Command Palette
Search for a command to run...
原生并行推理器:通过自蒸馏强化学习实现并行推理
原生并行推理器:通过自蒸馏强化学习实现并行推理
Tong Wu Yang Liu Jun Bai Zixia Jia Shuyi Zhang Ziyong Lin Yanting Wang Song-Chun Zhu Zilong Zheng
摘要
我们提出原生并行推理器(Native Parallel Reasoner, NPR),这是一种无需教师指导的框架,使大型语言模型(LLMs)能够自主演化出真正的并行推理能力。NPR通过三项关键技术革新,将模型从传统的顺序模拟模式转变为原生的并行认知模式:1)一种自蒸馏的渐进式训练范式,无需外部监督,即可实现从“冷启动”式格式发现到严格拓扑约束的平稳过渡;2)一种新型的并行感知策略优化(Parallel-Aware Policy Optimization, PAPO)算法,能够在执行图内部直接优化分支策略,使模型通过试错学习自适应的任务分解能力;3)一个稳健的NPR引擎,重构了SGLang的内存管理与流程控制机制,从而支持稳定、大规模的并行强化学习训练。在八项推理基准测试中,基于Qwen3-4B模型训练的NPR实现了最高达24.5%的性能提升,推理速度最高提升4.6倍。与以往基线方法常退化为自回归解码不同,NPR展现出100%的真正并行执行能力,为自主演化、高效且可扩展的智能体推理树立了全新标准。
摘要
来自北京通用人工智能研究院(BIGAI)NLCo实验室的研究人员提出了一种无需教师模型的框架——原生并行推理器(Native Parallel Reasoner, NPR),该框架通过自蒸馏训练、并行感知策略优化(PAPO)以及增强的NPR引擎,使大语言模型(LLM)能够自我演化出真正的并行推理能力,在推理任务上实现了最高24.5%的性能提升和4.6倍的加速,且并行执行率为100%。
主要贡献
- 提出一种自蒸馏的渐进式训练范式,从冷启动格式发现过渡到原生并行性,使模型能够通过试错学习自适应的分解策略,而无需依赖外部监督。
- 提出一种新颖的并行感知策略优化算法,利用拒绝采样来优化推理路径,通过消除奖励博弈行为并提升多种轨迹下的执行效率,优于先前方法。
- 在八个推理基准上全面评估,验证了100%真正并行性的实现,结合人类反馈数据的监督学习,达到当前最优性能。
引言
作者提出一种名为原生并行推理器(NPR)的新框架,使大语言模型能够在无需外部监督的情况下自我演化出并行推理能力。这一进展解决了以往工作的局限性——这些工作通常依赖人工设计的并行结构,或需要从更强模型中进行有监督的蒸馏,从而限制了真正并行智能的涌现。
技术与应用场景的重要性在于,现实世界中的复杂问题求解需要模型能够同时探索多条推理路径。该领域先前的工作通常采用顺序推理,即模型被提示按步骤解决问题。相比之下,NPR通过训练模型原生生成有效的并行推理路径,将并行性内化,使其能够通过试错学习自适应的分解策略。
作者的主要贡献是一种三阶段渐进式训练范式,使模型从顺序模拟逐步过渡到真正的并行认知。该方法实现了无冲突的并行 rollout,并直接在并行执行图中优化分支策略。
关键创新与优势包括:
- 一种统一的自蒸馏数据构建框架,无需依赖外部监督
- 使用新型并行感知策略优化(PAPO)算法实现无冲突的并行 rollout
- 任务无关的并行性,在多种基准上实现100%真正并行推理,无任何伪并行行为
数据集
- 作者使用包含57k个问题-答案对的ORZ数据集作为实验基础,从中采样固定的8k个样本用于所有训练阶段。
- 该8k样本子集在流程的第1、第2和第3阶段中保持一致,确保训练过程的统一性。
- 数据集源自ORZ,所用模型基于Qwen3-4B-Instruct和Qwen3-7B,训练过程中未作任何修改。
- 训练时使用Qwen3-4B-Instruct-2507和Qwen3-4B,避免使用“思考模式”变体,因其与标准监督微调不兼容。
- 在第1阶段,作者采用DAPO设置,最大生成长度为30,000个token。
- 第2阶段起始学习率为1e-6,衰减至5e-7,并应用0.1的权重衰减。
- 在第3阶段,作者使用PAPO结合NPR引擎,保持最大生成长度为30,000个token,并将学习率设为1e-7。
方法
作者采用三阶段课程式训练,逐步诱导、巩固并放大语言模型原生并行推理(NPR)的能力,使其能够并发生成和评估多条推理分支。如图所示,整体框架从一个基础指令微调模型开始,最终演化为一个完全优化的并行推理器,能够在无外部教师模型的情况下进行结构化并行推理。
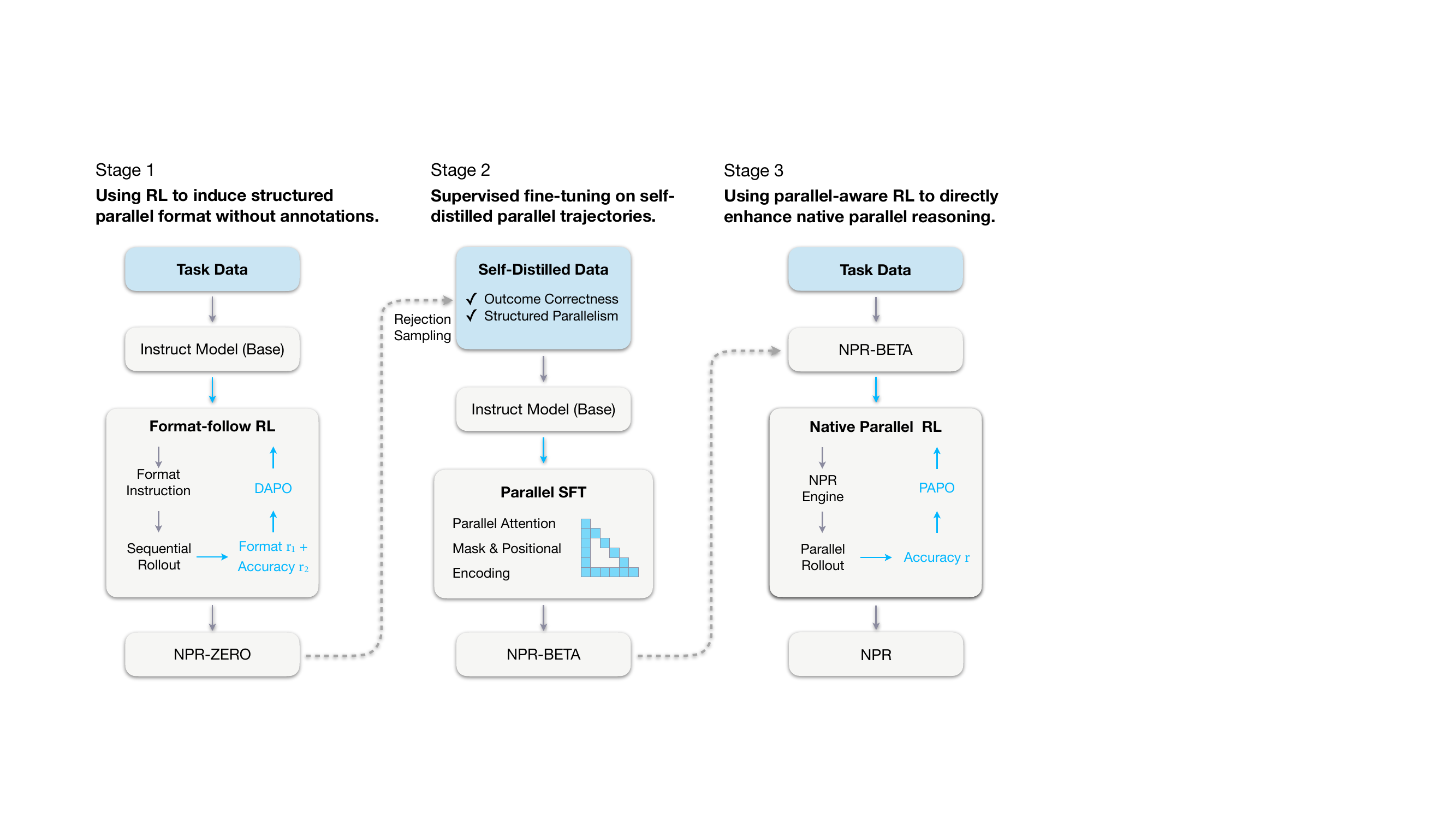
在第1阶段,作者使用强化学习(无配对监督)诱导出结构化并行生成格式。采用简化的“映射–处理–归约”(Map–Process–Reduce)模式,每个并行块均用显式标签封装:<guideline>用于规划,<step>用于独立子任务执行,<takeaway>用于最终聚合。模型通过DAPO训练,奖励函数结合格式合规性(有效为0.0,无效则惩罚)和答案准确性(正确+1.0,错误-1.0)。由此得到NPR-Zero检查点,作为自蒸馏训练数据的生成器。
第2阶段在自蒸馏数据集上进行监督微调(SFT),该数据集通过拒绝采样构建:仅保留结果正确且结构格式合规的轨迹。为实现并行生成,作者引入Multiverse风格的并行注意力掩码和位置编码,允许多条推理路径在单次前向传播中共存,同时实现高效的KV缓存复用。模型在该精选数据集上通过标准负对数似然进行训练,得到NPR-Beta,作为最终强化学习阶段的稳定初始化。
第3阶段引入原生并行强化学习(Native Parallel RL),使用一种称为并行感知策略优化(PAPO)的改进策略目标,直接优化模型的并行推理能力。为确保结构保真度,rollout通过NPR-Engine生成——这是一个强化的推理引擎,强制执行严格的并行语义,防止生成非法轨迹。训练期间,使用SFT构建的注意力掩码和位置ID进行模式级过滤,从而无需格式奖励,将奖励信号简化为仅准确性。作者将组级优势归一化替换为批级归一化以稳定训练,并保留控制并行分支的特殊token的梯度,以维持结构完整性。关键的是,作者摒弃了重要性采样,采用严格的在策略目标,用停梯度分数替代截断概率比,避免不稳定的重加权。最终的PAPO目标为:
J(θ)=E(q,y)∼D,{y^i}i=1G∼πθ(⋅∣q)−∑i=1G∣y^i∣1i=1∑Gt=1∑∣y^i∣sg[πθ(y^i,t∣q,y^i,<t)]πθ(y^i,t∣q,y^i,<t)A^i,t.如下图所示,该方法与GRPO风格的强化学习不同,采用批归一化替代组归一化,摒弃参考模型和KL惩罚,并通过推理引擎和结构过滤强制执行并行结构。
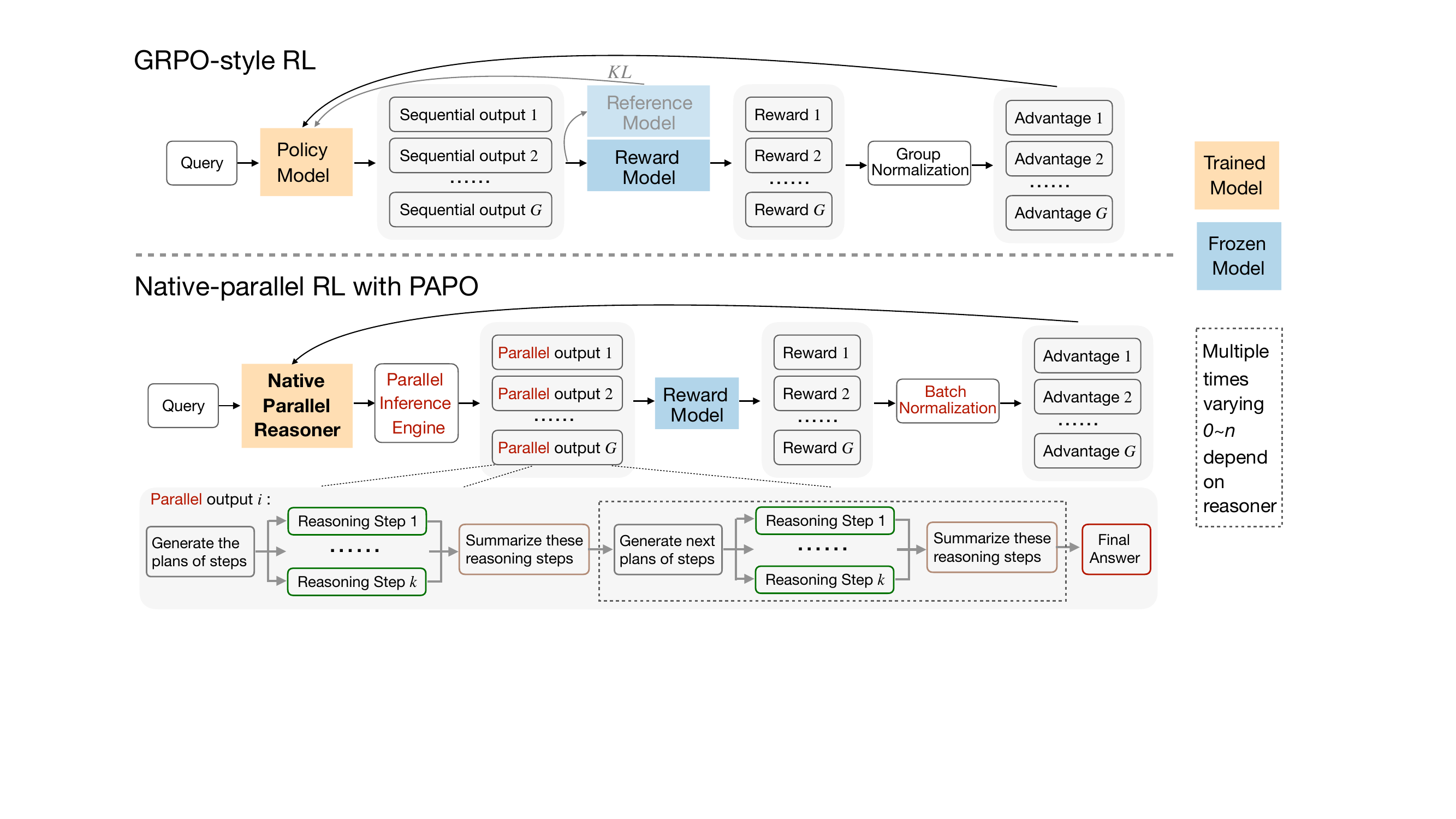
NPR-Engine是实现稳定并行 rollout 的关键组件,解决了多项工程挑战,包括KV缓存双重释放、token预算低估、非法模式导致的未定义状态,以及step块内的局部重复。这些修复确保了在高吞吐量并行解码下的确定性行为、内存安全和正确的长度统计,使大规模强化学习成为可能。最终的NPR模型在AIME25等基准上表现出真正的并行性、token加速和优于自回归基线的推理准确性。
实验
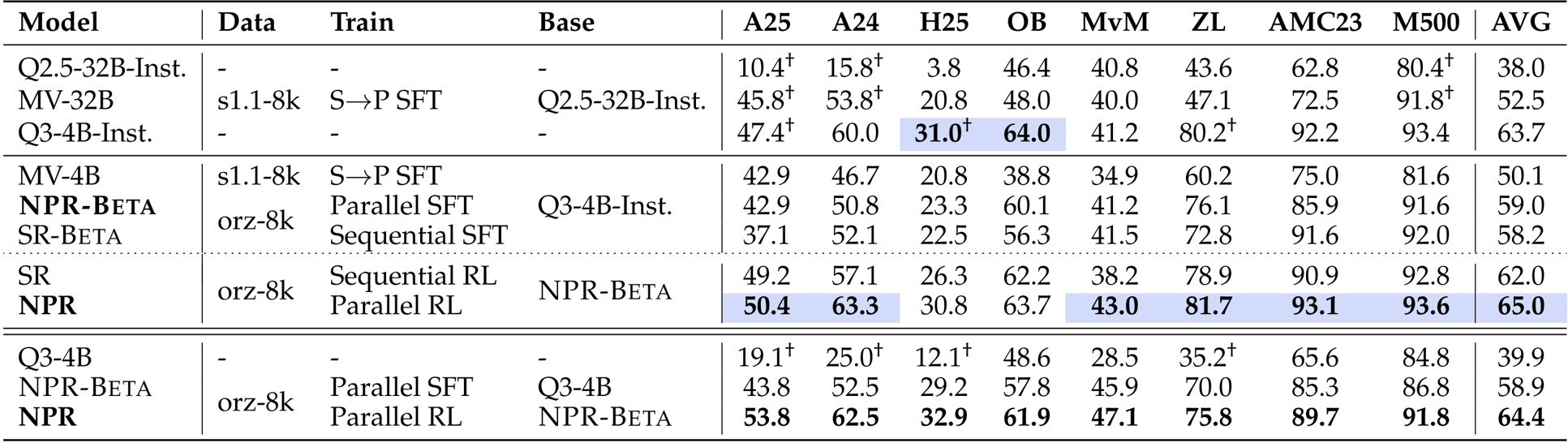
- 在八个推理基准上评估NPR,结果一致优于Multiverse、自回归训练和直接强化学习基线
- 在AIME25上达到76.7%的准确率,超过Multiverse-32B(72.8%)和Qwen3-4B-Instruct(60.1%)
- 由于原生并行推理架构,展现出强大的测试时可扩展性和推理加速能力
- 通过干净的模板设计和自蒸馏并行SFT,消除了伪并行行为
- 案例研究显示模型具备自适应并行性,能根据问题难度调整分支深度
- NPR通过支持多样化子问题探索和轻量级一致性检查实现鲁棒验证,优于顺序模型
作者使用自蒸馏数据集和并行训练方法开发NPR,在多个推理基准上持续优于Multiverse和顺序变体等基线。结果表明,用并行SFT和强化学习替代顺序训练可带来显著提升,NPR在所有评估数据集上平均得分最高(65.0),并行推理触发率达到100%。在更难的任务上提升尤为明显,表明并行探索和验证机制同时提升了准确性和推理效率。
作者通过比较SR、Multiverse和NPR-Inst三种方法的token吞吐量和加速比来评估推理效率。结果显示,NPR-Inst在所有五个基准上均实现最高的TPS和加速比,相比SR提升2.9倍至4.6倍,且始终优于Multiverse。加速比随任务难度增加而提升,表明当问题需要更深的并行探索时,NPR-Inst效率更高。

作者使用并行推理触发率来衡量模型在不同数据集上采用并行推理的一致性。结果显示,NPR-Inst在全部八个基准上均达到100.0%的触发率,而MV-32B表现出高度波动的触发率,表明NPR的训练流程已将并行推理制度化为默认模式,不受任务领域影响。

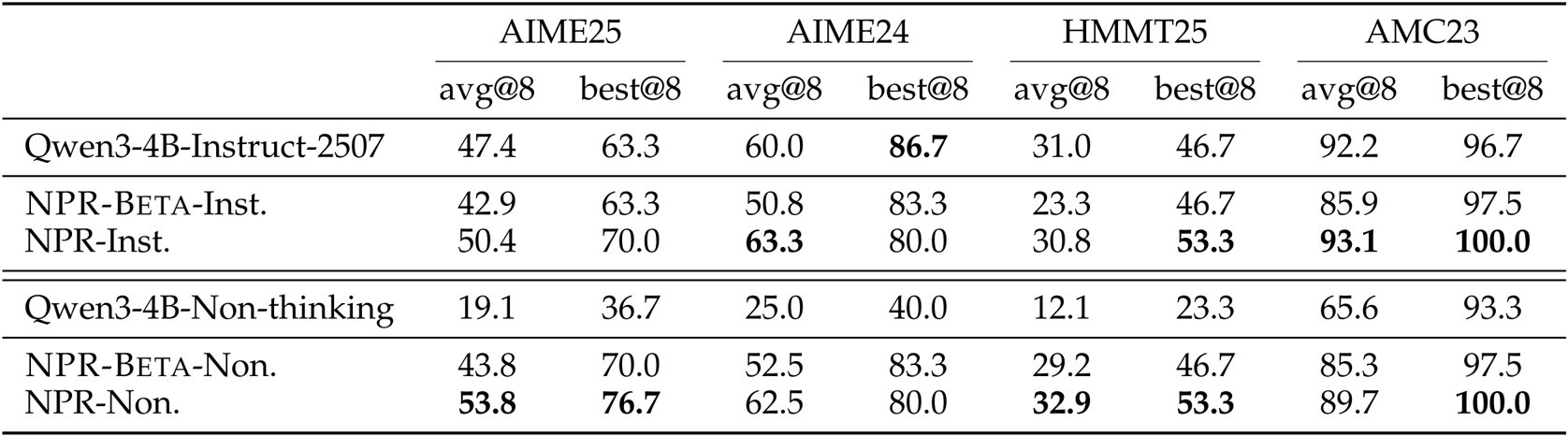
作者在四个数学基准上使用avg@8和best@8指标将NPR与Qwen3-4B基线进行比较,结果显示NPR在所有数据集上均持续提升平均和最佳性能。NPR-Inst.和NPR-Non.均优于各自基线,其中best@8得分提升最大,表明更强的测试时可扩展性和oracle覆盖能力。这些结果证实,NPR的并行训练流程相比顺序或非思考模型,提升了解的多样性和鲁棒性。