部风格迁移(1 万)。
- 数据集结合了来自 Señorita 2M 的过滤开源视频与合成生成的编辑内容,确保了多样性和实例级别的复杂性。
- 对于对象添加和移除任务,作者在 Señorita 视频上应用 MiniMax-Remover 生成配对数据,原始视频作为源,编辑后版本作为目标(或反之);移除数据集中包含 5 千个多实例样本以增强鲁棒性。
- 对象替换和局部风格迁移样本使用 VACE-14B 在修复模式下生成,由 Grounding DINO 提供的精确掩码和 GPT-4o 生成的创意提示引导,确保编辑的多样性和高质量。
- 所有生成的视频对均经过严格筛选,使用 Dover Score(美学质量)和 VIE Score(编辑保真度)进行过滤,最终得到一个精炼的高质量子集用于训练。
- 最终训练数据与评估集无重叠,确保对泛化能力的干净评估。
- 作者引入了 VideoCoF-Bench,这是一个包含来自 Pexels 的 200 个视频以及从 EditVerse 和 UNIC-Bench 改编的样本的新基准,与训练数据无重叠。
- VideoCoF-Bench 覆盖相同的四个编辑任务(每项任务 50 个样本),其中一半为实例级别,需要细粒度推理和指令遵循。
- 为确保公平比较,UNIC-Bench 样本经过修改,移除了参考身份图像,将评估标准化为纯文本驱动编辑。
- 模型在 5 万对经过筛选和合成的视频对上训练,各任务样本数量相等,以发展强大的指令遵循和实例级编辑能力。
方法
作者基于 VideoDiT 主干构建了一个名为 VideoCoF 的统一视频编辑框架,通过“先推理后生成”的结构化流程实现指令驱动的视频编辑。核心创新在于“帧链”(Chain of Frames, CoF)范式,它将编辑任务显式分解为三个连续阶段:观察源视频、推理编辑区域、生成编辑内容。该设计解决了以往上下文编辑方法的局限——这些方法简单地将源和目标标记拼接,缺乏显式空间定位,常导致编辑错位。
参考框架图,源视频、推理和目标视频标记分别通过视频 VAE 编码,然后在时间维度上拼接成单一序列。模型使用自注意力进行上下文学习,交叉注意力进行语言条件控制,端到端处理该统一序列。推理标记由视觉上突出编辑区域的灰度掩码生成,插入在源和目标标记之间。这迫使模型在生成修改内容前先预测编辑的空间位置,模拟“观察、推理、再编辑”的认知过程。
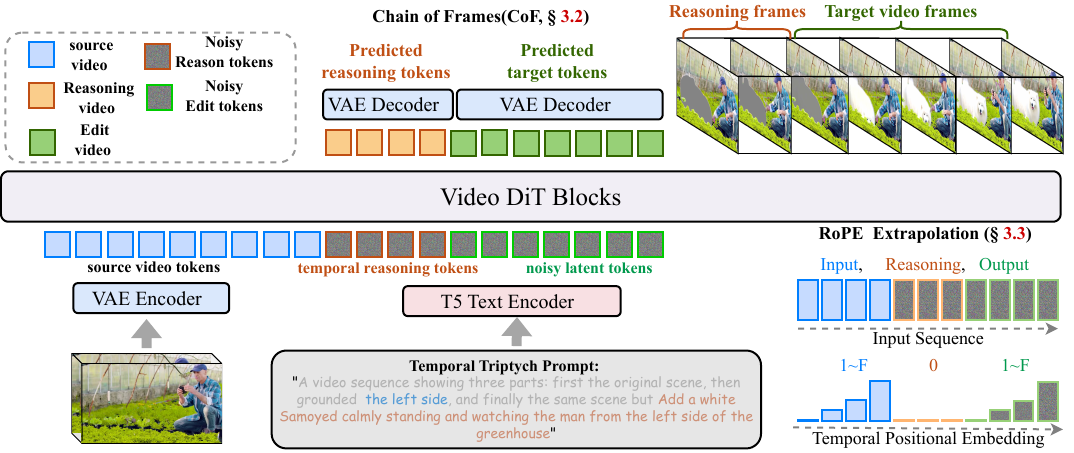
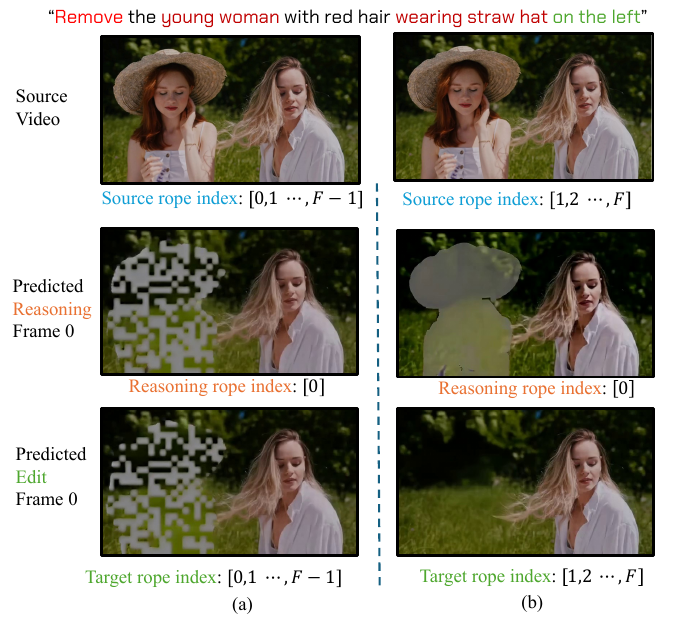
为支持可变长度推理并避免对固定时间映射的过拟合,作者重新设计了位置编码。不同于在整个拼接序列上分配连续索引,他们为源视频和目标视频分别分配时间 RoPE 索引 [1,F],而推理帧独占索引 0。这防止了索引冲突,避免视觉伪影从推理标记传播到目标帧。如下图所示,这种隔离在去噪过程中确保了角色的清晰分离,同时保留了模型对任意长度视频的泛化能力。
训练过程中,将推理帧和目标帧视为生成目标。给定源、推理和目标潜变量三元组,记为 zs(0)、zr(0) 和 ze(0),模型接收部分加噪输入 z(t)=zs(0)∥zr,e(t),其中仅推理和目标部分根据 t∈[0,1] 逐步加噪。模型预测速度场 v=ε−zfull(0),训练目标是最小化推理和目标帧上的均方误差:
L=L+F1i=F∑2F+L−1vi−[Fθ(z(t),t,c)]i22在推理阶段,源潜变量保持固定,而推理和目标块从噪声初始化,并通过 ODE 求解器演化至干净状态。最终编辑视频从去噪潜变量序列的目标段解码得到。
为弥合文本到视频生成与基于指令编辑之间的差距,作者引入了一种时间三联提示模板:“一段视频序列包含三个部分:首先是原始场景,然后是定位的 {ground instruction},最后是同一场景但 {edit instruction}。” 这种结构化提示将编辑意图嵌入视频的时间流中,使模型无需昂贵的指令微调即可理解指令。如提示对比图所示,与直接指令格式相比,该方法显著提升了编辑准确性。

实验
- 在 WAN-14B 上使用 5 万对视频编辑数据训练,指令遵循和成功率表现优异
- 使用跨四种宽高比的分辨率分桶策略,实现 86.27% 的指令遵循准确率和 25.49% 的成功率
- 在成功率上比 ICVE 和 InstructX 等基线方法高出 1.52–7.39%,在保留得分上高出 26.54–29.60%
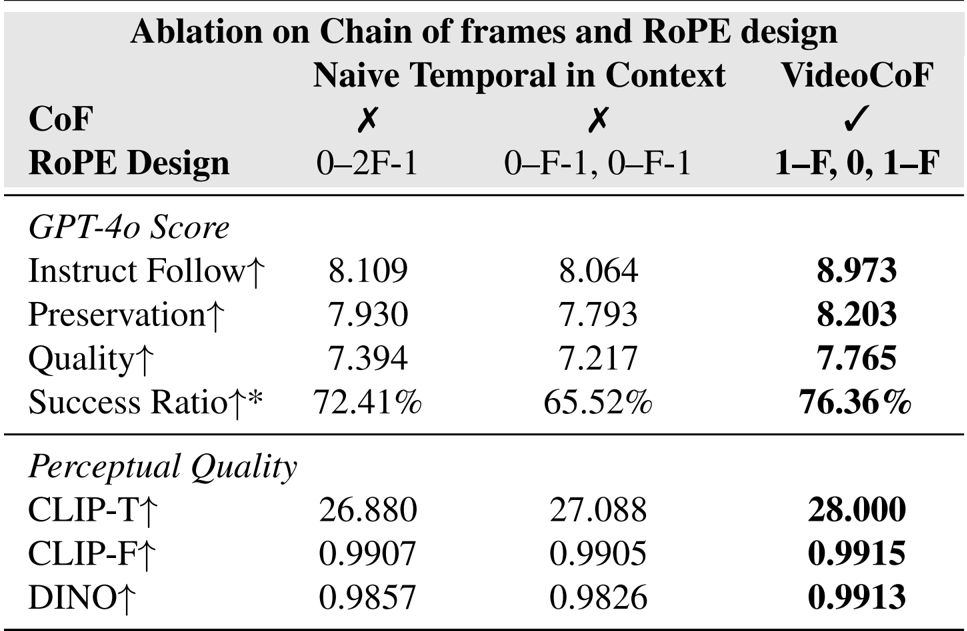
- 通过消融实验验证了“帧链”(CoF)设计中推理帧和 RoPE 对齐的有效性
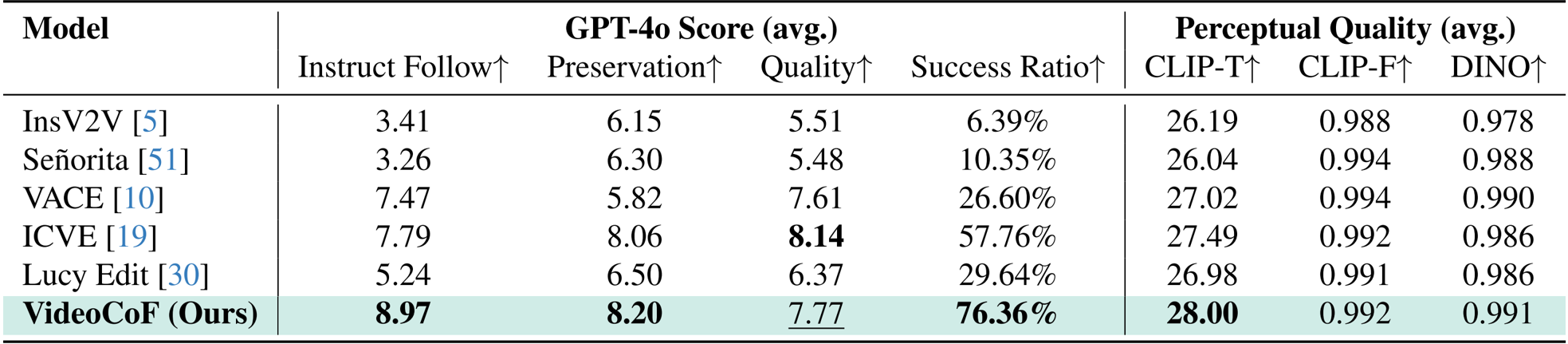
VideoCoF 在所有对比模型中取得了最高的平均指令遵循得分(8.97)和成功率(76.36%),表明其在执行编辑指令方面具有卓越的精度。尽管 ICVE 在视觉质量上领先(8.14),但 VideoCoF 在保留性(8.20)和感知对齐(CLIP-T: 28.00)方面表现更优,表明其对指令和原始内容的保真度更高。该模型仅使用 5 万训练对即达到此性能,凸显了其相对于大规模基线的数据效率。
作者通过消融实验将 VideoCoF 与朴素的时间上下文基线进行比较,结果显示引入推理帧及其 RoPE 对齐设计使指令遵循率提升 10.65%,成功率提升 5.46%。结果还表明,VideoCoF 在 CLIP-T、CLIP-F 和 DINO 得分上也更高,证实了其在文本对齐和时空结构保留方面的优势。RoPE 设计支持长度外推而不导致质量下降,而固定时间映射方法则无法做到这一点。
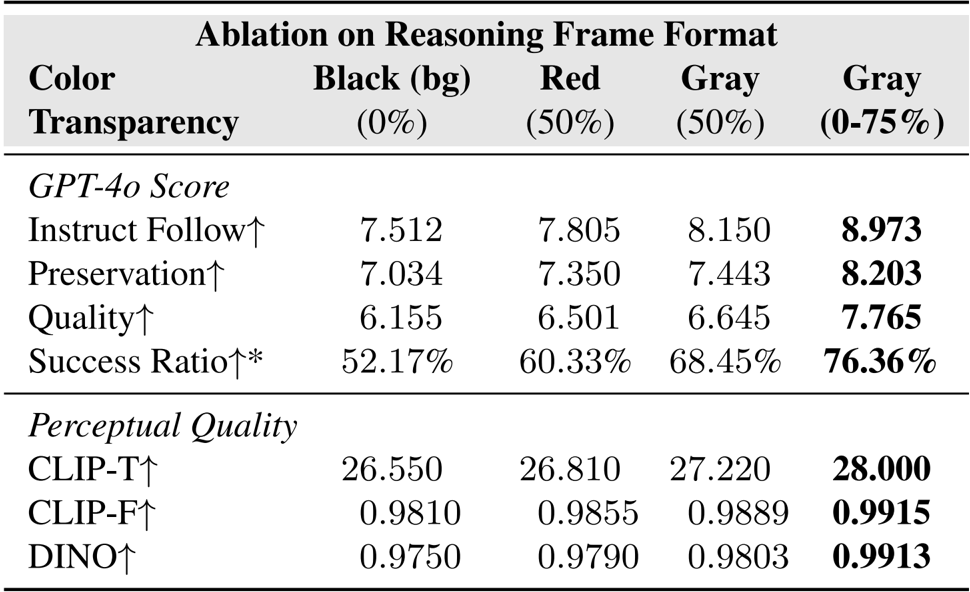
作者测试了不同的推理帧格式,发现从 0% 到 75% 透明度渐变的灰度掩码在所有指标(包括指令遵循、成功率和感知质量)上得分最高。该格式优于静态黑色、红色或均匀灰色掩码,证实了渐进透明度能在不破坏时间一致性的情况下增强空间引导。结果在语义对齐(CLIP-T)和结构一致性(DINO)上均表现出稳定提升,验证了该设计在精确视频编辑中的有效性。