Command Palette
Search for a command to run...
零样本跨模态视频生成
零样本跨模态视频生成
摘要
参考图像到视频(Reference-to-Video, R2V)生成旨在根据文本提示合成与之对齐的视频,同时保持参考图像中主体的身份一致性。然而,当前的R2V方法受限于对显式参考图像-视频-文本三元组的依赖,而这类数据的构建成本极高,难以实现规模化。为突破这一瓶颈,我们提出Saber,一种可扩展的零样本框架,无需任何显式的R2V训练数据。Saber仅基于视频-文本对进行训练,采用掩码训练策略与专为身份一致性与参考感知设计的注意力机制模型结构,以学习具有身份一致性和参考感知能力的表征。此外,通过引入掩码增强技术,Saber有效缓解了参考图像到视频生成中常见的“复制粘贴”伪影问题。实验表明,Saber在不同数量参考图像的场景下均展现出卓越的泛化能力,并在OpenS2V-Eval基准测试中显著优于依赖R2V数据训练的方法。
视频摘要生成
来自 Meta AI 和伦敦国王学院的研究人员提出了 Saber,这是一种零样本的参考图像到视频生成框架,无需依赖昂贵的手动构建的参考图像-视频-文本三元组数据。Saber 仅在视频-文本对上进行训练,通过掩码训练、基于注意力的建模和掩码增强技术,在 OpenS2V-Eval 上实现了强大的身份保持能力,并超越了现有方法。
主要贡献
- Saber 提出了一种零样本的参考图像到视频生成框架,仅使用视频-文本对进行训练,从而消除了对昂贵且需人工构建的参考图像-视频-文本三元组数据集的需求。
- 该方法提出了一种结合注意力建模与掩码增强的掩码训练策略,使模型能够学习到身份一致且参考感知的表示,同时减少复制粘贴伪影。
- Saber 在 OpenS2V-Eval 基准上达到了最先进的性能,优于在显式 R2V 数据上训练的模型,并在不同数量的参考图像和多样化的主体类别上展现出强大的泛化能力。
引言
参考图像到视频(R2V)生成旨在生成与文本提示对齐的视频,同时保留参考图像中主体的身份和外观,支持定制化叙事和虚拟头像等个性化应用。以往的方法依赖于昂贵且需手动构建的图像-视频-文本三元组数据集,这限制了可扩展性和多样性,导致在未见主体上的泛化能力较差。作者提出了一种名为 Saber 的零样本框架,仅通过大规模视频-文本对进行训练,利用掩码训练策略模拟参考条件,从而无需此类专用数据。
主要创新包括:
- 一种掩码帧训练方法,随机采样并掩码视频帧作为合成参考图像,实现无需精心构建 R2V 数据集的高效、可扩展学习
- 一种带有注意力掩码的引导注意力机制,增强对参考感知特征的关注,抑制背景干扰
- 空间掩码增强技术,在提升生成视频视觉保真度的同时减少复制粘贴伪影,并支持灵活的多参考输入
数据集
- 作者使用从 ShutterStock Video 数据集构建的视频-文本对,其中所有视频片段的字幕均由 Qwen2.5-VL-Instruct 生成。
- 训练数据仅由这些合成的视频-文本对组成,通过掩码训练可同时利用文本到视频和图像到视频的数据源。
- 未使用其他额外数据集;所有训练数据均来自 ShutterStock Video,并配有自动生成的字幕。
- 模型基于 Wan2.1-14B 在该视频-文本数据上进行微调,采用带有概率性掩码采样的掩码训练策略。
- 在生成掩码时,前景区域比例 r 的采样方式为:10% 的时间从 [0,0.1](极小参考)中采样,80% 从 [0.1,0.5](典型主体)中采样,10% 从 [0.5,1.0](大尺寸或背景参考)中采样。
- 掩码增强包括随机旋转(±10°)、缩放(0.8–2.0)、水平翻转(50% 概率)和剪切(±10°),以减少复制粘贴伪影。
- 在推理阶段,使用 BiRefNet 从参考图像中分割前景主体以生成掩码。
- 模型使用 AdamW 优化器,学习率为 1×10−5,全局批量大小为 64,遵循论文中的去噪目标进行训练。
- 视频生成采用 50 步去噪过程和 CFG 指导尺度 5.0,与 Wan2.1 设置保持一致。
方法
作者采用一种训练范式,在无需显式参考图像-视频-文本三元组的情况下模拟参考到视频的生成过程。具体而言,在训练过程中动态地从视频帧生成掩码帧,作为合成的参考输入。该方法使模型能够从多样化的真实世界视频内容中学习身份和外观的保持能力,从而规避了精心构建 R2V 数据集的局限性。
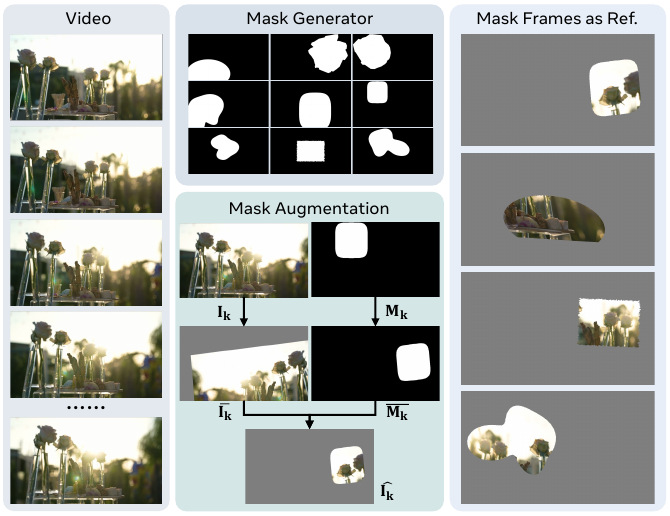
参见下图所示的掩码参考生成框架。对于从视频中随机采样的每一帧 Ik,掩码生成器会生成一个二值掩码 Mk,其前景区域比例 r∈[rmin,rmax] 可控。掩码生成器从预定义的形状类别(如椭圆、傅里叶斑点或凸/凹多边形)中选择,并通过连续尺度参数上的二分搜索来满足目标面积比例。若因像素离散化导致无法精确匹配,则应用保持拓扑结构的调整(扩张或收缩)。随后,将生成的掩码与原始帧一起进行相同的空间增强操作——包括旋转、缩放、剪切、平移和可选的水平翻转——以破坏空间对应关系,减轻复制粘贴伪影。增强后的掩码 Mˉk 被应用于增强后的帧 Iˉk,生成掩码帧 I^k=Iˉk⊙Mˉk。此过程重复执行,生成一组 K 个掩码帧 {I^k}k=1K,作为训练期间的参考条件。
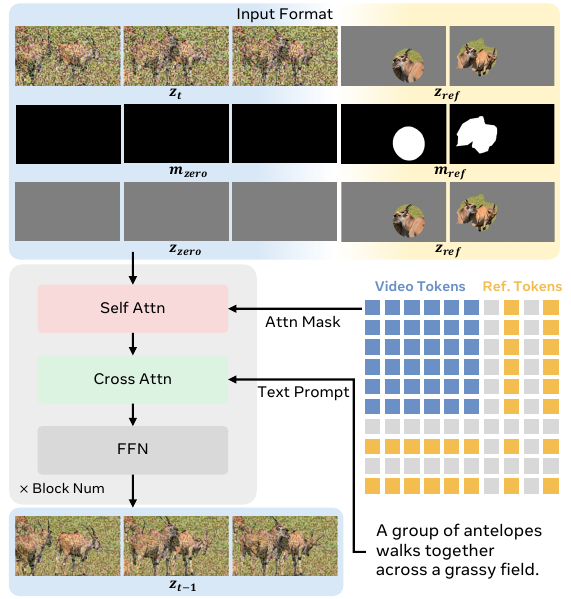
模型架构基于 Wan2.1-14B 框架,包含一个 VAE、一个 Transformer 主干网络和一个文本编码器。VAE 将目标视频和掩码参考帧分别编码至潜在空间,得到 z0 和 zref。Transformer 的输入通过将噪声视频潜在表示 zt、参考潜在表示 zref 以及对应的掩码潜在表示 mref 沿时间维度拼接而成。掩码潜在表示通过对二值掩码 Mk 缩放到潜在分辨率得到,并与零掩码 mzero 拼接,以匹配视频部分的时间长度。最终输入 zin 通过对三个部分进行通道维度拼接形成:拼接后的潜在表示、拼接后的掩码、以及拼接后的零潜在表示(用于保持条件保真度)。该输入格式定义如下:
zin=catcat[zt,zref]temporalcat[mzero,mref]temporalcat[zzero,zref]temporalchannel如下图所示,Transformer 通过一系列模块处理该输入,每个模块包含自注意力、交叉注意力和前馈网络。在自注意力中,视频和参考 token 在由缩放后的掩码 Mk 导出的注意力掩码下交互,确保仅关注有效的参考区域。随后,交叉注意力融合文本特征 zP,用文本提示引导视频 token,同时在语义上对齐参考 token。时间步 t 被注入潜在表示中以调节扩散过程。Transformer 的输出为预测的潜在表示 zt−1,由 VAE 解码生成下一视频帧。
实验
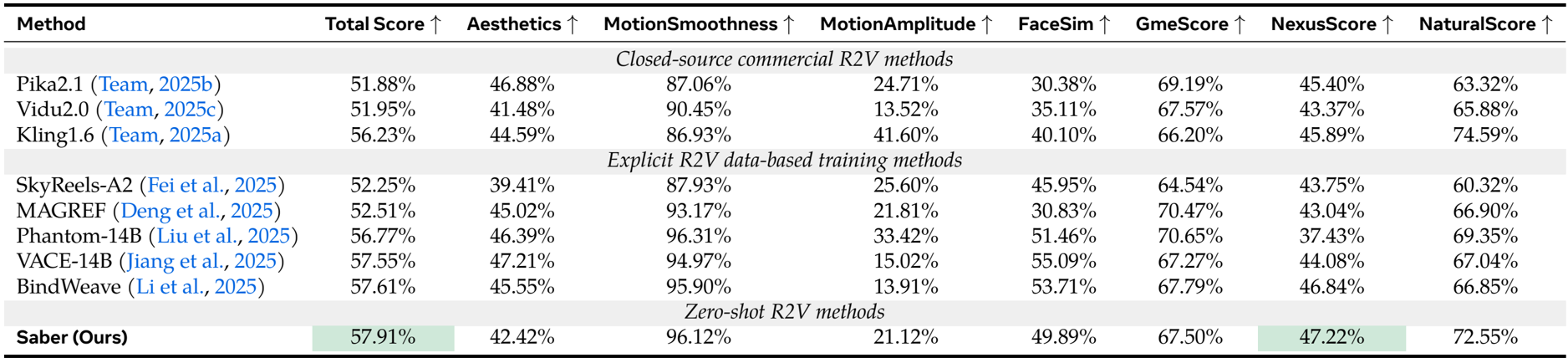
- 在 OpenS2V-Eval 基准上评估,Saber 在零样本设置下取得 57.91% 的总分,超越了闭源方法如 Kling1.6(+1.68%)以及显式训练的 R2V 模型,包括 Phantom-14B(+1.14%)、VACE-14B(+0.36%)和 BindWeave(+0.30%)。
- Saber 获得最高的 NexusScore(47.22%),分别优于 Phantom 9.79%、VACE 3.14% 和 BindWeave 0.36%,表明其在不使用专用 R2V 训练数据的情况下仍具备卓越的主体一致性。
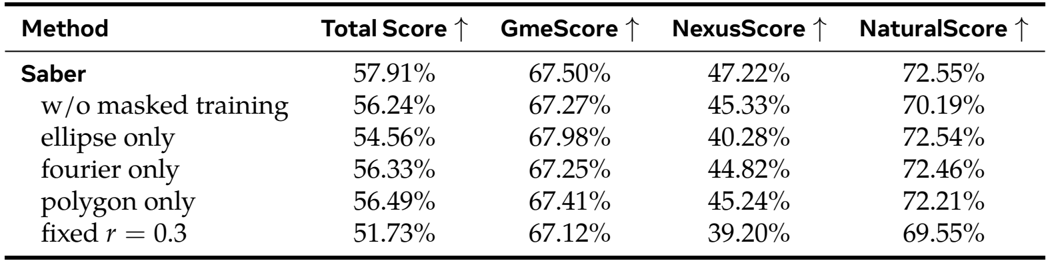
- 消融研究表明,掩码训练使总分提升 +1.67%,而多样化的掩码生成与增强对于泛化能力和自然合成至关重要,可有效减少复制粘贴伪影。
- 注意力掩码有效防止了视觉伪影,并通过限制参考-视频 token 的交互,增强了主体分离与融合效果。
- 定性结果证实,Saber 能够准确生成在单个及多个人物/物体参考下身份一致的视频,在身份保持和连贯性方面优于 Kling1.6、Phantom 和 VACE。
- 模型展现出新兴能力,包括处理单个主体的多视角输入,以及参考图像与文本提示之间的鲁棒跨模态对齐,实现精确的属性和位置控制。
作者采用基于视频-文本对的零样本方法,在 OpenS2V-Eval 基准上取得了最高的总分和 NexusScore,优于闭源模型和显式训练的 R2V 方法。结果表明,Saber 在主体一致性方面表现优异,同时在文本-视频对齐和自然性方面保持竞争力,验证了其在不依赖专用 R2V 数据集情况下的有效性。
作者在 OpenS2V-Eval 基准上评估了 Saber 的消融组件,结果显示,移除掩码训练会使总分下降 1.67%,并显著降低 NexusScore,表明主体一致性减弱。仅使用单一掩码类型或固定前景比例会降低性能,证实掩码多样性与自适应掩码对泛化能力和视频质量至关重要。